Facebook AI实现了107倍的虚拟代理培训速度
2020年01月22日 由 KING 发表
904220
0
AI社区的长期目标是构建与物理世界有效交互的智能机器,而关键的挑战是教会这些系统在复杂、陌生的现实环境中导航,以到达指定的目的地,而无需提供预先准备的地图。Facebook AI宣布,他们创建了一种新的大规模分布式强化学习(RL)算法,称为DD-PPO,该算法仅使用RGB-D摄像头、GPS和指南针数据就有效地解决了目标球导航的任务。经过DD-PPO培训的代理(代表分散式分布式近端策略优化)在各种虚拟环境(例如房屋和办公楼)中取得了近100%的成功。
地图是有时效性的,现实世界无时无刻不在发生变化。通过学习在没有地图的情况下进行导航,受DD-PPO训练的代理将加速为现实世界创建新的AI应用程序。 以前的系统在这些任务上的成功率达到了92%,但是在现实世界中,即使失败100次,也无法成功1次。在这种情况下,机器代理可能会因出错而损坏自身或周围环境。接受DD-PPO培训的代理在99.9%的时间内达到了目标。更令人印象深刻的是,它们以接近最大的效率进行操作,选择的路径与从起点到目标的最短路径匹配的平均误差在3%以内。而且它们没有任何类型的错误的余地,在十字路口不能转错弯,不能走进死胡同中,不能从最直接的路径进行任何改变或偏离。他们认为,代理可以学习利用实际室内环境(公寓、房屋和办公室)也存在于他们的数据集中。DD-PPO系统以及Facebook AI开放源代码的最新速度和逼真度提供了这种改进的性能。
以前的系统在这些任务上的成功率达到了92%,但是在现实世界中,即使失败100次,也无法成功1次。在这种情况下,机器代理可能会因出错而损坏自身或周围环境。接受DD-PPO培训的代理在99.9%的时间内达到了目标。更令人印象深刻的是,它们以接近最大的效率进行操作,选择的路径与从起点到目标的最短路径匹配的平均误差在3%以内。