











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






十年风云变幻,人工智能如何改变了世界
2023年06月07日 由 Neo 发表
266699
0
过去十年对于人工智能(AI)领域来说是一段激动人心而又充满坎坷的旅程。对深度学习潜力的探索变成了一个爆炸性的热门领域,包括了从电子商务推荐系统到自动驾驶车辆的物体检测系统,再到能够生成逼真图像到连贯文本的一切生成模型。
在本文中,我们将沿着记忆之路走一走,重新审视一些让我们走到今天这一步的关键突破。无论你是经验丰富的 AI 从业者,还是只是对该领域的最新发展感兴趣,本文都将为你全面概述AI成为家喻户晓的发展历程。
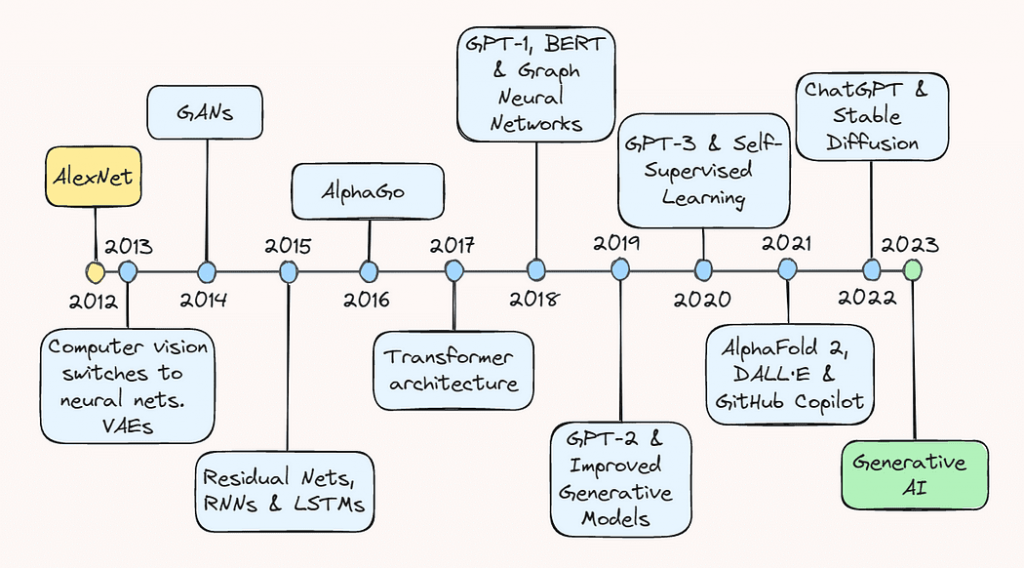
2013:AlexNet和变分自动编码器
2013年被广泛认为是深度学习的“成年礼”,主要由计算机视觉方面的重大进展引发。根据对杰弗里·辛顿(Geoffrey Hinton)的最近一次采访,到2013年“几乎所有的计算机视觉研究都转向了神经网络”。这一繁荣主要是由一年前在图像识别方面取得的一个令人惊讶的突破所推动的。
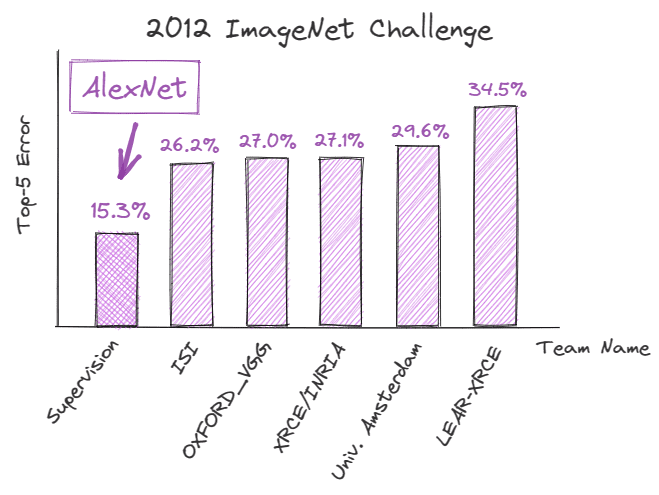
2012年9月,AlexNet,一个深度卷积神经网络(CNN),在ImageNet大规模视觉识别挑战(ILSVRC)中取得了创纪录的表现,展示了深度学习在图像识别任务中的潜力。它达到了仅有15.3%的错误率,比最接近的竞争者还低了10.9%。
这一成功背后的技术进步对AI的未来轨迹起到了至关重要的作用,也极大地改变了人们对深度学习的看法。
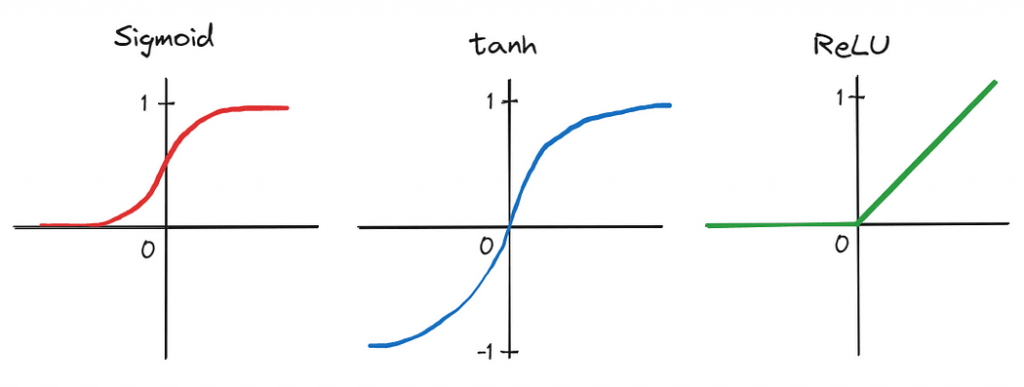
首先,作者应用了一个由五个卷积层和三个全连接线性层组成的深度卷积神经网络(CNN)——这是一个当时被许多人认为不切实际的架构设计。此外,由于网络深度产生的参数数量很大,训练是在两个图形处理单元(GPU)上并行进行的,展示了在大数据集上显著加速训练的能力。通过将传统的激活函数,如sigmoid和tanh,换成更高效的修正线性单元(ReLU),进一步缩短了训练时间。
这些共同导致AlexNet成功的进步标志着AI历史上的一个转折点,激发了学术界和科技界对深度学习的浓厚兴趣。因此,2013年被许多人认为是深度学习真正开始起飞的拐点。
同样发生在2013年,尽管有点被AlexNet的喧嚣所淹没了,但变分自编码器(VAE)的发展也同样重要。VAE是一种能够学习表示和生成数据(如图像和声音)的生成模型。他们通过学习输入数据在低维空间(即潜在空间)中的压缩表示来工作。这使得它们可以通过从这个学习到的潜在空间中采样来生成新的数据。VAE后来被证明为生成建模和数据生成开辟了新的途径,应用于艺术、设计和游戏等领域。
2014年:生成对抗网络
