











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用LSTM预测比特币价格
2017年08月28日 由 yuxiangyu 发表
627949
0
本文以“时间序列预测的LSTM神经网络”这篇文章为基础。如果没有阅读,我强烈建议你读一读。
考虑到近期对比特币货币的泡沫的讨论,我写了这篇文章,主要是为了预测比特币的价格和张量,我使用一个不只是看价格还查看BTC交易量和货币(在这种情况下为美元)的多维LSTM神经网络,并创建一个多变量序列机器学习模型。
闲言少叙,我们进入正题。
我们首先需要数据。幸运的是,Kaggle上有一个数据集其中包含7种要素的比特币历史数据,十分完美。
然而,我们需要在将该数据集传入我们的LSTM之前对其进行归一化。具体操作请参考我的上一篇文章,我们在数据上取一个大小为N的滑动窗口,并将数据重新建立为从0: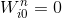 。
。
这是一个种多维的方法,就是说我们要在所有维度上进行这种滑动窗口方法。一般来说这会是个痛苦的工作。但幸运的是,我们能够使用Python中的Pandas库!我们可以将每个窗口表示为Pandas数据框,然后我们可以在整个数据框(即所有的列)中执行归一化操作。
你需要注意到另一件事是,这个数据集在一开始数据不是很整齐。在各个列中有很多NaN值。我们采取一种比较懒的方法来解决这个问题:当我们创建窗口时,我们将检查窗口中值是否存在NaN。如果是的话,我们舍弃这个窗口移动到下一个窗口。
虽然我们在这里,我们把这些函数输入一个叫做ETL(extract, transform, load)的自包含类,并将其保存为etl.py,我们可以将完整的数据载入称为库。
这是我们的clean_data()函数的核心代码:
一旦完成这个,我们只需确保我们的LSTM模型接受M型的序列,其中M=数据的维数,这样就完成了!
或者你认为这样就可以完成了,但生活很少会让你这样顺心。我第一次尝试这样做的时候我的机器停了下来,然后给我反馈了一个内存错误。你看,这个问题来自于使用的比特币数据集每分钟都有记录,所以数据集是相当的大。归一化时,有大约100万个数据窗口。并将所有这100万个窗口加载到Keras并开始训练耗时极长。
那么如果你没有100G的RAM的话怎样训练这些数据呢(就算你有这么大的RAM,如果这个数据增长到100倍,添加更多RAM显然不太可行)?这时我们要用到Keras fit_generator()函数!
现在,如果你不了解Python生成器,请去先去了解它。
简而言之; 一个生成器会遍历未知(可能无限大)长度的数据,每次调用只传递下一个数据。现在,只要你有一半的脑子,我相信你可以看得出它是有用的; 如果我们一次可以训练模型一组窗口,那么一旦我们完成了这个窗口,就可以把它扔掉,用下一组窗口替代。这样就可以训练具有低内存利用率的模型。从技术上讲,如果你把窗户做得足够小,你甚至可以在你的物联网烤面包机上训练这个模型,只要你想做!
我们需要做的是创建一个生成器,创建一批windows,然后将其传递给Keras fit_generator()函数。简而言之,我们只是扩展clean_data()的核心代码来生成(在生成方式里返回)批量的窗口:
现在我在这里发现的另一个问题是我创建的clean_data()生成器平均3-4秒才能创建每个“批处理”的窗口。这本身是可以接受的,因为需要大约15-20分钟才能通过一批训练数据。但如果我想调整模型并重新运行,那就需要花很长时间重新训练它。
那我们怎么办呢?试试先把它归一化,然后把它的归一化的numpy数组保存到一个文件中,希望它能保留结构,并能快速访问吗?
HDF5能够帮助你!通过使用h5py库,我们可以轻松地将整齐并且归一化的数据窗口保存为秒级以下的IO访问的numpy数组列表。因此我们创建刚好可以做到这点的名为create_clean_datafile()的函数:
现在我们可以创建一个新的发生器函数generate_clean_data()来打开hdf5文件,并以极快的速度将这些相同的归一化批处理输入到Keras fit_generator()函数中!
