











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软开源13亿参数的LLaVA聊天机器人支持自然语言和视觉交互
2023年05月31日 由 Susan 发表
969364
0
研究人员使用GPT-4生成了指令跟踪数据集,其中包含了一个人类用户和一个人工智能助手之间关于图像内容的虚拟对话。该数据集被用于微调LLaVA模型,该模型由两个基础模型CLIP(视觉)和LLaMA(语言)组成,并添加了一个额外的网络层将两者联系在一起。团队还使用GPT-4在实验中评估了LLaVA的响应,通过要求它按照1到10的比例评估LLaVA的输出。当在Science QA 训练数据集上进行进一步微调后,LLaVA实现了92.53%的准确率,创下了新的记录。
使用指令跟踪数据集微调大型语言模型(LLMs)的技术已经提高了性能,如ChatGPT所示,并促使研究人员探索这种技术在较小的LLMs中的应用。 InfoQ最近报道了LLaMA,与GPT-3的175B相比,它只有7B个参数,但在许多任务上可以超越GPT-3。人工智能助手发展的下一步是增加处理图像数据的能力,这在GPT-4和Visual ChatGPT的发布中得到了展示。
LLaVA团队的目标是通过视觉指令微调来端到端地训练模型。为此,研究人员从COCO数据集中提取了图像。由于这些图像附有标题和对象边界框的注释,团队将这些数据与提示一起输入到仅文本的GPT-4中,要求GPT-4输出指令跟踪数据,包括:人类用户和一个人工智能助手之间关于图像内容的虚拟对话 ,关于图像内容细节的问题,以及需要推理图像内容的问题。总体而言,生成的数据集包含158K个样本。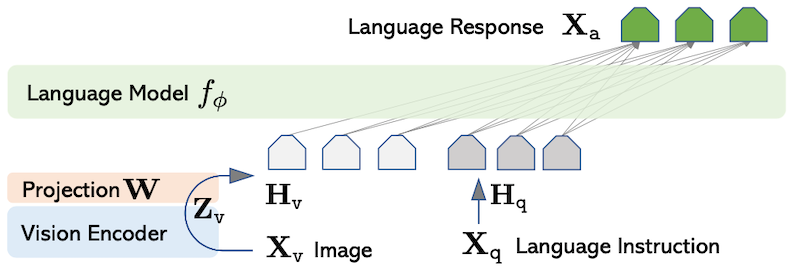
来自微软、威斯康星大学麦迪逊分校和哥伦比亚大学的研究人员已经开源了大型语言和视觉助手(LLaVA)。LLaVA基于CLIP图像编码器和LLaMA语言解码器,在合成指令遵循数据集上进行微调,并在Science QA基准测试中实现了最先进的准确性。
研究人员使用GPT-4生成指令跟踪数据集,其中包含人类用户和AI助手之间关于图像内容的虚拟对话。该数据集用于微调LLaVA模型,该模型由两个基础模型组成:用于视觉的CLIP和用于语言的LLaMA,以及将两者联系在一起的附加网络层。该团队还使用GPT-4来评估LLaVA在实验中的反应,要求它以1到10的等级对LLaVA的输出进行评分。当在ScienceQA训练数据集上进一步微调时,LLaVA的准确率达到了92.53%,创下了基准的新纪录。根据研究人员的说法,
正如ChatGPT所证明的那样,使用指令跟踪数据集微调大型语言模型(LLM)的技术已经提高了性能,并促使研究人员使用较小的LLM探索这种技术。 InfoQ最近报道了LLaMA,与GPT-7的3B相比,LLaMA只有175B参数,但在许多任务上可以胜过GPT-3。开发AI助手的下一步是增加处理图像数据的能力,如GPT-4和Visual ChatGPT的发布所示。
LLaVA 团队的目标是通过视觉指令调整来端到端地训练模型。为此,研究人员从从COCO数据集中提取的图像开始。由于图像带有标题和对象边界框的注释,因此团队将此数据输入纯文本 GPT-4 以及提示,要求 GPT-4 输出遵循指令的数据,包括:一个人和助手之间的想象对话、关于图像内容细节的问题,以及需要对图像内容进行推理的问题。总体而言,生成的数据集包含 158K 个样本。
LLaVA架构由一个CLIP基础模型和一个投影矩阵层组成,用于将图像转换为单词嵌入空间;文本输入也被转换为相同的空间。然后将图像和单词标记传递到LLaMA解码器,产生输出。预训练过程首先训练投影矩阵,然后微调过程更新投影层和LLaMA解码器权重;CLIP权重被冻结。
LLaVA的作者Chunyuan Li在Twitter上回答了一些有关这项工作的问题。当一些用户将LLaMA与MiniGPT-4进行比较时,Chunyuan Li指出LLaMA能够重现GPT-4论文的基于图像的结果,而MiniGPT-4则做不到。他还说:“LLaVA具有严格的定量结果,包括与Visual Chat和GPT-4的相似程度、在Science QA上的SoTA准确率以及有关数据迭代和模型设计的消融研究。另一方面,Mini GPT-4缺乏定量结果......最后,应该说明的是,这条路线的重点是数据中心,而不是模型中心。随着模型之间的差异越来越小,数据质量对结果的影响越来越大。我们公开了我们的多模态指令跟随数据,以复制多模态GPT-4。”
LLaVA的源代码可在GitHub上获取,项目网站上提供交互式演示。LLaVA的训练数据和模型权重可在Huggingface上获取。该模型在LLaMA的基础上使用了增量权重,"不应该用于除研究目的之外的其他用途"。