第二年,即2014年6月,深度学习领域又迎来了另一项重大进展,Ian Goodfellow和他的同事提出了生成对抗网络,或GAN。
GAN是一种能够生成与训练集相似的新数据样本的神经网络。本质上,同时训练两个网络:(1)一个生成器网络生成假的或合成的样本,(2)一个判别器网络评估它们的真实性。这种训练是在一个类似游戏的设置中进行的,生成器试图创建能够欺骗判别器的样本,而判别器则试图正确地识别出假样本。
当时,GAN代表了一种强大而新颖的数据生成工具,不仅用于生成图像和视频,还用于生成音乐和艺术。它们还促进了无监督学习的进步,这是一个被广泛认为是不发达和具有挑战性的领域,它们展示了在不依赖显式标签的情况下生成高质量数据样本的可能性。
2015年:ResNets和 NLP的突破
2015年,人工智能领域在计算机视觉和自然语言处理 (NLP) 方面取得了长足进步。
Kaiming He 及其同事发表了一篇 题为“图像识别的深度残差学习”的论文,其中他们介绍了残差神经网络或 ResNets 的概念——通过添加快捷方式让信息更容易地通过网络流动的架构。与常规神经网络中的每一层都将前一层的输出作为输入不同,在 ResNet 中, 添加了额外的残差连接,这些连接会跳过一个或多个层并直接连接到网络中的更深层。
因此,ResNets 能够解决 梯度消失的问题,这使得训练更深层的神经网络成为可能,这超出了当时认为的可能性。这反过来又导致图像分类和对象识别任务的显着改进。
大约在同一时间,研究人员在循环神经网络 ( RNN ) 和长短期记忆 ( LSTM ) 模型的开发方面取得了长足进步。尽管自 1990 年代以来就已经存在,但这些模型在 2015 年左右才开始引起轰动,主要是由于以下因素:(1) 可获得更大、更多样化的训练数据集,(2) 计算能力和硬件的改进,这能够训练更深入和更复杂的模型,以及 (3) 在此过程中进行的修改,例如更复杂的门控机制。
因此,这些架构使语言模型能够更好地理解文本的上下文和含义,从而极大地改进了语言翻译、文本生成和情感分析等任务。那个时候 RNN 和 LSTM 的成功为我们今天看到的大型语言模型 (LLM) 的发展铺平了道路。
2016:阿尔法围棋
在 1997 年加里·卡斯帕罗夫 (Garry Kasparov) 被 IBM 的深蓝 (Deep Blue) 击败后,另一场人机大战在 2016 年震惊了世界:谷歌的 AlphaGo 击败了围棋世界冠军李世石 (Lee Sedol)。

李世石的失败标志着 AI 发展轨迹的另一个重要里程碑:它表明,在曾经被认为过于复杂而计算机无法处理的游戏中,机器甚至可以胜过最熟练的人类玩家。AlphaGo结合 深度强化学习 和 蒙特卡洛树搜索,分析了之前游戏中的数百万个棋局,并评估了可能的最佳走法——这种策略在这种情况下远远超过了人类的决策。
2017:Transformer架构和语言模型
可以说,2017年是最具有里程碑意义的一年,为我们今天所见证的生成式人工智能的突破奠定了基础。
