











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






开源AI迎来新的支持者
2023年06月02日 由 daydream 发表
85712
0
当 Meta 公司的 LLaMA 代码泄漏到 GitHub 上时,全球的研究人员获得了首个 GPT 级别的大型语言模型(LLM)的访问权限。接着,一系列 LLM 推出,给开源人工智能注入了全新的维度。LLaMA 为斯坦福大学的 Alpaca 和 Vicuna-13B 等模型提供了舞台,从而成为了开源技术的代表。
不过,现在似乎出现了一个新的竞争者——Falcon。由阿联酋阿布扎比技术创新研究院(TII)开发,Falcon 的性能比 LLaMA 更出色。它有三个不同的变体,分别是 1B、7B 和 40B。

据该研究院称,FalconLM 是迄今为止最强大的开源语言模型。其中最大的变体 Falcon 40B,具有 40 亿个参数,相对于 LLaMA 的 650 亿个参数来说更小。高级技术研究委员会(ATRC)秘书长 Faisal Al Bannai 认为,Falcon 的发布将打破 LLM 的访问限制,让研究人员和企业家能够提供最具创新性的使用案例。
排行榜首位
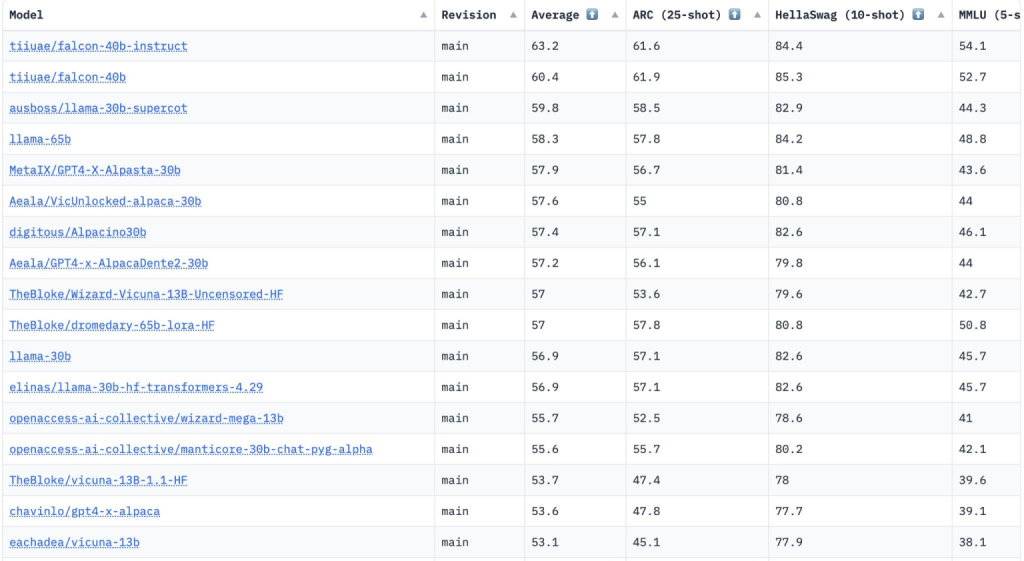
FalconLM 的两个变体,Falcon 40B Instruct 和 Falcon 40B,在 Hugging Face OpenLLM 排行榜上排名第一,而 Meta 的 LLaMA 排名第三。 Hugging Face 根据 AI2 Reasoning Challenge、HellaSwag、MMLU 和 TruthfulQA 这四个流行基准测试评估了这些模型的表现。
尽管 LLM 的论文尚未发布,但我们已经了解到,Falcon 40B 在庞大的数据集上进行了广泛的训练,其中包括经过精心筛选的 1 兆个 refined-web 数据集的令牌,以确保其质量和相关性。研究人员透露,特别注重在大规模情况下实现高质量的数据。众所周知,LLM 对它们的训练数据的质量非常敏感,因此投入了相当大的精力来构建一个能够在数以万计的 CPU 核心之间进行高效处理的数据管道。该管道旨在从网络中提取顶级内容,包括广泛的过滤和去重技术。
TII 发布了 refined-web 数据集,这是一个经过精心筛选和去重的数据集,被证明非常有效。仅使用这个数据集训练的模型可以匹配甚至超越仔细策划的语料库上训练的模型,展示了它们的卓越品质和影响力。
Falcon 模型还具有多语言能力。它可以理解英语、德语、西班牙语和法语,并在一些欧洲语言上具有有限的能力,例如荷兰语、意大利语、罗马尼亚语、葡萄牙语、捷克语、波兰语和瑞典语。此外,Falcon-40B是继H2O.ai模型发布之后的第二个真正的开源模型。然而,评估这两个模型变得具有挑战性,因为 H2O.ai 没有与此排行榜上的其他模型进行基准测试。
商业用途
尽管 LLAMA 的代码在 GitHub 上可用,但它的权重从未公开发布,因此商业用途受到了限制。此外,所有变体都依赖原始的LLAMA许可证,因此不适合小规模商业应用。
与此相反,Falcon使用修改后的Apache许可证,这意味着这些模型可以被微调并用于商业。Falcon 成为了第一个超越研究限制的开源大型语言模型。最初,该许可证规定在超过一百万美元的归属收入上缴默认版税 10%。然而,随后宣布Falcon已向Apache2.0许可证转变,消除了版税义务的需要。
与GPT-3相比,Falcon 取得了显著的性能提升,仅利用了训练计算预算的 75%,在推理时仅需要五分之一的计算量。此外,该模型利用了GPT-3的75%训练计算、Chinchilla的40%计算和PaLM-62B的80%计算,实现了计算资源的高效利用。
开源与封闭
虽然GPT-4是迄今为止最先进的LLM,但它是闭源的,OpenAI尚未透露有关模型架构、大小、硬件、训练计算、数据集构建、训练方法等的任何细节。这阻止了研究人员和开发人员了解模型的技术细节和内部工作原理。