然而,查看数据,我们不希望在某些维度上增加不必要的噪音。我的做法是为create_clean_datafile()函数创建一个参数,该函数接受要素(列)的过滤。有了这个,我将数据文件缩小到由Open,Close,Volume(比特币)和Volume(货币)组成的4维时间序列。这样做会减少我训练网络的时间。
然后将数据馈送到网络中,这个网络具有:一个输入LSTM层接收模型数据[dimension,sequence_size,training_rows],隐藏的第二个LSTM层的数据,以及具有tanh函数的完全连接输出层,用于输出下一个预测归一化回报率。
通过在我们的配置JSON文件中指定的基于我们的历元数和我们的训练或测试拆分计算 steps_per_epoch来完成训练。
我们用以类似的方式进行测试,使用相同的发生器并训练和利用eras predict_generator()函数。在预测我们的测试集时,我们需要添加的唯一额外的事情是迭代发生器并分离出x和y输出的输出。这是因为Keras predict_generator()函数只接受x输入,并且不会处理x和y值的元组。然而,我们仍然希望使用y值(真实数据),因此我们将它们存储在一个单独的列表中,因为我们希望使用它们进行绘图,以防与真实数据对比并将结果可视化。然后,我们做同样的事情,而不是逐步预测,我们用第一个预测预置的一个大小为50的窗口,然后沿着新的预测将窗口沿着滑动窗口,将它们作为真实数据,所以我们慢慢开始预测这个预测,由此预测接下来的50个步骤。
最后,我们将测试集预测和测试集真正的y值保存在HDF5文件中,以便我们可以在将来轻松访问它们,不用重新运行所有内容,如果模型是有用的。然后我们将结果绘制在2张图上。一个显示每天一步前进的预测,另一个显示五十步的前进预测。
我们来接着预测Bitcon的价格!根据我上一篇文章,我们将尝试做两种类型的预测:
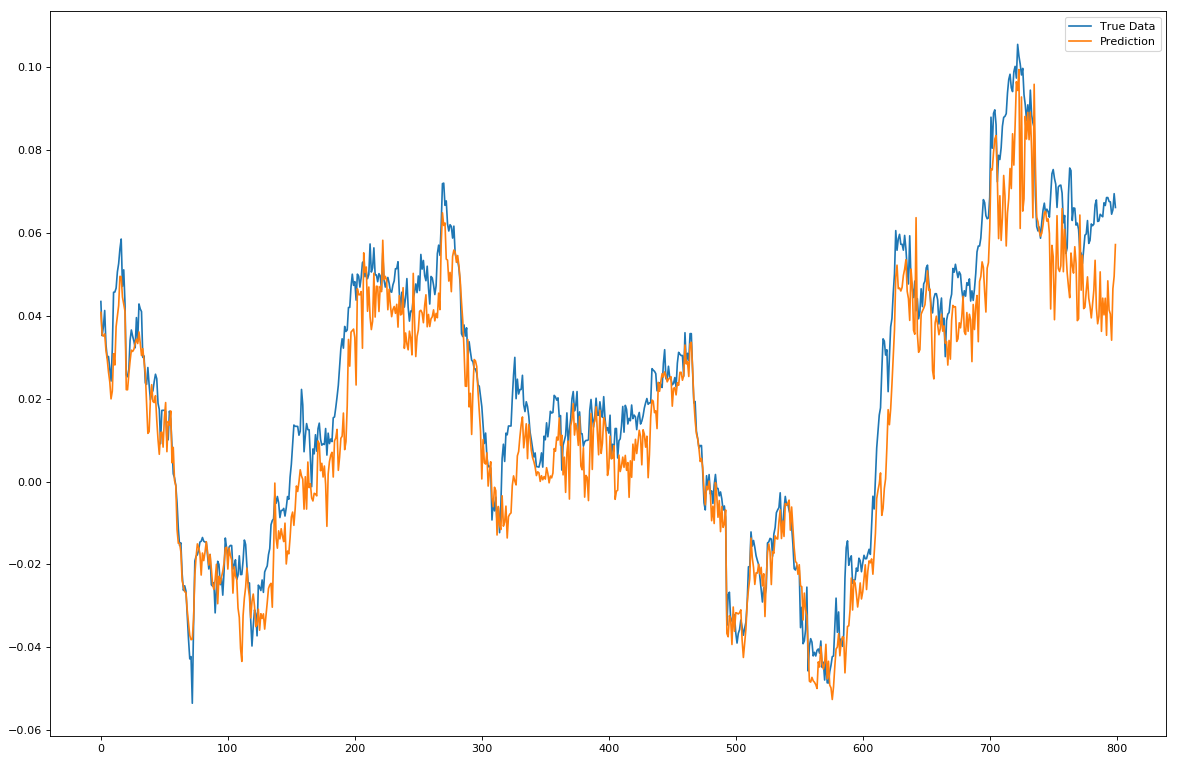
第一个是逐点地预测,即预测t+1点,然后移动真实数据的窗口并继续预测下一个点,结果如下:
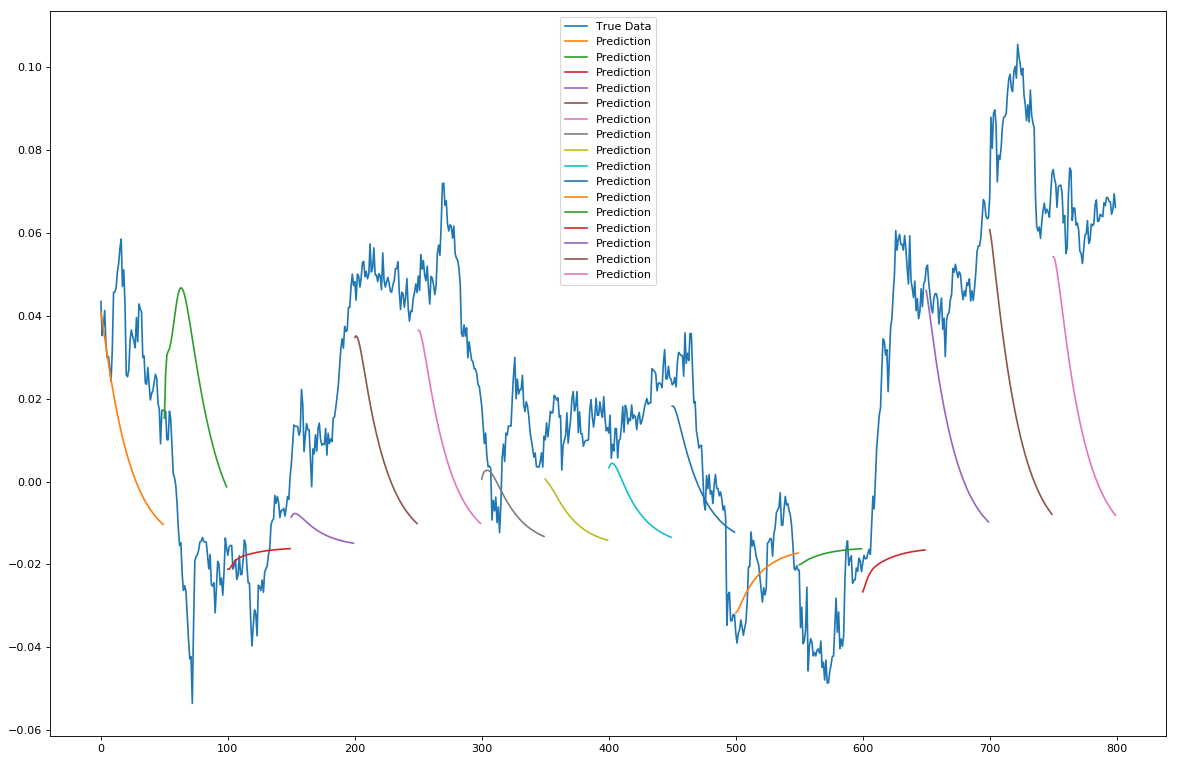
第二种预测类型是t+n的多步超前预测,我们在移动窗口填充真实数据窗口预置的预测,并绘制N个步骤。结果如下:
那么,我们可以看到,逐点预测时,预测做的很合理。有时候会有些出入,但总体遵循真实数据。但是,这些预测的确比真实的数据更不稳定。因为没有做更多的测试,很难确定可能的原因,如果模型重新参数化会解决这个问题。
当预测趋势时,这种模式准确度开始下降。这种趋势似乎不是特别准确,有时甚至是不一致的。然而!有趣的是,预测趋势线的大小似乎与价格波动的大小有关。
