











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌紧随OpenAI之后,对其新的PaLM 2 AI程序几乎只字不提
2023年05月17日 由 daydream 发表
263067
0
跟OpenAI一样,这家搜索引擎巨头正在逆转几十年来在AI研究领域的开放发布。
一年前,当谷歌人工智能科学家公布了一个重要的新项目——路径语言模型(Pathways Language Model, PaLM)时,他们在一篇技术论文中花了几百字来描述用于实现该项目的重要新人工智能技术。

上周,在介绍PaLM的继任者PaLM 2时,谷歌几乎没有透露任何信息。在这份长达92页的“技术报告”后面的附录中,谷歌的学者们非常简要地描述了他们这次不会告诉世界任何事情的原因:
PaLM-2是一种新的最先进的语言模型。我们有小型、中型和大型变体,它们使用基于Transformer架构的堆叠层,根据模型大小不同,参数也不同。关于模型尺寸和体系结构的更多细节不对外公布。
故意拒绝披露PaLM 2的所谓架构——程序的构建方式——不仅与之前的PaLM论文不同,而且与整个人工智能发布历史不同,后者主要基于开源软件代码,并且通常包括有关程序架构的大量细节。
这一转变显然是对谷歌最大竞争对手之一OpenAI的回应。今年4月,OpenAI拒绝透露其最新“生成式人工智能”项目GPT-4的细节,震惊了研究界。杰出的人工智能学者警告说,OpenAI的这一令人惊讶的选择可能会对整个行业的披露产生寒蝉效应,而PaLM 2的论文是他们观点可能正确的第一个重大迹象。
与GPT-4一样,PaLM 2是一个生成式人工智能程序,可以根据提示生成文本簇,从而执行问答和软件编码等多项任务。
与OpenAI一样,谷歌也在改变几十年来人工智能研究领域的公开。这是谷歌2017年的一篇研究论文,“注意力就是你所需要的”,详细揭示了一个名为The Transformer的突破性项目。该程序很快被人工智能研究界和工业界采用,用于开发自然语言处理程序。
OpenAI在秋季推出了ChatGPT程序,该程序引发了全球对ChatGPT的兴奋。
包括Ashish Vaswani在内的原始论文的作者均未被列入PaLM 2的作者名单。
因此,从某种意义上说,通过在一段话中披露PaLM 2是The Transformer的后代,并拒绝透露其他任何信息,该公司的研究人员明确了他们对该领域的贡献以及他们结束分享突破性研究传统的意图。
他们写道,通过找到与训练数据量相关的程序大小的适当平衡,作者能够使PaLM 2程序节食,因此程序本身比原始PaLM程序小得多。考虑到人工智能的趋势最近朝着相反的方向发展,规模越来越大,这似乎意义重大。
正如作者所写,
PaLM 2 系列中最大的模型 PaLM 2-L 明显小于最大的 PaLM 模型,但使用更多的训练计算。我们的评估结果表明,PaLM 2 模型在各种任务(包括自然语言生成、翻译和推理)上都明显优于 PaLM。这些结果表明,模型缩放并不是提高性能的唯一方法。相反,可以通过细致的数据选择和高效的架构/目标来解锁性能。此外,更小但质量更高的模型可显著提高推理效率,降低服务成本,并使模型的下游应用程序可供更多应用程序和用户使用。