而且它们没有任何类型的错误的余地,在十字路口不能转错弯,不能走进死胡同中,不能从最直接的路径进行任何改变或偏离。他们认为,代理可以学习利用实际室内环境(公寓、房屋和办公室)也存在于他们的数据集中。DD-PPO系统以及Facebook AI开放源代码的最新速度和逼真度提供了这种改进的性能。
适用于大规模分布式环境的高效RL
深度RL的最新进展催生了可以在各种游戏中胜过人类的系统。这些进步依赖于大量的训练样本,如果不进行大规模,分布式的并行化,则使它们不切实际。
一些工作已经应用于分布式RL的系统。从较高的层次上讲,这些工作利用了两个显着的组件:收集经验的GPU和优化模型的参数服务器。
Facebook认为这种范例(一个参数服务器和数千个GPU)可能根本不符合现代计算机视觉和机器人社区的需求。具体而言,在过去的几年中,大量的视觉和机器人技术工作提出了在丰富的3D模拟器(例如Facebook AI的开源AI Habitat)中训练虚拟机器人(通常称为嵌入式代理)的方法。与Gym或Atari不同,3D模拟器需要GPU加速,这极大地限制了工作人员的数量。所需的代理从高维输入(像素)进行操作,并使用诸如ResNet50之类的深层网络,这会对参数服务器造成压力。因此,现有的分布式RL架构无法扩展,并且需要开发新的分布式架构。
提供近乎线性的缩放
Facebook提出了一种可扩展的简单、同步、分布式RL方法。他们将这种方法称为分散式分布式近端策略优化,因为它是分散(没有参数服务器)和分布式的(在许多不同的机器上运行),并且他们使用它来扩展近端策略优化,这是一种先前开发的技术。在DD-PPO中,每个GPU交替进行,在资源密集,GPU加速的模拟环境中收集经验,然后优化模型。这种分布是同步的-在一个明确的交流阶段,GPU将其更新同步到模型。