这一节我不以人工智能帽子的角度,而以投资经理的角度来解释一些关键的事实……
人们应该意识到的主要问题是,预测回报是一项相当没用的活动。我的意思是说,预测回报是预测的圣杯,而一些顶级对冲基金视图通过在事实中找到新的alpha指标来做到这一点,这是一件非常困难的事情,因为巨大的外部影响会推高资产价格。实际上,它可以相当于试图预测随机的下一步。
但是,我们做的也并不是完全没有意义。有限的时间序列数据,即使有多个维度,也很难预测回报,我们可以看到,特别是从第二个图表看到,是有一个预测波动的方法。而不仅仅是波动,而且我们也可以通过扩张它来预测市场环境,使我们能够了解我们目前所在的市场环境。
哪里有用呢?很多不同的策略(我不会去这里说)分别在不同的市场环境中运作良好。一个动量策略可能在低迷和强烈的趋势环境中运作良好,套利策略可能会更有成效地在高压环境中产生高回报。我们可以看到,通过了解我们当前的市场环境,预测未来的市场环境是在任何时候将正确的策略分配到市场的关键。虽然这更多是传统市场的一般投资方式,但同样适用于比特币市场。
所以你可以看到,预测比特币的长期价格目前相当的困难,没有人可以只是通过时间序列数据技术做到,因为有很多因素加入了价格变动。在这样的数据集上使用LSTM神经网络的另一个问题是我们将整个时间序列数据集作为一个固定的时间序列。也就是说,时间序列的属性在整个时间内都是不变的。然而这不可能,因为影响价格变化的因素也随时间而变化,所以假设网络发现的属性或模式在现在仍然使用是一种天真的想法,真的并不一定是这样。
有一些工作可以帮助这个非平稳性问题,目前的前沿研究重点是利用贝叶斯方法和LSTM一起克服时间序列非平稳性的问题。
当然这超出了这篇短文的范围。
该项目的完整代码:Multidimensional-LSTM-BitCoin-Time-Series。
考虑到近期对比特币货币的泡沫的讨论,我写了这篇文章,主要是为了预测比特币的价格和张量,我使用一个不只是看价格还查看BTC交易量和货币(在这种情况下为美元)的多维LSTM神经网络,并创建一个多变量序列机器学习模型。
闲言少叙,我们进入正题。
时间数据集
我们首先需要数据。幸运的是,Kaggle上有一个数据集其中包含7种要素的比特币历史数据,十分完美。
然而,我们需要在将该数据集传入我们的LSTM之前对其进行归一化。具体操作请参考我的上一篇文章,我们在数据上取一个大小为N的滑动窗口,并将数据重新建立为从0:
。这是一个种多维的方法,就是说我们要在所有维度上进行这种滑动窗口方法。一般来说这会是个痛苦的工作。但幸运的是,我们能够使用Python中的Pandas库!我们可以将每个窗口表示为Pandas数据框,然后我们可以在整个数据框(即所有的列)中执行归一化操作。