2017年12月,Vaswani和他的同事发表了开创性的论文“Attention is all you need”,介绍了利用自注意力概念来处理顺序输入数据的变换器架构。这使得对长距离依赖关系的更有效的处理成为可能,这之前一直是传统RNN架构的一个挑战。

Transformer 由两个基本组件组成:编码器和解码器。编码器负责对输入数据进行编码,例如,可以是一个单词序列。然后它获取输入序列并应用多层自注意力和前馈神经网络来捕获句子中的关系和特征并学习有意义的表示。
从本质上讲,self-attention 允许模型理解句子中不同单词之间的关系。与按固定顺序处理单词的传统模型不同,Transformers 实际上会同时检查所有单词。 他们根据每个词与句子中其他词的相关性,为每个词分配一种叫做 注意力分数的东西。
另一方面,解码器从编码器获取编码表示并产生输出序列。在机器翻译或文本生成等任务中,解码器根据从编码器接收到的输入生成翻译后的序列。与编码器类似,解码器也由多层自注意力和前馈神经网络组成。但是,它包含一个额外的注意力机制,使其能够专注于编码器的输出。然后,这允许解码器在生成输出时考虑来自输入序列的相关信息。
此后,Transformer 架构已成为 LLM 开发的关键组成部分,并导致 NLP 领域的重大改进,例如机器翻译、语言建模和问答。
2018:GPT-1、BERT 和图神经网络
在Vaswani等人发布论文的几个月后,OpenAI于2018年6月推出了G enerative P retrained Transformer,或者简称为 GPT-1。它利用 transformer 架构有效地捕获文本中的远程依赖关系。GPT-1 是首批证明无监督预训练有效性的模型之一,然后对特定 NLP 任务进行微调。
谷歌也利用了仍然相当新颖的 transformer 架构,他们在 2018 年底发布并开源了他们自己的预训练方法,称为 B idirectional Encoder R epresentations from Transformers,或 BERT。与以前以单向方式处理文本的模型(包括 GPT-1)不同,BERT 同时在两个方向上考虑每个单词的上下文。为了说明这一点,作者提供了一个非常直观的例子:
双向性的概念是如此强大,以至于它使BERT在各种基准任务上超越了最先进的自然语言处理系统。
除了GPT-1和BERT之外,图神经网络,或GNN,也在那一年引起了一些关注。它们属于一类专门设计用于处理图数据的神经网络。GNN利用消息传递算法在图的节点和边之间传播信息。这使得网络能够以一种更直观的方式学习数据的结构和关系。
这项工作使得从数据中获得更敏锐的洞察力成为可能,并因此扩大了深度学习可以应用的问题范围。借助GNN,社交网络分析、推荐系统和药物发现等领域取得了重大进展。
2019:GPT-2 和改进的生成模型
2019 年标志着生成模型取得了几项显着进步,尤其是GPT-2的引入 。通过在许多 NLP 任务中实现最先进的性能,该模型确实让同行望尘莫及,此外,它还能够生成高度逼真的文本,事后看来,这让我们对即将发生的事情有了一个预告。
