











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






WebLLM:将LLM聊天机器人带到浏览器
2023年05月23日 由 daydream 发表
966974
0
如果你能在浏览器中本地运行LLM和LLM聊天机器人,那不是很酷吗?让我们进一步了解WebLLM项目,这是朝着这个方向迈出的有趣一步。
基于 LLM 的聊天机器人可以通过前端访问,它们涉及对服务器端的大量昂贵的 API 调用。但是,如果我们可以让LLM完全在浏览器中运行 - 使用底层系统的计算能力呢?

这样,LLM 的全部功能就可以在客户端使用,而不必担心服务器可用性、基础结构等。WebLLM是一个旨在实现这一目标的项目。
让我们进一步了解WebLLM的驱动因素以及构建这样一个项目所面临的挑战。我们还将了解WebLLM的优势和局限性。
什么是WebLLM?
WebLLM是一个使用WebGPU和WebAssembly以及更多功能来实现LLM和LLM应用程序完全在浏览器中运行的项目。使用WebLLM,你可以通过WebGPU利用底层系统的GPU,在浏览器中运行LLM聊天机器人。
它使用Apache TVM项目的编译器堆栈,并使用最近发布的WebGPU。除了3D图形渲染等,WebGPU API还支持通用GPU计算(GPGPU计算)。
构建WebLLM的挑战
由于WebLLM完全运行在客户端,没有任何推理服务器,因此该项目面临以下挑战:
大型语言模型使用 Python 框架进行深度学习,这些框架本身也支持利用 GPU 对张量进行操作。
当构建完全在浏览器中运行的WebLLM时,我们将无法使用相同的Python框架。必须探索能够在网络上运行LLM同时仍使用Python进行开发的替代技术堆栈。
运行 LLM 应用程序通常需要大型推理服务器,但是当所有内容都在客户端(在浏览器中)运行时,我们就不能再拥有大型推理服务器了。
需要智能压缩模型,以使其适合可用内存。
WebLLM如何工作?
WebLLM项目使用底层系统的GPU和硬件功能在浏览器中运行大型语言模型。机器学习编译过程通过利用TVM Unity和一系列优化,有助于将LLM的功能嵌入到浏览器端。
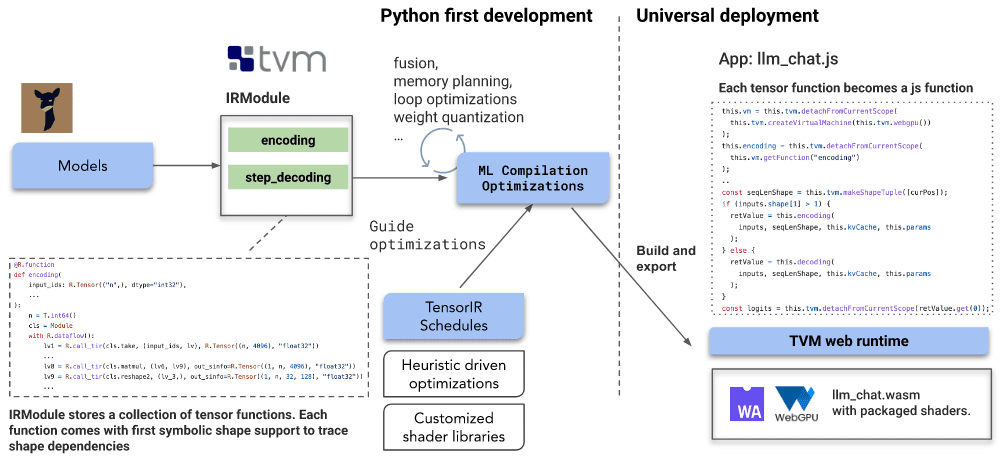
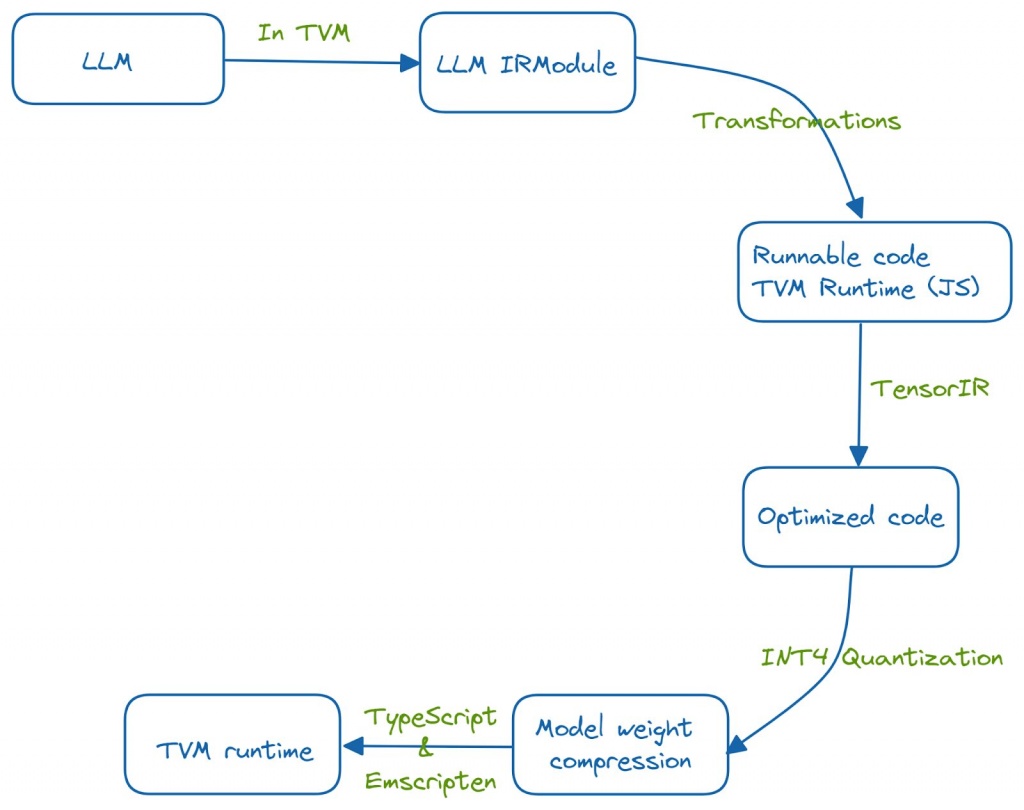
该系统是用Python开发的,并使用TVM运行时在Web上运行。这种移植到 Web 浏览器是通过运行一系列优化来实现的。