你需要注意到另一件事是,这个数据集在一开始数据不是很整齐。在各个列中有很多NaN值。我们采取一种比较懒的方法来解决这个问题:当我们创建窗口时,我们将检查窗口中值是否存在NaN。如果是的话,我们舍弃这个窗口移动到下一个窗口。
虽然我们在这里,我们把这些函数输入一个叫做ETL(extract, transform, load)的自包含类,并将其保存为etl.py,我们可以将完整的数据载入称为库。
这是我们的clean_data()函数的核心代码:
num_rows = len(data)
x_data = []
y_data = []
i = 0
while((i+x_window_size+y_window_size) <= num_rows):
x_window_data = data[i:(i+x_window_size)]
y_window_data = data[(i+x_window_size):(i+x_window_size+y_window_size)]
#Remove any windows that contain NaN
if(x_window_data.isnull().values.any() or y_window_data.isnull().values.any()):
i += 1
continue
if(normalise):
abs_base, x_window_data = self.zero_base_standardise(x_window_data)
_, y_window_data = self.zero_base_standardise(y_window_data, abs_base=abs_base)
#Average of the desired predicter y column
y_average = np.average(y_window_data.values[:, y_col])
x_data.append(x_window_data.values)
y_data.append(y_average)
i += 1
一旦完成这个,我们只需确保我们的LSTM模型接受M型的序列,其中M=数据的维数,这样就完成了!
加载内存的损害
或者你认为这样就可以完成了,但生活很少会让你这样顺心。我第一次尝试这样做的时候我的机器停了下来,然后给我反馈了一个内存错误。你看,这个问题来自于使用的比特币数据集每分钟都有记录,所以数据集是相当的大。归一化时,有大约100万个数据窗口。并将所有这100万个窗口加载到Keras并开始训练耗时极长。
那么如果你没有100G的RAM的话怎样训练这些数据呢(就算你有这么大的RAM,如果这个数据增长到100倍,添加更多RAM显然不太可行)?这时我们要用到Keras fit_generator()函数!
