











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在AWS上使用MXNet和TensorFlow进行分布式深度学习
2017年08月26日 由 yuxiangyu 发表
354220
0
AWS CloudFormation通过模板创建和配置Amazon的Web服务器环境,简化了分布式深度学习集群的设置过程。AWS CloudFormation深度学习模板使用Amazon Deep Learning AMI(提供MXNet,TensorFlow,Caffe,Theano,Torch和CNTK框架)来启动EC2实例集群和其他AWS执行所需的分布式深度学习。
通过这个模板,我们继续致力于使分布式深入学习变得更容易。AWS CloudFormation创建客户帐户所有环境。
我们更新了AWS CloudFormation深度学习模板,以增加一些不错的功能和特征。
以下架构图显示了EC2集群基础架构。
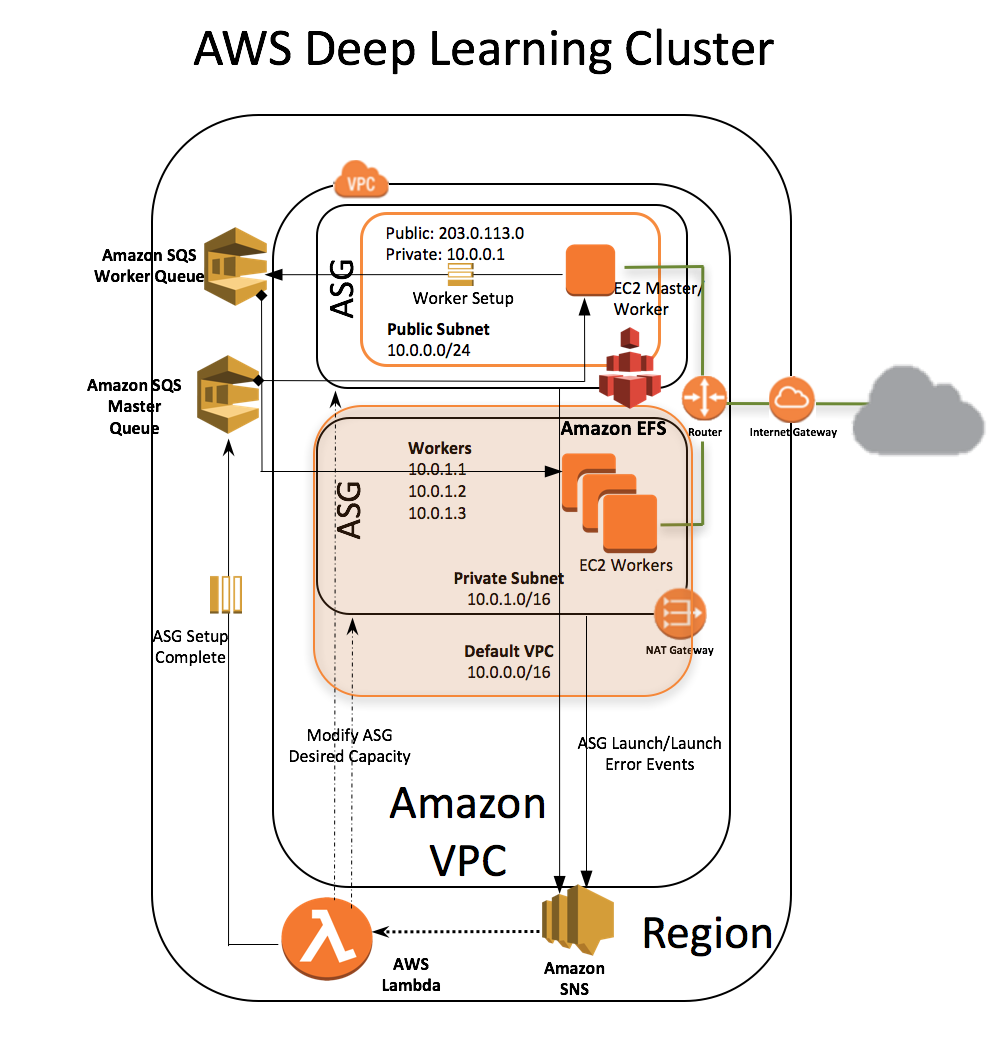
亚马逊深度学习模板创建一个包含以下资源的堆栈:
启动脚本可以在所有主机上授权SSH转发。授权SSH代理转发是非常重要的,因为诸如MXNet这样的框架在分布式训练期间使用SSH进行主实例和工作实例之间的通信。
主实例的启动脚本查看主SQS队列以确认自动缩放设置是否完成。Lambda函数发送两个信息,一个在主自动缩放组被成功建立时发送,另一个是当请求的容量满足或实例在worker自动缩放组上启动失败时发送。当实例在worker自动缩放组上启动失败时,Lambda函数将修改实例数量的期望容量直到成功启动。
在Amazon SQS主队列上收到消息后,主实例上的安装脚本会配置所有必需的worker元数据(工作人员的IP地址,GPU计数等),并在worker的SQS队列上广播元数据。收到此消息后,在worker的启动脚本上轮询SQS的worker队列,配置在worker上的元数据。
正在轮询SQS工作队列的worker实例上的启动脚本将在worker上配置此元数据。
在所有实例上设置以下环境变量:
要建立一个深度学习的AWS CloudFormation堆栈,请参考Using the AWS CloudFormation Deep Learning Template。
为了演示如何使用MXNet和Tensorflow框架运行分布式训练,我们使用标准CIFAR-10模型。CIFAR-10是一个足够复杂的网络,受益于分布式设置,可以在这样的设置下进行快速的训练。
按照步骤3进行,Using the AWS CloudFormation Deep Learning Template。
注意:这可能需要几分钟时间。
以下示例展示如何使用MXNet上的数据并行运行CIFAR-10。请注意使用DEEPLEARNING_ *环境变量。
我们能够在25分钟内对2个P2.8x EC2实例进行100个周期的训练,训练精准度达到了92%。
这些步骤总结了如何开始。获取更多有关在MXNet上运行分布式训练的信息,请参阅Run MXNet on Multiple Devices。
新的模板引入了亚马逊弹性文件系统,便于在worker之间共享数据,将检查点和所有TensorFlow进程的日志存储在一个地方。你现在可以监视主实例上的所有日志。
对于TensorFlow分布式训练示例,我们使用TensorFlow提供的CIFAR-10模型和分布式Tensorflow中讨论的分布式训练样本代码。
需要注意的是,此分布式训练示例未达到最高精度。只是展示了深入学习的AWS CloudFormation栈如何简化运行分布式TensorFlow培训。
从Alex Krizhevsky的页面下载CIFAR-10数据集, 并将tar.gz文件解压缩到EFS mount上,这样你不必在所有worker上复制或下载数据集。
我们在awslabs / deeplearning-cfn报告中添加了一个脚本,生成的脚本用于在实例上运行tensorflow的worker和参数服务器的命令。这个脚本将training_script作为参数,如果需要也可以将分布式训练脚本所需的参数作为额外的参数传递。
停止可能在worker上运行的所有Python进程:
对所有worker进行分布式训练:
因为所有worker的日志和经过特殊处理的状态进程都存储在Amazon EFS上,你现在可以在主控端上监视它们:
我们可以在2个P2.8x EC2实例中运行2个特殊处理的状态进程和16个worker进程,在一个小时内训练这个模型,为20万个步数,并将16个worker的平均损失减至0.82。
在训练模型上运行评估脚本使准确度达到77%:
你可以通过在主节点上运行以下命令来可视化TensorBoard上的训练。TensorBoard在主实例和端口6006的私有IP地址上开始运行。记下该IP地址,因为你在下一个命令中还会用到。
现在使用SSH端口映射来查看本地计算机上的TensorBoard。在本地计算机上运行类似于以下命令。