该领域的其他改进包括 DeepMind 的 BigGAN和 NVIDIA 的StyleGAN,前者生成的高质量图像几乎与真实图像没有区别, 后者允许更好地控制这些生成图像的外观。
总的来说,这些现在被称为生成式AI的进步扩展了该领域的界限
2020年:GPT-3和自监督学习
此后不久,另一种模型诞生了,它甚至在科技界之外也已成为家喻户晓的名字: GPT-3。该模型代表了 LLM 的规模和能力的重大飞跃。综上所述,GPT-1 只有区区 1.17 亿个参数。对于 GPT-2,这个数字上升到 15 亿,对于 GPT-3,这个数字上升到 1750 亿。
大量的参数空间使 GPT-3 能够在各种提示和任务中生成非常连贯的文本。它还在各种 NLP 任务中展示了令人印象深刻的性能,例如文本完成、问题回答,甚至创意写作。
此外,GPT-3 再次强调了使用自我监督学习的潜力,它允许模型在大量未标记数据上进行训练。这样做的好处是,这些模型可以获得对语言的广泛理解,而无需进行大量针对特定任务的培训,这使其更加经济。
2021年:AlphaFold 2、DALL·E 和 GitHub Copilot
从蛋白质折叠到图像生成和自动编码辅助,2021年是一个多事之秋,这要归功于AlphaFold 2、DALL·E和GitHub Copilot的发布。
AlphaFold 2被誉为期待已久的数十年来蛋白质折叠问题的解决方案。DeepMind的研究人员扩展了变换器架构,创建了evoformer块——利用进化策略进行模型优化的架构——来构建一个能够根据其一维氨基酸序列预测蛋白质三维结构的模型。这一突破有巨大的潜力,可以革新药物发现、生物工程以及我们对生物系统的理解等领域。
OpenAI今年再次登上新闻头条,他们发布了DALL·E。从本质上讲,这个模型结合了GPT风格的语言模型和图像生成的概念,能够根据文本描述生成高质量的图像。
为了说明这个模型有多强大,参考下面的图片,它是根据“飞行汽车的未来世界的油画”这个提示生成的。

最后,GitHub发布了后来成为每个开发者的最好朋友的Copilot。这是与OpenAI合作实现的,OpenAI提供了底层的语言模型Codex,它是在大量公开可用的代码上进行训练的,并因此学会了理解和生成各种编程语言的代码。开发者可以通过简单地提供一个代码注释,说明他们想要解决的问题,然后模型就会建议代码来实现解决方案。其他功能包括能够用自然语言描述输入代码和在编程语言之间转换代码。
2022: ChatGPT和Stable Diffusion
AI 在过去十年的快速发展最终带来了突破性的进展:OpenAI 的 ChatGPT,这是一个聊天机器人,于 2022 年 11 月发布。该工具代表了 NLP 领域的前沿成就,能够生成连贯且与上下文相关的响应到范围广泛的查询和提示。此外,它还可以进行对话、提供解释、提供创意建议、协助解决问题、编写和解释代码,甚至可以模拟不同的性格或写作风格。