现在,如果你不了解Python生成器,请去先去了解它。
简而言之; 一个生成器会遍历未知(可能无限大)长度的数据,每次调用只传递下一个数据。现在,只要你有一半的脑子,我相信你可以看得出它是有用的; 如果我们一次可以训练模型一组窗口,那么一旦我们完成了这个窗口,就可以把它扔掉,用下一组窗口替代。这样就可以训练具有低内存利用率的模型。从技术上讲,如果你把窗户做得足够小,你甚至可以在你的物联网烤面包机上训练这个模型,只要你想做!
我们需要做的是创建一个生成器,创建一批windows,然后将其传递给Keras fit_generator()函数。简而言之,我们只是扩展clean_data()的核心代码来生成(在生成方式里返回)批量的窗口:
#Restrict yielding until we have enough in our batch. Then clear x, y data for next batch
if(i % batch_size == 0):
#Convert from list to 3 dimensional numpy array [windows, window_val, val_dimension]
x_np_arr = np.array(x_data)
y_np_arr = np.array(y_data)
x_data = []
y_data = []
yield (x_np_arr, y_np_arr)
令人烦恼的重新运行
现在我在这里发现的另一个问题是我创建的clean_data()生成器平均3-4秒才能创建每个“批处理”的窗口。这本身是可以接受的,因为需要大约15-20分钟才能通过一批训练数据。但如果我想调整模型并重新运行,那就需要花很长时间重新训练它。
那我们怎么办呢?试试先把它归一化,然后把它的归一化的numpy数组保存到一个文件中,希望它能保留结构,并能快速访问吗?
HDF5能够帮助你!通过使用h5py库,我们可以轻松地将整齐并且归一化的数据窗口保存为秒级以下的IO访问的numpy数组列表。因此我们创建刚好可以做到这点的名为create_clean_datafile()的函数:
def create_clean_datafile(self, filename_in, filename_out, batch_size=1000, x_window_size=100, y_window_size=1, y_col=0, filter_cols=None, normalise=True):
"""Incrementally save a datafile of clean data ready for loading straight into model"""
print('> Creating x & y data files...')
data_gen = self.clean_data(
filename_in,
batch_size = batch_size,
x_window_size = x_window_size,
y_window_size = y_window_size,
y_col = y_col,
filter_cols = filter_cols,
normalise = True
)
i = 0
with h5py.File(filename_out, 'w') as hf:
x1, y1 = next(data_gen)
#Initialise hdf5 x, y datasets with first chunk of data
rcount_x = x1.shape[0]
dset_x = hf.create_dataset('x', shape=x1.shape, maxshape=(None, x1.shape[1], x1.shape[2]), chunks=True)
dset_x[:] = x1
rcount_y = y1.shape[0]
dset_y = hf.create_dataset('y', shape=y1.shape, maxshape=(None,), chunks=True)
dset_y[:] = y1
for x_batch, y_batch in data_gen:
#Append batches to x, y hdf5 datasets
print('> Creating x & y data files | Batch:', i, end='\r')
dset_x.resize(rcount_x + x_batch.shape[0], axis=0)
dset_x[rcount_x:] = x_batch
rcount_x += x_batch.shape[0]
dset_y.resize(rcount_y + y_batch.shape[0], axis=0)
dset_y[rcount_y:] = y_batch
rcount_y += y_batch.shape[0]
i += 1
现在我们可以创建一个新的发生器函数generate_clean_data()来打开hdf5文件,并以极快的速度将这些相同的归一化批处理输入到Keras fit_generator()函数中!