要查看TensorBoard,请在浏览器上打开http:// localhost:6006。有关更多信息,请参阅TensorBoard:可视化学习。
通过这个模板,我们继续致力于使分布式深入学习变得更容易。AWS CloudFormation创建客户帐户所有环境。
更新了些什么
我们更新了AWS CloudFormation深度学习模板,以增加一些不错的功能和特征。
- 我们通过自动化增强了AWS CloudFormation深度学习模板,即使所提供的工作实例数量低于所需的数量,也可以继续创建堆栈。在先前版本的模板中,如果其中一个工作实例没有配置成功,例如,如果帐户限制,则AWS CloudFormation将回滚该堆栈,并要求你调整所需的数并重新启动堆栈创建过程。新模板包含一个自动调整倒计时并着手建立其余的群集(堆栈)的函数
- 我们现在支持创建一个CPU Amazon EC2实例类型的集群。
- 我们还为使用该模板创建的群集添加了Amazon Elastic File System(Amazon EFS)支持。
- Amazon EFS在启动过程中自动安装在所有工作实例上。
- Amazon EFS允许通过工作实例共享代码,数据和结果。
- 使用Amazon EFS不会降低压缩比高的文件的性能(例如,包含图像数据的.rec文件)。
- 我们现在支持创建一个运行Ubuntu的实例集群。请参阅 Ubuntu Deep Learning AMI。
EC2集群架构
以下架构图显示了EC2集群基础架构。
亚马逊深度学习模板创建一个包含以下资源的堆栈:
- 客户帐户中的VPC。
- VPC内自动缩放组中所请求数量或可用数量的worker实例。这些实例在私有子网中启动。
- 独立的自动缩放组中的主实例的动作作为代理支持与SSH集群连通。AWS CloudFormation将此实例放置在VPC中,并将其连接到公共和私有子网。此实例具有公共的IP地址和DNS。
- 以通用性能模式配置的Amazon EFS文件存储系统。
- 在实例上安装Amazon EFS的安装目标。
- 允许外部SSH访问主实例的安全组。
- 安全组允许主实例和worker实例通过NFS端口2049安装和访问Amazon EFS。
- 主实例和worker实例之间的通信可以在私有子网上打开端口的两个安全组。
- 一个AWS身份和访问管理(IAM)任务,允许实例调查Amazon Simple Queue Service (Amazon SQS)并且可以访问和查询自动缩放组和EC2实例的私有IP地址。
- VPC内的实例使用的NAT网关与外部连接。
- 两个亚马逊SQS队列在主实例和worker实例的启动时配置元数据。
- 一个AWS Lambda功能,用于监视Auto Scaling组的启动活动,并根据可用性修改自动缩放组的所需容量。
- Amazon Simple Notification Service (Amazon SNS)的一般规则是触发自动缩放事件的Lambda函数。
- AWS CloudFormation WaitCondition和WaitHandler,堆栈创建暂停55分钟,以完成元数据设置。
深度学习模板的工作原理
启动脚本可以在所有主机上授权SSH转发。授权SSH代理转发是非常重要的,因为诸如MXNet这样的框架在分布式训练期间使用SSH进行主实例和工作实例之间的通信。
主实例的启动脚本查看主SQS队列以确认自动缩放设置是否完成。Lambda函数发送两个信息,一个在主自动缩放组被成功建立时发送,另一个是当请求的容量满足或实例在worker自动缩放组上启动失败时发送。当实例在worker自动缩放组上启动失败时,Lambda函数将修改实例数量的期望容量直到成功启动。
在Amazon SQS主队列上收到消息后,主实例上的安装脚本会配置所有必需的worker元数据(工作人员的IP地址,GPU计数等),并在worker的SQS队列上广播元数据。收到此消息后,在worker的启动脚本上轮询SQS的worker队列,配置在worker上的元数据。
正在轮询SQS工作队列的worker实例上的启动脚本将在worker上配置此元数据。
在所有实例上设置以下环境变量:
- $ DEEPLEARNING_WORKERS_PATH:包含工作者列表的文件路径
- $ DEEPLEARNING_WORKERS_COUNT:worker的总数
- $ DEEPLEARNING_WORKER_GPU_COUNT:实例中的GPU数量
- $ EFS_MOUNT:安装Amazon EFS的目录
设置深度学习堆栈
要建立一个深度学习的AWS CloudFormation堆栈,请参考Using the AWS CloudFormation Deep Learning Template。
运行分布式训练
为了演示如何使用MXNet和Tensorflow框架运行分布式训练,我们使用标准CIFAR-10模型。CIFAR-10是一个足够复杂的网络,受益于分布式设置,可以在这样的设置下进行快速的训练。
登录到主实例