PaLM 2 的作者说,在程序大小和训练数据量的平衡之间有一个最佳平衡点。与PaLM相比,PaLM 2程序在基准测试中的准确性显着提高,正如作者在单个表格中概述的那样:
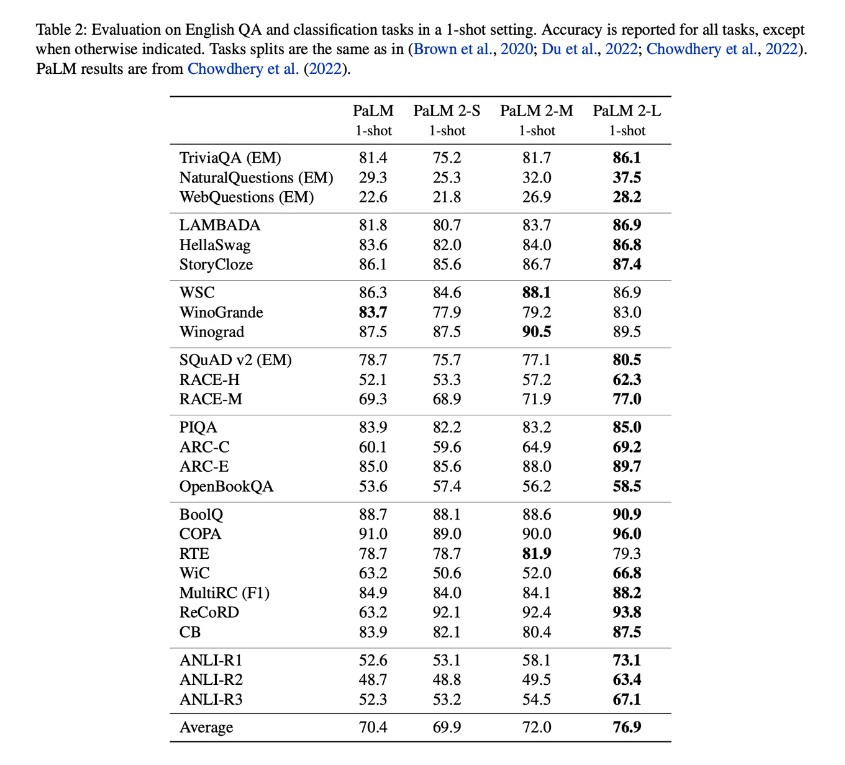
通过这种方式,他们正在建立对过去两年人工智能项目规模的实际研究的观察。
例如,乔丹·霍夫曼(Jordan Hoffman)及其同事去年在谷歌的DeepMind上广泛引用的一项工作创造了所谓的Chinchilla经验法则,即如何平衡训练数据量和程序大小的公式。
PaLM 2科学家提出的数字与霍夫曼及其团队略有不同,但它验证了该论文所说的话。他们在单个缩放表中与Chinchilla的工作正面展示他们的结果:
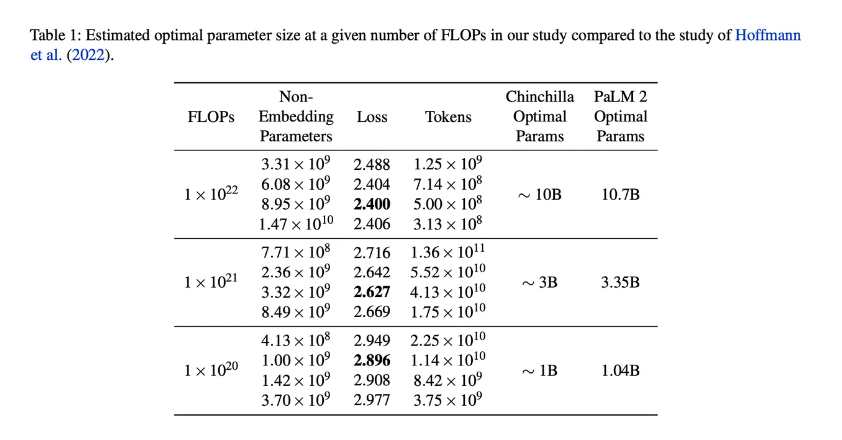
这一观点与一些年轻公司的努力是一致的,例如位于旧金山、成立三年的人工智能初创公司Snorkel,该公司于11月推出了标记培训数据的工具。Snorkel的前提是,更好地管理数据可以减少一些需要进行的计算。
这种聚焦于一个最优点的方式有点偏离最初的PaLM。通过该模型,谷歌强调了该项目的培训规模,指出这是“迄今为止用于培训的最大的基于TPU的系统配置”,指的是谷歌的TPU计算机芯片。
尽管在新的PaLM 2作品中透露的很少,但你可以说它确实证实了为了尺寸而从尺寸转向更深思熟虑的规模和能力处理的趋势。
一年前,当谷歌人工智能科学家公布了一个重要的新项目——路径语言模型(Pathways Language Model, PaLM)时,他们在一篇技术论文中花了几百字来描述用于实现该项目的重要新人工智能技术。
上周,在介绍PaLM的继任者PaLM 2时,谷歌几乎没有透露任何信息。在这份长达92页的“技术报告”后面的附录中,谷歌的学者们非常简要地描述了他们这次不会告诉世界任何事情的原因:
PaLM-2是一种新的最先进的语言模型。我们有小型、中型和大型变体,它们使用基于Transformer架构的堆叠层,根据模型大小不同,参数也不同。关于模型尺寸和体系结构的更多细节不对外公布。
故意拒绝披露PaLM 2的所谓架构——程序的构建方式——不仅与之前的PaLM论文不同,而且与整个人工智能发布历史不同,后者主要基于开源软件代码,并且通常包括有关程序架构的大量细节。
这一转变显然是对谷歌最大竞争对手之一OpenAI的回应。今年4月,OpenAI拒绝透露其最新“生成式人工智能”项目GPT-4的细节,震惊了研究界。杰出的人工智能学者警告说,OpenAI的这一令人惊讶的选择可能会对整个行业的披露产生寒蝉效应,而PaLM 2的论文是他们观点可能正确的第一个重大迹象。
与GPT-4一样,PaLM 2是一个生成式人工智能程序,可以根据提示生成文本簇,从而执行问答和软件编码等多项任务。