LLM的功能首先被嵌入到TVM的IRModule中。在IRModule中的函数上运行了几个转换,以获得优化的可运行代码。TensorIR是一个编译器,用于优化具有张量计算的程序。此外,使用INT-4量化来压缩模型。TVM运行时可以使用TypeScript和emscripten(一个LLVM编译器,可以将C和c++代码转换为WebAssembly)。
你需要拥有最新版本的Chrome或Chrome Canary才能试用WebLLM。在撰写本文时,WebLLM支持Vicuna和LLaMa LLM。
第一次运行模型时,加载模型需要一段时间。因为缓存是在第一次运行之后完成的,所以后续的运行速度要快得多,开销也要小得多。

WebLLM的优势和局限性
让我们通过列举WebLLM的优点和局限性来结束讨论。
优势
除了探索Python,WebAssembly和其他技术堆栈的协同作用外,WebLLM还具有以下优势:
在浏览器中运行LLM的主要优点是保护隐私。由于在这种隐私优先的设计中完全消除了服务器端,因此我们不再需要担心数据的使用。因为WebLLM利用了底层系统GPU的计算能力,所以我们不必担心数据会到达恶意实体。
我们可以为日常活动构建个人AI助手。因此,WebLLM项目提供了高度的个性化。
WebLLM的另一个优点是降低了成本。我们不再需要昂贵的API调用和推理服务器,WebLLM使用底层系统的GPU和处理能力。因此,运行WebLLM的成本很低。
局限性
以下是WebLLM的一些限制:
尽管WebLLM减轻了人们对输入敏感信息的担忧,但它仍然容易受到浏览器的攻击。
通过增加对多种语言模型的支持和对浏览器的选择还有进一步的改进空间。目前,该功能仅在Chrome Canary和最新版本的Chrome中可用。将其扩展到一组更大的受支持的浏览器将很有帮助。
由于浏览器运行的稳健性检查使 WebGPU 的 WebLLM 不具有 GPU 运行时的本机性能。你可以选择禁用运行稳健性检查的标志以提高性能。
结论
我们试图了解WebLLM是如何工作的。你可以尝试在浏览器中运行它,甚至可以在本地部署它。考虑在浏览器中运行这个模型,并检查将其集成到日常工作流程中的有效性。如果你感兴趣,还可以查看MLC-LLM项目,它允许你在任何设备(包括笔记本电脑和iPhone)上运行LLM。
基于 LLM 的聊天机器人可以通过前端访问,它们涉及对服务器端的大量昂贵的 API 调用。但是,如果我们可以让LLM完全在浏览器中运行 - 使用底层系统的计算能力呢?