体验收集运行时的可变性给在RL中使用此方法提出了挑战。在监督学习中,所有梯度计算大约需要相同的时间。在RL中,某些资源密集型环境可能需要更长的时间才能进行仿真。由于每个GPU都必须等待最慢的时间才能完成收集体验,因此这会带来大量的同步开销。为了解决这个问题,他们引入了抢占阈值,一旦这些百分比降低,这些散布者的推出收集阶段就被迫提前结束其他GPU已完成其发布,从而显着提高了规模。系统平均权衡所有GPU对损失的贡献,并在抢占前将最小步骤数限制为最大步骤的四分之一,以确保所有环境都有助于学习。
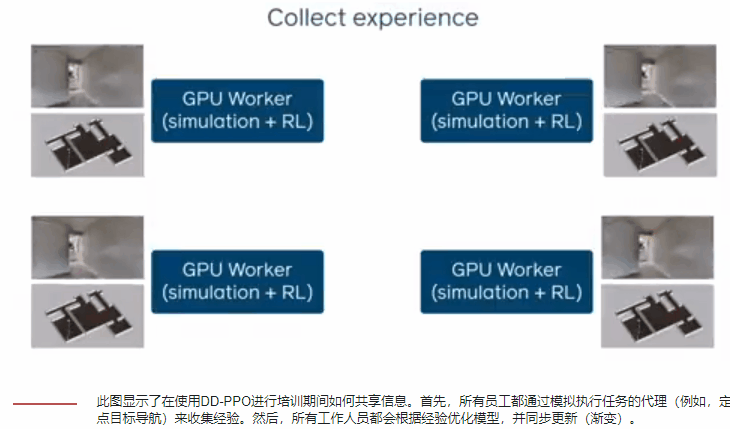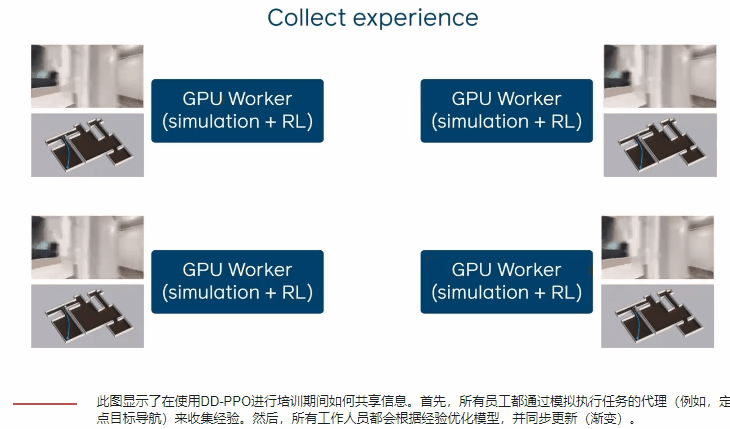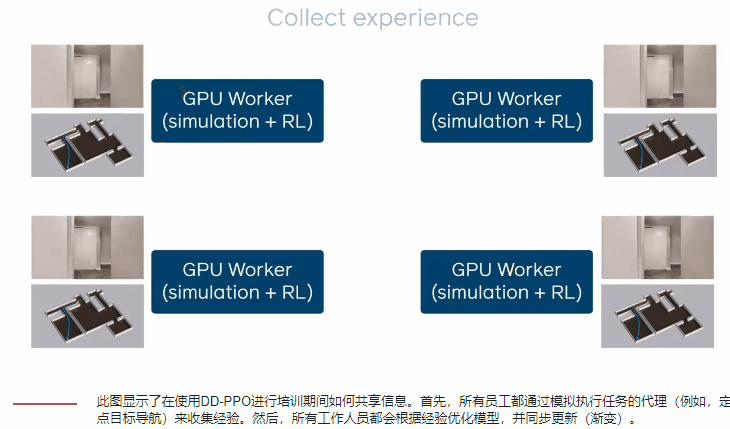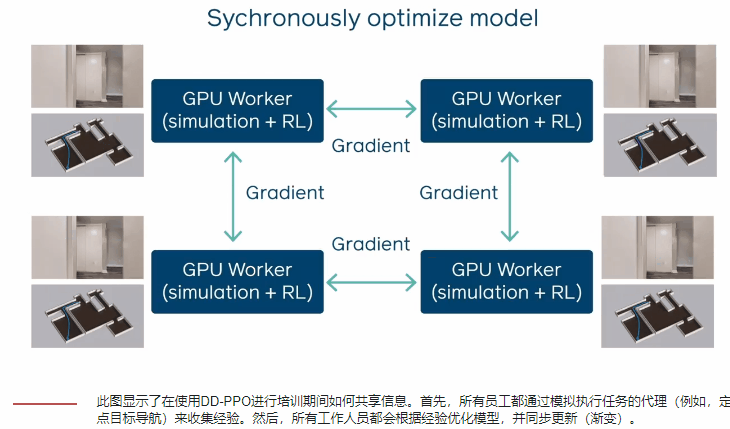
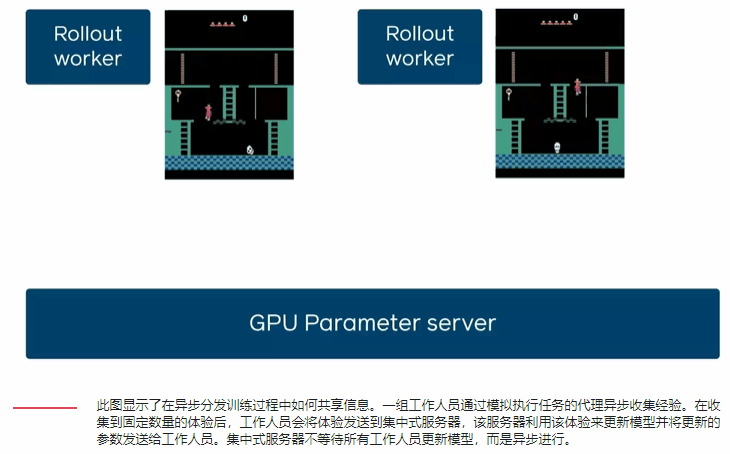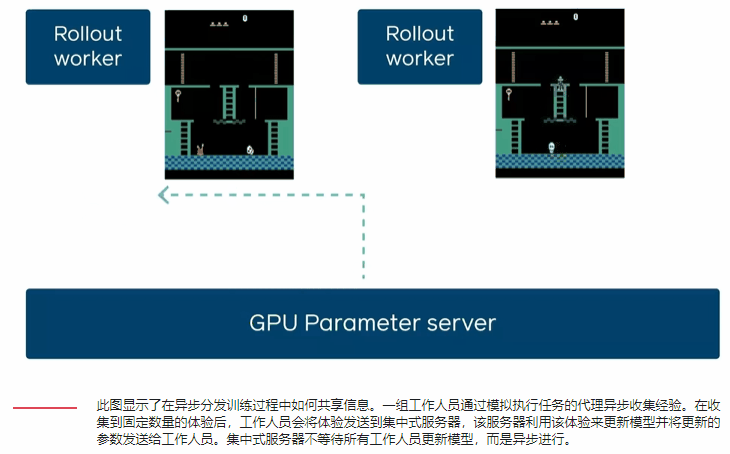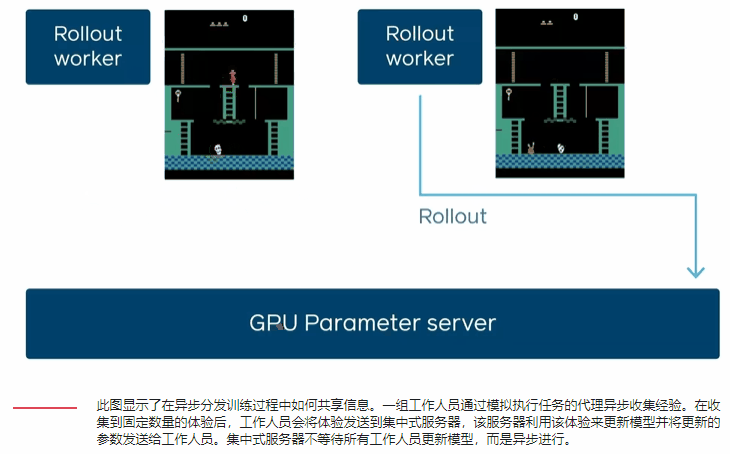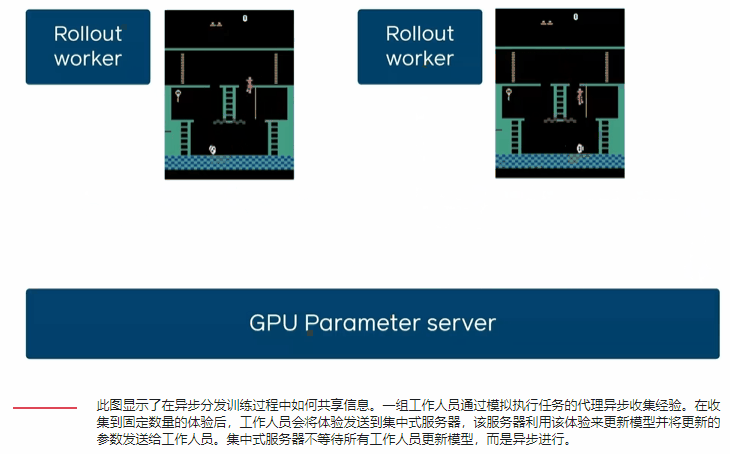
通过每秒N个GPU相对于一个GPU的经验步骤来表征DD-PPO的规模。他们考虑了两种不同的工作负载:一种工作负载的模拟时间在所有环境下大致相等,另一种工作负载的模拟时间由于环境复杂性的巨大差异而有很大差异。
在这两种工作负载下DD-PPO具有近乎线性的缩放比例-通过串行实现在128个GPU上实现了107倍的加速。
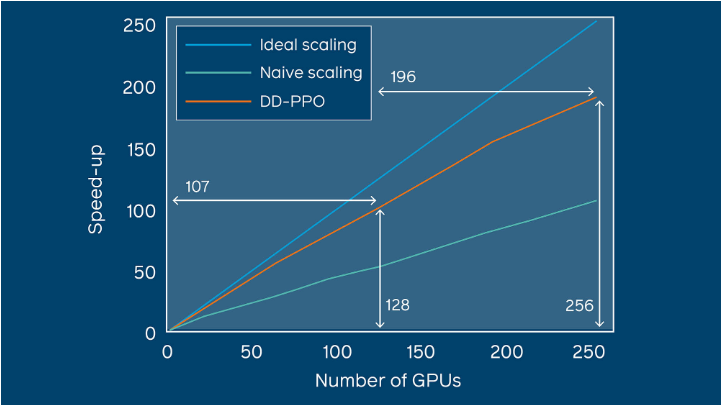
随着GPU的数量从一增加到250,DD-PPO表现出近乎线性的缩放比例。
利用DD-PPO实现近乎完美的目标飞行