相比之下,开源AI促进了该领域的协作、透明度和更大的创新。开源模型允许更大的协作和知识共享,这可以带来更快的进步和创新,正如我们自LLaMA推出以来所看到的那样。LLaMA的可用性使研究人员和开发人员能够访问强大的语言模型,而无需投资专有解决方案或昂贵的云资源。一些专家批评闭源模型缺乏透明度和潜在的偏见,因此开源模型提供了闭源模型的替代方案。
不过,现在似乎出现了一个新的竞争者——Falcon。由阿联酋阿布扎比技术创新研究院(TII)开发,Falcon 的性能比 LLaMA 更出色。它有三个不同的变体,分别是 1B、7B 和 40B。
据该研究院称,FalconLM 是迄今为止最强大的开源语言模型。其中最大的变体 Falcon 40B,具有 40 亿个参数,相对于 LLaMA 的 650 亿个参数来说更小。高级技术研究委员会(ATRC)秘书长 Faisal Al Bannai 认为,Falcon 的发布将打破 LLM 的访问限制,让研究人员和企业家能够提供最具创新性的使用案例。
排行榜首位
FalconLM 的两个变体,Falcon 40B Instruct 和 Falcon 40B,在 Hugging Face OpenLLM 排行榜上排名第一,而 Meta 的 LLaMA 排名第三。 Hugging Face 根据 AI2 Reasoning Challenge、HellaSwag、MMLU 和 TruthfulQA 这四个流行基准测试评估了这些模型的表现。
尽管 LLM 的论文尚未发布,但我们已经了解到,Falcon 40B 在庞大的数据集上进行了广泛的训练,其中包括经过精心筛选的 1 兆个 refined-web 数据集的令牌,以确保其质量和相关性。研究人员透露,特别注重在大规模情况下实现高质量的数据。众所周知,LLM 对它们的训练数据的质量非常敏感,因此投入了相当大的精力来构建一个能够在数以万计的 CPU 核心之间进行高效处理的数据管道。该管道旨在从网络中提取顶级内容,包括广泛的过滤和去重技术。
TII 发布了 refined-web 数据集,这是一个经过精心筛选和去重的数据集,被证明非常有效。仅使用这个数据集训练的模型可以匹配甚至超越仔细策划的语料库上训练的模型,展示了它们的卓越品质和影响力。
Falcon 模型还具有多语言能力。它可以理解英语、德语、西班牙语和法语,并在一些欧洲语言上具有有限的能力,例如荷兰语、意大利语、罗马尼亚语、葡萄牙语、捷克语、波兰语和瑞典语。此外,Falcon-40B是继H2O.ai模型发布之后的第二个真正的开源模型。然而,评估这两个模型变得具有挑战性,因为 H2O.ai 没有与此排行榜上的其他模型进行基准测试。
商业用途
尽管 LLAMA 的代码在 GitHub 上可用,但它的权重从未公开发布,因此商业用途受到了限制。此外,所有变体都依赖原始的LLAMA许可证,因此不适合小规模商业应用。
与此相反,Falcon使用修改后的Apache许可证,这意味着这些模型可以被微调并用于商业。Falcon 成为了第一个超越研究限制的开源大型语言模型。最初,该许可证规定在超过一百万美元的归属收入上缴默认版税 10%。然而,随后宣布Falcon已向Apache2.0许可证转变,消除了版税义务的需要。
与GPT-3相比,Falcon 取得了显著的性能提升,仅利用了训练计算预算的 75%,在推理时仅需要五分之一的计算量。此外,该模型利用了GPT-3的75%训练计算、Chinchilla的40%计算和PaLM-62B的80%计算,实现了计算资源的高效利用。
开源与封闭
虽然GPT-4是迄今为止最先进的LLM,但它是闭源的,OpenAI尚未透露有关模型架构、大小、硬件、训练计算、数据集构建、训练方法等的任何细节。这阻止了研究人员和开发人员了解模型的技术细节和内部工作原理。
相比之下,开源AI促进了该领域的协作、透明度和更大的创新。开源模型允许更大的协作和知识共享,这可以带来更快的进步和创新,正如我们自LLaMA推出以来所看到的那样。LLaMA的可用性使研究人员和开发人员能够访问强大的语言模型,而无需投资专有解决方案或昂贵的云资源。一些专家批评闭源模型缺乏透明度和潜在的偏见,因此开源模型提供了闭源模型的替代方案。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消