











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook的人工智能从视频片段中学习物理位置之间的关系
2020年01月22日 由 TGS 发表
98528
0
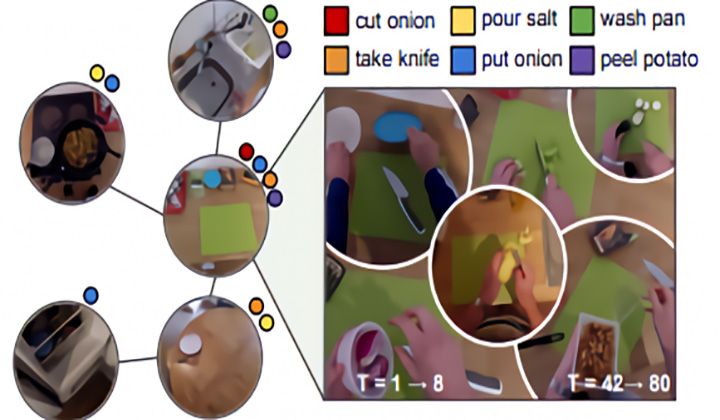 计算机视觉系统通常擅长探测物体,但却很难理解这些物体所处的环境。这是因为它们会将观察到的动作与物理环境分开——即使是那些做了模型环境的动作,也无法区分与动作相关的元素与不相关的元素,例如,柜台上的砧板与随机的地板。
计算机视觉系统通常擅长探测物体,但却很难理解这些物体所处的环境。这是因为它们会将观察到的动作与物理环境分开——即使是那些做了模型环境的动作,也无法区分与动作相关的元素与不相关的元素,例如,柜台上的砧板与随机的地板。德克萨斯大学和Facebook AI Research的研究人员在论文中描述了一种技术Ego-Topo,将视频中捕获的空间分解成活动拓扑图,然后再将视频组织成对不同区域的一系列访问。他们断言,Ego-Topo能够推断第一人称的行为,并对环境本身进行分析。
“我们的模型以往现有模型要更有优势,可以提供对过去简洁空间结构的再现。与‘纯粹的3D’方法不同,我们的地图是由人们对空间的使用有机地定义的。”研究人员在论文中解释道。
 Ego-Topo利用一个人工智能模型,从人们积极使用一个空间的视频中发现人们经常会去地方,它基于人们共享的物理空间,无论物理位置如何,都能提供跨时间链接框架。(例如,在视频开始时加载的洗碗机可能在卸载时与同一台洗碗机连接,而厨房中的垃圾桶可能与另一厨房的垃圾处理器连接。)通过一组单独的模型,利用结果图来揭示环境的可用性,并在长视频中预测未来的动作。
Ego-Topo利用一个人工智能模型,从人们积极使用一个空间的视频中发现人们经常会去地方,它基于人们共享的物理空间,无论物理位置如何,都能提供跨时间链接框架。(例如,在视频开始时加载的洗碗机可能在卸载时与同一台洗碗机连接,而厨房中的垃圾桶可能与另一厨房的垃圾处理器连接。)通过一组单独的模型,利用结果图来揭示环境的可用性,并在长视频中预测未来的动作。跨多个区域的连接空间有助于对环境及其功能的统一表示,这样自我拓扑就能分析出环境的哪些部分与人类活动相关,以及这些区域的活动如何实现特定的目标。实验中,该团队在两个关键任务上展示了自我意识:在一个新视图中推断可能的对象交互作用,并预测完成一个长期活动所需的行动,对其性能进行详细评估。
最终报告显示,与基线相比,Ego-Topo在所有预测范围内的表现都更加一致,并且它在预测未来行为方面表现出色。此外,将动作与模型拓扑图中发现的区域相连接会导致一致性的改进,与此同时,基于合并图中的函数对齐,空间也会导致一致性的改进。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消