他们使用AI Habitat平台对DD-PPO进行了培训和评估。人居是具有高性能和稳定模拟器的模块化框架,使其成为模拟数十亿步经验的理想框架。栖息地以每秒10K帧(多进程)的速度运行,并且可以处理多种数据集,包括Replica,这是目前可用的最真实的AI研究虚拟环境。他们对副本服务器以及Gibson数据集中的数百个场景进行了实验。 在定点目标导航中,业务代表会在新环境中的随机起始位置和方向上初始化,并被要求导航到相对于业务代表位置指定的目标坐标。没有可用的地图,代理必须仅使用其传感器-GPS + Compass(以提供其相对于起点的当前位置和方向)以及RGB-D或RGB摄像机进行导航。
在定点目标导航中,业务代表会在新环境中的随机起始位置和方向上初始化,并被要求导航到相对于业务代表位置指定的目标坐标。没有可用的地图,代理必须仅使用其传感器-GPS + Compass(以提供其相对于起点的当前位置和方向)以及RGB-D或RGB摄像机进行导航。
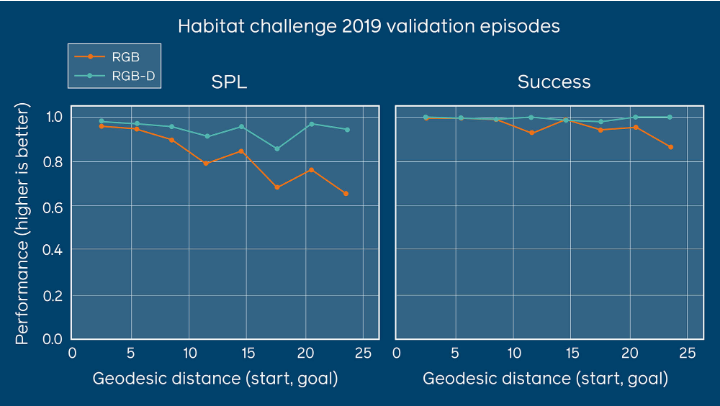
该图显示,即使距目标的距离增加,配备RGB-D的代理仍继续表现良好。如果仅配备RGB摄像机,则代理的性能在25米以上的距离上会下降。SPL是指通过归一化的反向路径长度(大致为代理路径的效率)加权的成功率。
他们使用DD-PPO训练了25亿步的点目标导航代理(相当于80年的人类经验)。这代表了超过六个月的GPU时间培训,但是他们在不到三天的时间里使用64个GPU完成了培训。作为比较,以前的方法,例如Savva等人开发的方法,将需要一个月以上的挂钟时间。
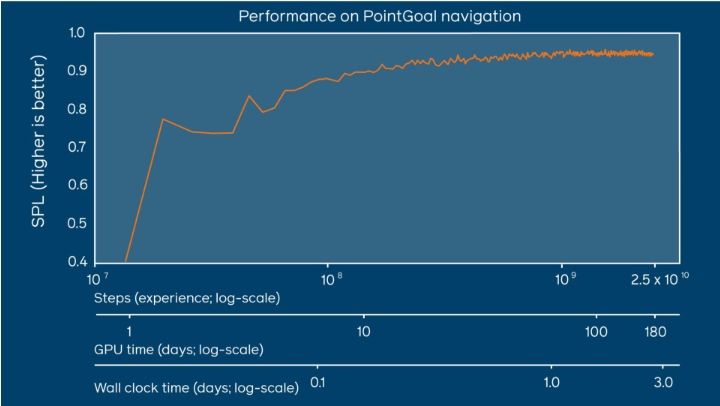
随着培训接近25亿步经验,绩效持续提高。此处的结果是通过SPL来衡量的,SPL是指通过归一化的反向路径长度加权的成功率。