这样,LLM 的全部功能就可以在客户端使用,而不必担心服务器可用性、基础结构等。WebLLM是一个旨在实现这一目标的项目。
让我们进一步了解WebLLM的驱动因素以及构建这样一个项目所面临的挑战。我们还将了解WebLLM的优势和局限性。
什么是WebLLM?
WebLLM是一个使用WebGPU和WebAssembly以及更多功能来实现LLM和LLM应用程序完全在浏览器中运行的项目。使用WebLLM,你可以通过WebGPU利用底层系统的GPU,在浏览器中运行LLM聊天机器人。
它使用Apache TVM项目的编译器堆栈,并使用最近发布的WebGPU。除了3D图形渲染等,WebGPU API还支持通用GPU计算(GPGPU计算)。
构建WebLLM的挑战
由于WebLLM完全运行在客户端,没有任何推理服务器,因此该项目面临以下挑战:
大型语言模型使用 Python 框架进行深度学习,这些框架本身也支持利用 GPU 对张量进行操作。
当构建完全在浏览器中运行的WebLLM时,我们将无法使用相同的Python框架。必须探索能够在网络上运行LLM同时仍使用Python进行开发的替代技术堆栈。
运行 LLM 应用程序通常需要大型推理服务器,但是当所有内容都在客户端(在浏览器中)运行时,我们就不能再拥有大型推理服务器了。
需要智能压缩模型,以使其适合可用内存。
WebLLM如何工作?
WebLLM项目使用底层系统的GPU和硬件功能在浏览器中运行大型语言模型。机器学习编译过程通过利用TVM Unity和一系列优化,有助于将LLM的功能嵌入到浏览器端。
该系统是用Python开发的,并使用TVM运行时在Web上运行。这种移植到 Web 浏览器是通过运行一系列优化来实现的。
LLM的功能首先被嵌入到TVM的IRModule中。在IRModule中的函数上运行了几个转换,以获得优化的可运行代码。TensorIR是一个编译器,用于优化具有张量计算的程序。此外,使用INT-4量化来压缩模型。TVM运行时可以使用TypeScript和emscripten(一个LLVM编译器,可以将C和c++代码转换为WebAssembly)。
你需要拥有最新版本的Chrome或Chrome Canary才能试用WebLLM。在撰写本文时,WebLLM支持Vicuna和LLaMa LLM。
第一次运行模型时,加载模型需要一段时间。因为缓存是在第一次运行之后完成的,所以后续的运行速度要快得多,开销也要小得多。
WebLLM的优势和局限性
让我们通过列举WebLLM的优点和局限性来结束讨论。
优势
除了探索Python,WebAssembly和其他技术堆栈的协同作用外,WebLLM还具有以下优势:
在浏览器中运行LLM的主要优点是保护隐私。由于在这种隐私优先的设计中完全消除了服务器端,因此我们不再需要担心数据的使用。因为WebLLM利用了底层系统GPU的计算能力,所以我们不必担心数据会到达恶意实体。
我们可以为日常活动构建个人AI助手。因此,WebLLM项目提供了高度的个性化。
WebLLM的另一个优点是降低了成本。我们不再需要昂贵的API调用和推理服务器,WebLLM使用底层系统的GPU和处理能力。因此,运行WebLLM的成本很低。
局限性
以下是WebLLM的一些限制:
尽管WebLLM减轻了人们对输入敏感信息的担忧,但它仍然容易受到浏览器的攻击。
通过增加对多种语言模型的支持和对浏览器的选择还有进一步的改进空间。目前,该功能仅在Chrome Canary和最新版本的Chrome中可用。将其扩展到一组更大的受支持的浏览器将很有帮助。
由于浏览器运行的稳健性检查使 WebGPU 的 WebLLM 不具有 GPU 运行时的本机性能。你可以选择禁用运行稳健性检查的标志以提高性能。
结论
我们试图了解WebLLM是如何工作的。你可以尝试在浏览器中运行它,甚至可以在本地部署它。考虑在浏览器中运行这个模型,并检查将其集成到日常工作流程中的有效性。如果你感兴趣,还可以查看MLC-LLM项目,它允许你在任何设备(包括笔记本电脑和iPhone)上运行LLM。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消