











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI终于破解了数学密码
2023年06月02日 由 Camellia 发表
938700
0
OpenAI宣布了他们新的“过程监督”培训模式:提高数学水平,并带来更多的一致性。
长期以来在数学方面表现不佳之后,OpenAI昨天宣布,它已经提出了一种名为“过程监督”的新技术,可以提高数学推理能力。

这种新方法涉及奖励推理的每个步骤,而不是奖励“结果监督”中出现的正确最终答案。据说过程监督可以提高性能,还可以通过训练模型产生更接近人类思维的“思维链”模型来实现一致性。
OpenAI认为,有了过程监督,幻觉将在一定程度上被最小化。它说,过程中的每个步骤都受到精确的监督,这将产生更好的结果。
此外,OpenAI表示,奖励一致流程的方法将产生更多的“可解释推理”,因为模型被鼓励遵循人类批准的流程。简单地说,可解释推理侧重于创建透明的模型,并对其输出进行清晰的解释。
结果监督可能会奖励难以检测的不一致过程,与结果监督相反,过程监督不会面临此类问题。该公司还表示,解决幻觉问题是建立一致的通用人工智能的关键一步。
[caption id="attachment_51958" align="aligncenter" width="740"]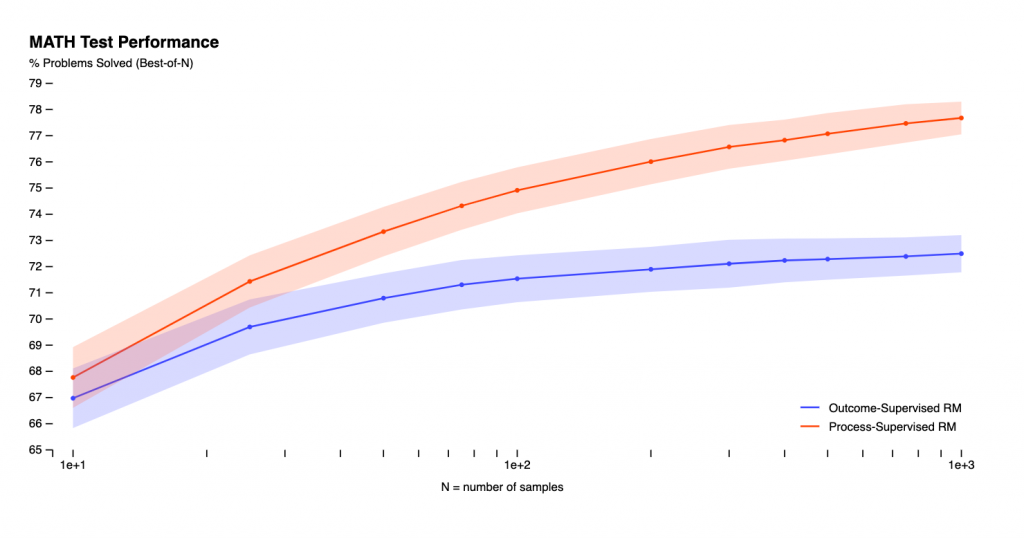 图片来源:OpenAI[/caption]
图片来源:OpenAI[/caption]
OpenAI在其博客文章中表示,它使用MATH测试集来评估过程监督和结果监督的奖励模型。此外,每个问题都会产生多个解决方案,并选出在每个奖励模型中排名最高的解决方案。我们观察到,过程监督的奖励模型不仅优于结果监督的奖励模型,而且当考虑更多问题的解决方案时,性能差距逐渐扩大,这表明该模型的可靠性。
通过减少幻觉并使他们的模型更加一致,OpenAI正在努力通过这种方法使他们的聊天机器人更加接近完美。然而,这些结果应用于数学以外的其他领域的范围仍然是未知的。OpenAI认为,如果过程监督也应用于其他领域,我们可能会得到一种比结果监督更优越、更一致的方法。
来源:https://analyticsindiamag.com/chatgpt-finally-gets-better-at-math/
长期以来在数学方面表现不佳之后,OpenAI昨天宣布,它已经提出了一种名为“过程监督”的新技术,可以提高数学推理能力。
这种新方法涉及奖励推理的每个步骤,而不是奖励“结果监督”中出现的正确最终答案。据说过程监督可以提高性能,还可以通过训练模型产生更接近人类思维的“思维链”模型来实现一致性。
减少幻觉
OpenAI认为,有了过程监督,幻觉将在一定程度上被最小化。它说,过程中的每个步骤都受到精确的监督,这将产生更好的结果。
此外,OpenAI表示,奖励一致流程的方法将产生更多的“可解释推理”,因为模型被鼓励遵循人类批准的流程。简单地说,可解释推理侧重于创建透明的模型,并对其输出进行清晰的解释。
结果监督可能会奖励难以检测的不一致过程,与结果监督相反,过程监督不会面临此类问题。该公司还表示,解决幻觉问题是建立一致的通用人工智能的关键一步。
提高数学成绩
[caption id="attachment_51958" align="aligncenter" width="740"]
图片来源:OpenAI[/caption]OpenAI在其博客文章中表示,它使用MATH测试集来评估过程监督和结果监督的奖励模型。此外,每个问题都会产生多个解决方案,并选出在每个奖励模型中排名最高的解决方案。我们观察到,过程监督的奖励模型不仅优于结果监督的奖励模型,而且当考虑更多问题的解决方案时,性能差距逐渐扩大,这表明该模型的可靠性。
通过减少幻觉并使他们的模型更加一致,OpenAI正在努力通过这种方法使他们的聊天机器人更加接近完美。然而,这些结果应用于数学以外的其他领域的范围仍然是未知的。OpenAI认为,如果过程监督也应用于其他领域,我们可能会得到一种比结果监督更优越、更一致的方法。
来源:https://analyticsindiamag.com/chatgpt-finally-gets-better-at-math/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消