此外,他们的结果表明,代理(带有RGB-D和GPS +罗盘传感器)的性能在10亿步之前不会饱和,这表明以前的研究还不够完善一到两个数量级。幸运的是,误差与计算之间呈现出幂律分布,其中90%的峰值性能是在相对较早(1亿步)的情况下获得的,而计算资源却相对较少(一天有8个GPU)。
达到数十亿级的经验,不仅为2019年人居自主航行挑战赛奠定了最先进的技术,而且从根本上解决了这一任务。在SPL效率指标上,它的成功率为99.9%,得分为96.9%。(SPL是指通过归一化的反向路径长度加权的成功率。)
应对智能导航中的下一个挑战
要完成学习如何在具有挑战性的现实环境中导航以完成复杂任务的机器,还有许多工作要做。他们期待探索仅RGB点目标导航的新解决方案,这一点非常重要,因为指南针和GPS数据可能嘈杂,或者根本无法在室内使用。他们还将DD-PPO训练的模型应用于不同的任务。
他们的模型能够快速学习新任务(优于ImageNet预先训练的CNN),并可用作近乎完美的神经目标控制器(用于其他高级导航任务的通用资源,例如最大程度地增加代理到起点的距离) 。他们希望以此工作为基础,创建执行更多语义,更高级别任务的系统,例如ObjectNav(“转到椅子”),跟随指令的指令(“走出房间,向左转,沿着走廊往上走”楼梯,然后停在桌子前”),具体问题解答 (“我的笔记本电脑在我的桌子上吗?”),并最终响应“将我的笔记本电脑从我的桌子上拿来我的笔记本电脑”之类的请求来操作对象。他们还将继续进行工作,将这些代理从模拟转移到现实的机器人代理,例如使用Facebook AI的PyRobot框架的LoCoBots。
该团队表示,他们希望通过创建仅使用摄像机输入而无需罗盘或GPS数据即可完成点目标导航的系统,来巩固DD-PPO的成功。
代码传送门:https://github.om/facebookresearch/habitat-api/pull/245





