来源:https://www.infoq.com/news/2023/05/microsoft-llava-chatbot/?topicPageSponsorship=0d3ead73-1914-40fe-bf33-ff2dbeb0a5be&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng
使用指令跟踪数据集微调大型语言模型(LLMs)的技术已经提高了性能,如ChatGPT所示,并促使研究人员探索这种技术在较小的LLMs中的应用。 InfoQ最近报道了LLaMA,与GPT-3的175B相比,它只有7B个参数,但在许多任务上可以超越GPT-3。人工智能助手发展的下一步是增加处理图像数据的能力,这在GPT-4和Visual ChatGPT的发布中得到了展示。
LLaVA团队的目标是通过视觉指令微调来端到端地训练模型。为此,研究人员从COCO数据集中提取了图像。由于这些图像附有标题和对象边界框的注释,团队将这些数据与提示一起输入到仅文本的GPT-4中,要求GPT-4输出指令跟踪数据,包括:人类用户和一个人工智能助手之间关于图像内容的虚拟对话 ,关于图像内容细节的问题,以及需要推理图像内容的问题。总体而言,生成的数据集包含158K个样本。
LLaVA
来自微软、威斯康星大学麦迪逊分校和哥伦比亚大学的研究人员已经开源了大型语言和视觉助手(LLaVA)。LLaVA基于CLIP图像编码器和LLaMA语言解码器,在合成指令遵循数据集上进行微调,并在Science QA基准测试中实现了最先进的准确性。
研究人员使用GPT-4生成指令跟踪数据集,其中包含人类用户和AI助手之间关于图像内容的虚拟对话。该数据集用于微调LLaVA模型,该模型由两个基础模型组成:用于视觉的CLIP和用于语言的LLaMA,以及将两者联系在一起的附加网络层。该团队还使用GPT-4来评估LLaVA在实验中的反应,要求它以1到10的等级对LLaVA的输出进行评分。当在ScienceQA训练数据集上进一步微调时,LLaVA的准确率达到了92.53%,创下了基准的新纪录。根据研究人员的说法,
本文演示了使用纯语言 GPT-4 进行可视化指令调整的有效性。我们提出了一个自动管道来创建语言 - 图像指令 - 跟随数据,在此基础上我们训练LLaVA,一个多模态模型,以遵循人类意图完成视觉任务。在对多模式聊天数据进行微调时,它实现了出色的视觉聊天体验。
正如ChatGPT所证明的那样,使用指令跟踪数据集微调大型语言模型(LLM)的技术已经提高了性能,并促使研究人员使用较小的LLM探索这种技术。 InfoQ最近报道了LLaMA,与GPT-7的3B相比,LLaMA只有175B参数,但在许多任务上可以胜过GPT-3。开发AI助手的下一步是增加处理图像数据的能力,如GPT-4和Visual ChatGPT的发布所示。
LLaVA 团队的目标是通过视觉指令调整来端到端地训练模型。为此,研究人员从从COCO数据集中提取的图像开始。由于图像带有标题和对象边界框的注释,因此团队将此数据输入纯文本 GPT-4 以及提示,要求 GPT-4 输出遵循指令的数据,包括:一个人和助手之间的想象对话、关于图像内容细节的问题,以及需要对图像内容进行推理的问题。总体而言,生成的数据集包含 158K 个样本。
LLaVA建筑.来源: https://arxiv.org/abs/2304.08485
LLaVA架构由一个CLIP基础模型和一个投影矩阵层组成,用于将图像转换为单词嵌入空间;文本输入也被转换为相同的空间。然后将图像和单词标记传递到LLaMA解码器,产生输出。预训练过程首先训练投影矩阵,然后微调过程更新投影层和LLaMA解码器权重;CLIP权重被冻结。
LLaVA的作者Chunyuan Li在Twitter上回答了一些有关这项工作的问题。当一些用户将LLaMA与MiniGPT-4进行比较时,Chunyuan Li指出LLaMA能够重现GPT-4论文的基于图像的结果,而MiniGPT-4则做不到。他还说:“LLaVA具有严格的定量结果,包括与Visual Chat和GPT-4的相似程度、在Science QA上的SoTA准确率以及有关数据迭代和模型设计的消融研究。另一方面,Mini GPT-4缺乏定量结果......最后,应该说明的是,这条路线的重点是数据中心,而不是模型中心。随着模型之间的差异越来越小,数据质量对结果的影响越来越大。我们公开了我们的多模态指令跟随数据,以复制多模态GPT-4。”
LLaVA的源代码可在GitHub上获取,项目网站上提供交互式演示。LLaVA的训练数据和模型权重可在Huggingface上获取。该模型在LLaMA的基础上使用了增量权重,"不应该用于除研究目的之外的其他用途"。
来源:https://www.infoq.com/news/2023/05/microsoft-llava-chatbot/?topicPageSponsorship=0d3ead73-1914-40fe-bf33-ff2dbeb0a5be&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消