def generate_clean_data(self, filename, batch_size=1000, start_index=0):
with h5py.File(filename, 'r') as hf:
i = start_index
while True:
data_x = hf['x'][i:i+batch_size]
data_y = hf['y'][i:i+batch_size]
i += batch_size
yield (data_x, data_y)
然而,查看数据,我们不希望在某些维度上增加不必要的噪音。我的做法是为create_clean_datafile()函数创建一个参数,该函数接受要素(列)的过滤。有了这个,我将数据文件缩小到由Open,Close,Volume(比特币)和Volume(货币)组成的4维时间序列。这样做会减少我训练网络的时间。
然后将数据馈送到网络中,这个网络具有:一个输入LSTM层接收模型数据[dimension,sequence_size,training_rows],隐藏的第二个LSTM层的数据,以及具有tanh函数的完全连接输出层,用于输出下一个预测归一化回报率。
通过在我们的配置JSON文件中指定的基于我们的历元数和我们的训练或测试拆分计算 steps_per_epoch来完成训练。
我们用以类似的方式进行测试,使用相同的发生器并训练和利用eras predict_generator()函数。在预测我们的测试集时,我们需要添加的唯一额外的事情是迭代发生器并分离出x和y输出的输出。这是因为Keras predict_generator()函数只接受x输入,并且不会处理x和y值的元组。然而,我们仍然希望使用y值(真实数据),因此我们将它们存储在一个单独的列表中,因为我们希望使用它们进行绘图,以防与真实数据对比并将结果可视化。然后,我们做同样的事情,而不是逐步预测,我们用第一个预测预置的一个大小为50的窗口,然后沿着新的预测将窗口沿着滑动窗口,将它们作为真实数据,所以我们慢慢开始预测这个预测,由此预测接下来的50个步骤。
最后,我们将测试集预测和测试集真正的y值保存在HDF5文件中,以便我们可以在将来轻松访问它们,不用重新运行所有内容,如果模型是有用的。然后我们将结果绘制在2张图上。一个显示每天一步前进的预测,另一个显示五十步的前进预测。
比特币利润
我们来接着预测Bitcon的价格!根据我上一篇文章,我们将尝试做两种类型的预测:
第一个是逐点地预测,即预测t+1点,然后移动真实数据的窗口并继续预测下一个点,结果如下:
第二种预测类型是t+n的多步超前预测,我们在移动窗口填充真实数据窗口预置的预测,并绘制N个步骤。结果如下:
那么,我们可以看到,逐点预测时,预测做的很合理。有时候会有些出入,但总体遵循真实数据。但是,这些预测的确比真实的数据更不稳定。因为没有做更多的测试,很难确定可能的原因,如果模型重新参数化会解决这个问题。
当预测趋势时,这种模式准确度开始下降。这种趋势似乎不是特别准确,有时甚至是不一致的。然而!有趣的是,预测趋势线的大小似乎与价格波动的大小有关。
结论
这一节我不以人工智能帽子的角度,而以投资经理的角度来解释一些关键的事实……
人们应该意识到的主要问题是,预测回报是一项相当没用的活动。我的意思是说,预测回报是预测的圣杯,而一些顶级对冲基金视图通过在事实中找到新的alpha指标来做到这一点,这是一件非常困难的事情,因为巨大的外部影响会推高资产价格。实际上,它可以相当于试图预测随机的下一步。
但是,我们做的也并不是完全没有意义。有限的时间序列数据,即使有多个维度,也很难预测回报,我们可以看到,特别是从第二个图表看到,是有一个预测波动的方法。而不仅仅是波动,而且我们也可以通过扩张它来预测市场环境,使我们能够了解我们目前所在的市场环境。
哪里有用呢?很多不同的策略(我不会去这里说)分别在不同的市场环境中运作良好。一个动量策略可能在低迷和强烈的趋势环境中运作良好,套利策略可能会更有成效地在高压环境中产生高回报。我们可以看到,通过了解我们当前的市场环境,预测未来的市场环境是在任何时候将正确的策略分配到市场的关键。虽然这更多是传统市场的一般投资方式,但同样适用于比特币市场。
所以你可以看到,预测比特币的长期价格目前相当的困难,没有人可以只是通过时间序列数据技术做到,因为有很多因素加入了价格变动。在这样的数据集上使用LSTM神经网络的另一个问题是我们将整个时间序列数据集作为一个固定的时间序列。也就是说,时间序列的属性在整个时间内都是不变的。然而这不可能,因为影响价格变化的因素也随时间而变化,所以假设网络发现的属性或模式在现在仍然使用是一种天真的想法,真的并不一定是这样。
有一些工作可以帮助这个非平稳性问题,目前的前沿研究重点是利用贝叶斯方法和LSTM一起克服时间序列非平稳性的问题。
当然这超出了这篇短文的范围。
该项目的完整代码:Multidimensional-LSTM-BitCoin-Time-Series。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消