与OpenAI一样,谷歌也在改变几十年来人工智能研究领域的公开。这是谷歌2017年的一篇研究论文,“注意力就是你所需要的”,详细揭示了一个名为The Transformer的突破性项目。该程序很快被人工智能研究界和工业界采用,用于开发自然语言处理程序。
OpenAI在秋季推出了ChatGPT程序,该程序引发了全球对ChatGPT的兴奋。
包括Ashish Vaswani在内的原始论文的作者均未被列入PaLM 2的作者名单。
因此,从某种意义上说,通过在一段话中披露PaLM 2是The Transformer的后代,并拒绝透露其他任何信息,该公司的研究人员明确了他们对该领域的贡献以及他们结束分享突破性研究传统的意图。
他们写道,通过找到与训练数据量相关的程序大小的适当平衡,作者能够使PaLM 2程序节食,因此程序本身比原始PaLM程序小得多。考虑到人工智能的趋势最近朝着相反的方向发展,规模越来越大,这似乎意义重大。
正如作者所写,
PaLM 2 系列中最大的模型 PaLM 2-L 明显小于最大的 PaLM 模型,但使用更多的训练计算。我们的评估结果表明,PaLM 2 模型在各种任务(包括自然语言生成、翻译和推理)上都明显优于 PaLM。这些结果表明,模型缩放并不是提高性能的唯一方法。相反,可以通过细致的数据选择和高效的架构/目标来解锁性能。此外,更小但质量更高的模型可显著提高推理效率,降低服务成本,并使模型的下游应用程序可供更多应用程序和用户使用。
PaLM 2 的作者说,在程序大小和训练数据量的平衡之间有一个最佳平衡点。与PaLM相比,PaLM 2程序在基准测试中的准确性显着提高,正如作者在单个表格中概述的那样:
通过这种方式,他们正在建立对过去两年人工智能项目规模的实际研究的观察。
例如,乔丹·霍夫曼(Jordan Hoffman)及其同事去年在谷歌的DeepMind上广泛引用的一项工作创造了所谓的Chinchilla经验法则,即如何平衡训练数据量和程序大小的公式。
PaLM 2科学家提出的数字与霍夫曼及其团队略有不同,但它验证了该论文所说的话。他们在单个缩放表中与Chinchilla的工作正面展示他们的结果:
这一观点与一些年轻公司的努力是一致的,例如位于旧金山、成立三年的人工智能初创公司Snorkel,该公司于11月推出了标记培训数据的工具。Snorkel的前提是,更好地管理数据可以减少一些需要进行的计算。
这种聚焦于一个最优点的方式有点偏离最初的PaLM。通过该模型,谷歌强调了该项目的培训规模,指出这是“迄今为止用于培训的最大的基于TPU的系统配置”,指的是谷歌的TPU计算机芯片。
尽管在新的PaLM 2作品中透露的很少,但你可以说它确实证实了为了尺寸而从尺寸转向更深思熟虑的规模和能力处理的趋势。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
使用人工智能写作会影响人的观点








广告


写评论取消
回复取消