按照步骤3进行,Using the AWS CloudFormation Deep Learning Template。
将包含示例的awslabs / deeplearning-cfn报告拷贝到EFS mount上
注意:这可能需要几分钟时间。
git clone https://github.com/awslabs/deeplearning-cfn $EFS_MOUNT/deeplearning-cfn && \
cd $EFS_MOUNT/deeplearning-cfn && \
#
#fetches dmlc/mxnet and tensorflow/models repos as submodules
git submodule update --init $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/models && \
git submodule update --init $EFS_MOUNT/deeplearning-cfn/examples/mxnet && \
cd $EFS_MOUNT/deeplearning-cfn/examples/mxnet/ && \
git submodule update --init $EFS_MOUNT/deeplearning-cfn/examples/mxnet/dmlc-core
在MXNet上运行分布式训练
以下示例展示如何使用MXNet上的数据并行运行CIFAR-10。请注意使用DEEPLEARNING_ *环境变量。
#terminate all running Python processes across workers
while read -u 10 host; do ssh -o "StrictHostKeyChecking no" $host "pkill -f python" ; \
done 10<$DEEPLEARNING_WORKERS_PATH
#navigate to the MXNet image-classification example directory \
cd $EFS_MOUNT/deeplearning-cfn/examples/mxnet/example/image-classification/
#run the CIFAR10 distributed training example \
../../tools/launch.py -n $DEEPLEARNING_WORKERS_COUNT -H $DEEPLEARNING_WORKERS_PATH \
python train_cifar10.py --gpus $(seq -s , 0 1 $(($DEEPLEARNING_WORKER_GPU_COUNT - 1))) \
--network resnet --num-layers 50 --kv-store dist_device_sync
我们能够在25分钟内对2个P2.8x EC2实例进行100个周期的训练,训练精准度达到了92%。
这些步骤总结了如何开始。获取更多有关在MXNet上运行分布式训练的信息,请参阅Run MXNet on Multiple Devices。
在TensorFlow上运行分布式训练
新的模板引入了亚马逊弹性文件系统,便于在worker之间共享数据,将检查点和所有TensorFlow进程的日志存储在一个地方。你现在可以监视主实例上的所有日志。
对于TensorFlow分布式训练示例,我们使用TensorFlow提供的CIFAR-10模型和分布式Tensorflow中讨论的分布式训练样本代码。
需要注意的是,此分布式训练示例未达到最高精度。只是展示了深入学习的AWS CloudFormation栈如何简化运行分布式TensorFlow培训。
从Alex Krizhevsky的页面下载CIFAR-10数据集, 并将tar.gz文件解压缩到EFS mount上,这样你不必在所有worker上复制或下载数据集。
mkdir $EFS_MOUNT/cifar10_data && \
wget http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz --directory-prefix=$EFS_MOUNT/cifar10_data \
&& tar -xzvf $EFS_MOUNT/cifar10_data/cifar-10-binary.tar.gz -C $EFS_MOUNT/cifar10_data
我们在awslabs / deeplearning-cfn报告中添加了一个脚本,生成的脚本用于在实例上运行tensorflow的worker和参数服务器的命令。这个脚本将training_script作为参数,如果需要也可以将分布式训练脚本所需的参数作为额外的参数传递。
cd $EFS_MOUNT/deeplearning-cfn/examples/tensorflow && \
