使用Python的四种机器学习技术
2020年01月27日 由 KING 发表
515382
0
机器学习回归
在一些统计书籍中,我们经常会发现回归是衡量一个变量的均值与其他值的对应值之间相互关系的量度。那么让我们讨论一下该如何看待它。
回归均值
查尔斯·达尔文的表兄弟弗朗西斯·高尔顿(Francis Galton)观察了几代豌豆的大小。他得出的结论是,自然选择将导致大小豌豆同时存在。如果我们进行定向繁殖,那么豌豆的大小就可以掌控。但是如果让豌豆自然繁殖,即使更大的豌豆也会随着时间的流逝而产生更小的后代。对于豌豆,他们具有一定的大小,但是可以将这些值映射到特定的直线或曲线。
另一个例子:猴子和股票
1973年,普林斯顿大学教授伯顿·马尔基尔(Burton Malkiel )在畅销书《华尔街的随机漫步》(A Random Walk Down Wall Street)一书中提出了自己的主张 ,并坚持认为被蒙住眼睛的猴子可以像投掷飞镖一样选择投资组合。在这类选股比赛中,猴子击败了专家。但这只是小概率事件,如果发生事件数量足够多,猴子的准确率就会下降,直到它回归到均值。

什么是机器学习回归?
在此图中,红色直线最适合点标记的所有数据。使用这条线,我们可以预测在x = 70时可以找到什么值(具有一定程度的不确定性)。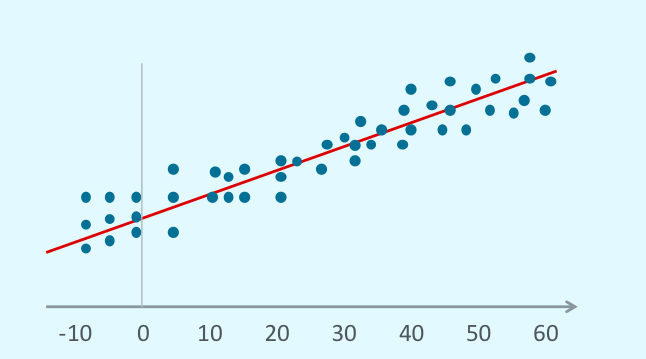 作为一种机器学习技术,回归在监督学习中找到了基础。我们用它来预测一个连续的数值目标,并从处理我们已经知道的数据集值开始。它比较已知值和预测值,并将期望值和预测值之间的差异标记为误差/残差。
作为一种机器学习技术,回归在监督学习中找到了基础。我们用它来预测一个连续的数值目标,并从处理我们已经知道的数据集值开始。它比较已知值和预测值,并将期望值和预测值之间的差异标记为误差/残差。
机器学习中的回归类型
我们通常观察到两种回归:
- 线性回归: 当我们可以用直线表示目标和预测变量之间的关系时,我们使用线性回归,如: y = P1x + P2 + e
- 非线性回归: 当我们观察到目标和预测变量之间的非线性关系时,我们不能将其表示为直线。
机器学习分类
什么是机器学习分类?
分类是一种数据挖掘技术,可让我们预测数据实例的组成员身份。这将预先使用标记的数据,并且属于监督学习。这意味着我们训练数据并期望预测其未来。所谓“预测”,是指我们将数据分类为它们可以属于的类别。我们有两种可用的属性:
分类方法
- 决策树归纳:我们从标记为tuple的类构建决策树 。它具有内部节点、分支和叶节点。内部节点表示对属性、分支,测试结果、叶节点和类标签的测试。涉及的两个步骤是学习和测试,而且很快。
- 基于规则的分类: 此分类基于一组IF-THEN规则。规则表示为:如果条件然后结论
- 通过反向传播进行分类: 神经网络学习(通常称为连接主义学习)建立连接。反向传播是最流行的一种神经网络学习算法。它迭代处理数据,并将目标值与结果进行比较以学习。
- 懒惰学习者: 在懒惰学习者方法中,机器存储训练元组并等待测试元组。这支持增量学习。这与早期学习者的方法形成对比。
ML分类示例
让我们举个例子。考虑到我们在这里教您各种代码。我们向您展示ITF条形码,Code 93条形码,QR码,Aztecs和数据矩阵等。遍历大多数示例之后,现在就轮到我们向您展示代码时,确定代码的类型了。这是有监督的学习,我们使用两个示例的一部分-培训和测试。
请注意,每种形状的某些星星如何最终出现在曲线的另一侧。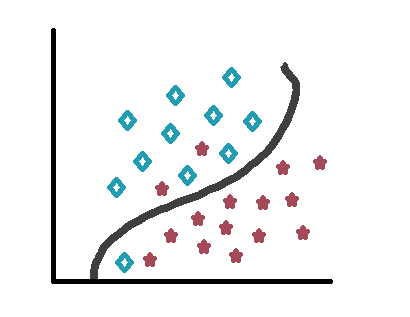
聚类
聚类是无监督的分类。这是一项探索性数据分析,没有可用的标记数据。通过聚类,我们将未标记的数据分为自然的和隐藏的有限和离散的数据结构集。我们观察到两种聚类:
- 硬群集: 一个对象属于一个群集。
- 软群集: 一个对象可能属于多个群集。
在聚类中,我们首先选择特征,然后设计聚类算法,然后验证聚类。最后,我们解释结果。
示例
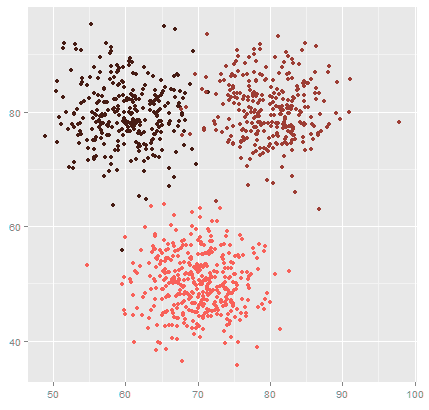
回顾上面的示例。您可以将这些代码分组在一起。QR码,Aztec和Data Matrix将在一个组中;我们可以将其称为2D代码。ITF条形码和Code 39条形码将归为“一维代码”类别。
异常检测
异常是偏离预期过程的东西。有时,借助机器学习,我们可能希望发现一个异常值。例如每小时检测一次医生账单,每位患者总计42秒。另一个办法是只在某一天找到一份特定的牙医帐单。这种情况令人怀疑,异常检测是突出显示这些异常的好方法,因为这不是我们要特别寻找的东西。





