与机器人交互的简单直观的界面也刺激了使用性的急剧提高。以前,主要是科技界的人会玩弄最新的基于人工智能的发明。然而,如今,人工智能工具已经渗透到几乎每一个专业领域,从软件工程师到作家、音乐家和广告商。许多公司也使用这个模型来自动化诸如客户支持、语言翻译或回答常见问题等服务。事实上,我们看到的自动化浪潮重新引发了一些担忧,并激发了关于哪些工作可能面临被自动化的风险的讨论。
尽管ChatGPT在2022年占据了很大的关注度,但在图像生成方面也取得了重大进展。Stability AI发布了一种稳定扩散模型,这是一种潜在的文本到图像扩散模型,能够根据文本描述生成逼真的图像。
Stable diffusion是传统扩散模型的扩展,传统扩散模型通过迭代地向图像添加噪声,然后反转过程来恢复数据。它旨在通过不直接对输入图像进行操作,而是对它们的低维表示或潜在空间进行操作来加速这个过程。此外,扩散过程通过将用户提供的嵌入式文本提示添加到网络中来修改,从而使其能够在每次迭代中指导图像生成过程。
总体而言,ChatGPT和Stable Diffusion在2022年的发布突显了多模态、生成式人工智能的潜力,并引发了这一领域进一步发展和投资的巨大推动。
2023: LLMs和聊天机器人
毫无疑问,今年已经成为了LLMs和聊天机器人的年代。越来越多的模型正在以越来越快的速度开发和发布。
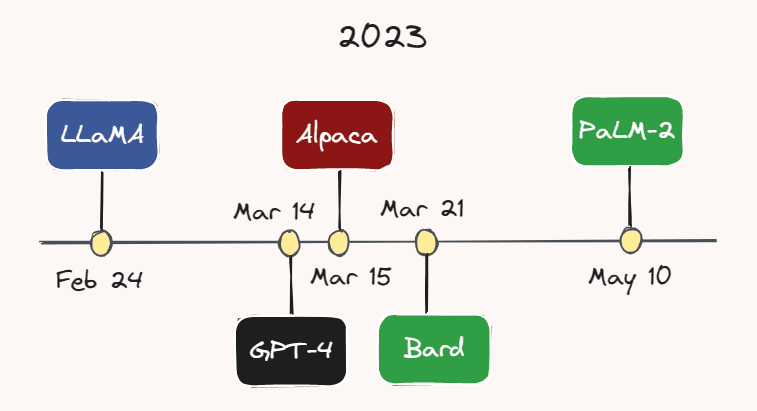
例如,2月24日,Meta AI发布了LLaMA—— 一种在大多数基准测试中优于GPT-3的LLM,尽管参数数量要少得多。不到一个月后,即3月14日,OpenAI 发布了GPT-4 ——GPT-3的更大、更强大的多模式版本。虽然 GPT-4的确切参数数量未知,但据推测有数万亿。
3 月 15 日,斯坦福大学的研究人员发布了 Alpaca,这是一种轻量级语言模型,它是从 LLaMA 在指令跟随演示中进行微调的。几天后,即 3 月 21 日,谷歌推出了其 ChatGPT 竞争对手:Bard。谷歌也刚刚于本月初的5月10日发布了其最新的 LLM, PaLM-2 。随着该领域的快速发展,很有可能在你阅读本文时又出现了另一种模型。
我们还看到越来越多的公司将这些模型融入到他们的产品中。例如,Duolingo 宣布了其基于 GPT-4 的 Duolingo Max,这是一个新的订阅层,旨在为每个人提供量身定制的语言课程。Slack 还推出了一款名为Slack GPT的人工智能助手 ,它可以做草稿回复或总结话题等事情。此外,Shopify 还为公司的 Shop 应用程序引入了一个支持 ChatGPT 的助手,它可以帮助客户使用各种提示识别所需的产品。
有趣的是,如今人工智能聊天机器人甚至被视为人类治疗师的替代品。例如,美国聊天机器人应用程序Replika正在为用户提供“关心的 AI 伴侣,总是在这里倾听和交谈,总是在你身边”。它的创始人Eugenia Kuyda表示,该应用程序拥有各种各样的客户,从自闭症儿童到寻求朋友的孤独成年人。