# generates commands to run workers and parameter-servers on all the workers \
python generate_trainer.py --workers_file_path $DEEPLEARNING_WORKERS_PATH \
--worker_count $DEEPLEARNING_WORKERS_COUNT \
--worker_gpu_count $DEEPLEARNING_WORKER_GPU_COUNT \
--trainer_script_dir $EFS_MOUNT/deeplearning-cfn/examples/tensorflow \
--training_script $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/cifar10_multi_machine_train.py \
--batch_size 128 --data_dir=$EFS_MOUNT/cifar10_data \
--train_dir=$EFS_MOUNT/deeplearning-cfn/examples/tensorflow/train \
--log_dir $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/logs \
--max_steps 200000停止可能在worker上运行的所有Python进程:
#terminate all running Python processes across workers \
while read -u 10 host; do ssh -o "StrictHostKeyChecking no" $host "pkill -f python" ; \
done 10<$DEEPLEARNING_WORKERS_PATH
对所有worker进行分布式训练:
trainer_script_dir=$EFS_MOUNT/deeplearning-cfn/examples/tensorflow && while read -u 10 host; \
do ssh -o "StrictHostKeyChecking no" $host "bash $trainer_script_dir/$host.sh" ; \
done 10<$DEEPLEARNING_WORKERS_PATH
因为所有worker的日志和经过特殊处理的状态进程都存储在Amazon EFS上,你现在可以在主控端上监视它们:
tail -f $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/logs/*
我们可以在2个P2.8x EC2实例中运行2个特殊处理的状态进程和16个worker进程,在一个小时内训练这个模型,为20万个步数,并将16个worker的平均损失减至0.82。
在训练模型上运行评估脚本使准确度达到77%:
python $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/models/tutorials/image/cifar10/cifar10_eval.py \
--data_dir=$EFS_MOUNT/cifar10_data/ \
--eval_dir=$EFS_MOUNT/deeplearning-cfn/examples/tensorflow/eval \
--checkpoint_dir=$EFS_MOUNT/deeplearning-cfn/examples/tensorflow/train你可以通过在主节点上运行以下命令来可视化TensorBoard上的训练。TensorBoard在主实例和端口6006的私有IP地址上开始运行。记下该IP地址,因为你在下一个命令中还会用到。
tensorboard --logdir $EFS_MOUNT/deeplearning-cfn/examples/tensorflow/train
现在使用SSH端口映射来查看本地计算机上的TensorBoard。在本地计算机上运行类似于以下命令。
#In this example, 192.0.2.0 is the private IP of the master and 203.0.113.0 is the public ip of the master instance, ec2-user is the userid of the master if Instance Type is Amazon Linux
ssh -l ec2-user -L 6006:192.0.2.0:6006 203.0.113.0
要查看TensorBoard,请在浏览器上打开http:// localhost:6006。有关更多信息,请参阅TensorBoard:可视化学习。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消