











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






像 GPT-4 这样的 LLM 的新兴能力是海市蜃楼吗?
2023年05月19日 由 Neo 发表
753123
0
 本文是揭秘AI的一部分,该系列文章试图消除围绕 AI 的行话和神话的歧义。
本文是揭秘AI的一部分,该系列文章试图消除围绕 AI 的行话和神话的歧义。类似ChatGPT和GPT-4这样的大型语言模型(LLM)拓展了全世界的想象力。它们呈现出许多迷人的能力,许多研究人员认为我们仅仅只是触及到了表面。
但斯坦福大学研究人员的一项新研究表明,其中一些能力可能被误解了。研究人员研究了之前报道的 LLMs 在成长过程中获得的“新能力”。他们的发现表明,当你选择正确的指标来评估 LLMs 时,他们的新能力就会消失。
这项研究很重要,因为它揭开了一些LLMs神奇而晦涩的神秘面纱。它还质疑了只有扩大规模才能创建更好的语言模型的观点。
LLMs的新能力
多项研究探讨了LLMs的新能力。一项研究将新能力定义为“在较小的模型中不存在但在较大的模型中存在的能力。”基本上,这意味着机器学习模型在某些任务上的表现将随机,直到它的大小达到一定的阈值。之后,随着它的增长,它会开始提高。你可以在以下图表中看到新能力,其中LLM的性能在某个比例尺上突然跃升。
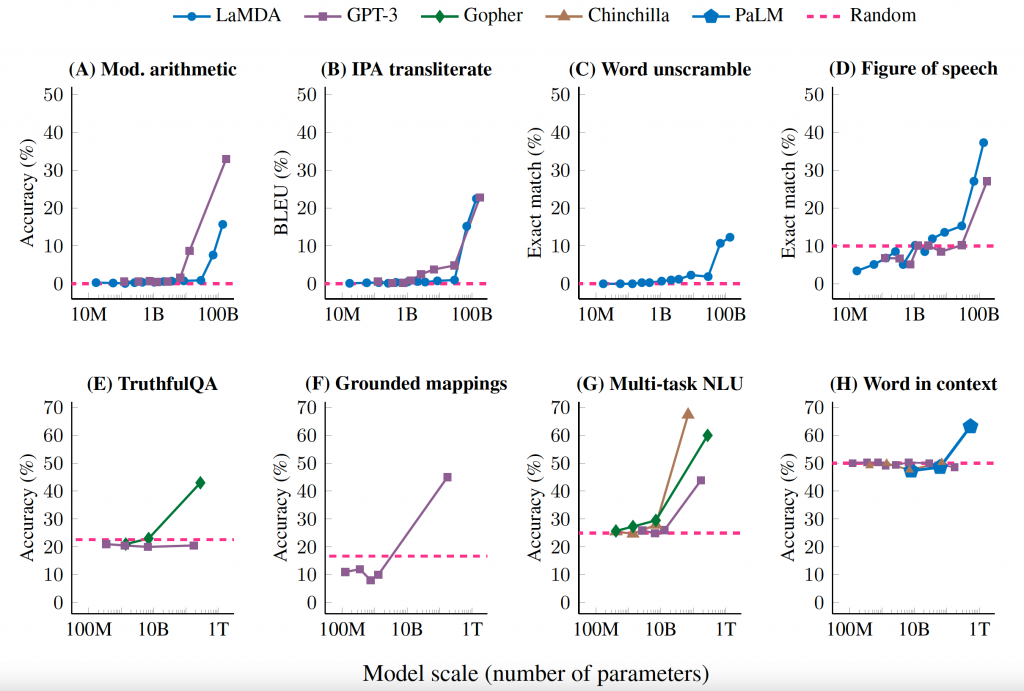
大型语言模型显示出大规模的新能力,其中任务的性能保持在随机水平,直到模型的大小达到某个阈值。之后,性能会随着模型变大而跳跃并开始改善。
研究人员研究了LLMs的新能力,这些LLMs的参数超过1000亿,例如LaMDA、GPT-3、Gopher、Chinchilla和PaLM。这些研究包括来自BIG-Bench的任务,这是一个众包基准测试,涵盖了语言学、常识推理和数学等多个领域。他们还使用了来自TruthfulQA、Massive Multi-task Language Understanding(MMLU)和Word in Context(WiC)的挑战,这些基准测试旨在测试LLMs在处理复杂语言任务方面的极限。
首先,这些研究表明,扩大LLMs而不添加更多创新仍然可以产生更多的通用AI能力。其次,它们表明随着LLMs变得越来越大,我们无法预测它们会有什么效果。当然,这些发现将进一步加强大型语言模型周围的神秘气息。
为什么LLMs的出现涉嫌过度宣传
斯坦福大学的这项新研究对LLMs的假定涌现能力提出了不同的看法。根据其调查结果,出现的观察通常是由指标的选择引起的,而不是规模。研究人员表示,“现有的新能力说明是研究人员分析的产物,而不是模型在特定规模任务上行为的根本变化。” 研究人员发现“有证据表明,新能力可能不是扩展人工智能模型的基本属性。”
具体来说,他们建议“新能力似乎只出现在非线性或不连续地缩放任何模型的每个标记错误率的指标下。” 基本上,这意味着在衡量一项任务的绩效时,一些指标可能会大规模涌现,而另一些指标则会持续改进。
例如,一些测试只测量LLMs输出的正确标记的数量。这种情况尤其发生在与分类和数学相关的任务中,只有在所有生成的标记都是正确的情况下,输出才是正确的。
实际上,模型产生的标记逐渐变得更接近正确的标记。但由于最终答案与基本事实不同,它们都被归类为不正确,直到它们达到所有标记都是正确的阈值。
在他们的研究中,研究人员表明,如果他们对相同的输出使用替代指标,则新能力会消失并且模型性能会平稳提高。这些指标衡量的是与真实答案的线性距离,而不仅仅是计算正确答案。
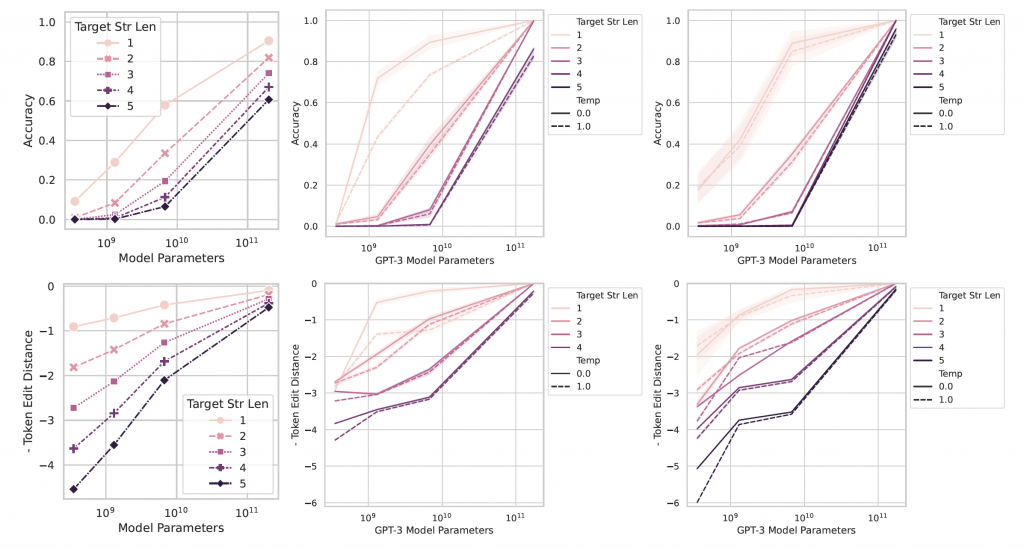
上图:当使用非线性指标进行评估时,LLM 显示出紧急行为 下图:当使用线性指标进行评估时,性能会平稳提高
研究人员还发现,在某些情况下,新能力出现是由于没有足够的测试数据。通过创建更大的测试数据集,性能改进变得顺利。
为了进一步推动这一点,研究人员试图看看他们是否可以在其他类型的深度神经网络中复现。他们对视觉任务和卷积神经网络 (CNN) 进行了测试。他们的发现表明,如果他们使用非线性指标来评估模型的性能,那么他们将观察到与 LLMs 中相同的涌现。
为什么重要
研究人员在论文结尾时做出了一个重要的观察:“对于一个固定的任务和一个固定的模型族群,研究人员可以选择一个度量来创造一个新的能力,也可以选择一个度量来削弱一个新的能力。因此,新的能力可能是研究人员选择的结果,而不是该模型族群在特定任务上的基本属性。”
虽然研究人员表示他们并不认为大型语言模型不能显示新的能力,但他们强调以前在LLM中声称的新能力“可能是研究人员分析引发的幻觉。”
重要的是要对大型语言模型的表现持更为批判的态度。鉴于LLMs的惊人结果,已经有一种倾向将它们赋予人类特征或与其不具备的属性相关联。
我认为这篇论文的发现非常重要,因为它们将有助于使该领域更加现实,并更好地了解扩展模型的影响。 Sam Bowman最近的一篇论文指出:“当实验室投资于培训一种前沿规模的新LLM时,他们在购买一个神秘盒子:他们有正当理由相信他们将获得各种经济价值的新能力,但他们无法做出关于这些能力将是什么或他们需要做哪些准备才能负责地部署它们的自信预测。” 有了更好的衡量和预测改进的技术,科学家们将更好地评估更大模型的益处和风险。
这种方法还有助于鼓励探索不同于创造更大的LLMs的替代方案。虽然只有大型科技企业能够承担训练和测试非常大的模型,但较小的组织可以对较小的模型进行研究。有了这些度量标准,他们将能够更好地探索这些较小模型的能力,并找到新的研究方向以改进它们。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消