在我们结束之前,我想强调一下,这可能是过去十年人工智能发展的高潮:人们真的在使用必应!今年早些时候,微软推出了其基于GPT-4的“网络版copilot”,该版本的copilot专为搜索定制,并且首次成为了谷歌在搜索业务中长期占据主导地位的有力竞争者。
回顾与展望
回顾过去十年的 AI 发展,很明显,我们正在见证一场变革,这场变革对我们的工作、经商和互动方式产生了深远影响。生成模型(尤其是 LLM)最近取得的大部分重大进展似乎都秉承了“越大越好”的普遍信念,指的是模型的参数空间。这在 GPT 系列中尤为明显,该系列从 1.17 亿个参数 (GPT-1) 开始,并且在每个连续模型增加大约一个数量级之后,在 GPT-4 中达到顶峰,可能有数万亿个参数。
然而,根据最近的一次 采访,OpenAI CEO Sam Altman 认为我们已经到了“越大越好”时代的尽头。展望未来,他仍然认为参数数量会呈上升趋势,但未来模型改进的主要重点将放在提高模型的能力、实用性和安全性上。
后者尤为重要。考虑到这些强大的人工智能工具现在已经掌握在普通公众的手中,不再局限于研究实验室的受控环境,我们现在比以往任何时候都更需要谨慎行事,确保这些工具是安全的,并符合人类的最佳利益。希望我们能看到和其他领域一样多的人工智能安全方面的发展和投资。
来源:https://www.kdnuggets.com/2023/06/ten-years-ai-review.html
在本文中,我们将沿着记忆之路走一走,重新审视一些让我们走到今天这一步的关键突破。无论你是经验丰富的 AI 从业者,还是只是对该领域的最新发展感兴趣,本文都将为你全面概述AI成为家喻户晓的发展历程。
2013:AlexNet和变分自动编码器
2013年被广泛认为是深度学习的“成年礼”,主要由计算机视觉方面的重大进展引发。根据对杰弗里·辛顿(Geoffrey Hinton)的最近一次采访,到2013年“几乎所有的计算机视觉研究都转向了神经网络”。这一繁荣主要是由一年前在图像识别方面取得的一个令人惊讶的突破所推动的。
2012年9月,AlexNet,一个深度卷积神经网络(CNN),在ImageNet大规模视觉识别挑战(ILSVRC)中取得了创纪录的表现,展示了深度学习在图像识别任务中的潜力。它达到了仅有15.3%的错误率,比最接近的竞争者还低了10.9%。
这一成功背后的技术进步对AI的未来轨迹起到了至关重要的作用,也极大地改变了人们对深度学习的看法。
首先,作者应用了一个由五个卷积层和三个全连接线性层组成的深度卷积神经网络(CNN)——这是一个当时被许多人认为不切实际的架构设计。此外,由于网络深度产生的参数数量很大,训练是在两个图形处理单元(GPU)上并行进行的,展示了在大数据集上显著加速训练的能力。通过将传统的激活函数,如sigmoid和tanh,换成更高效的修正线性单元(ReLU),进一步缩短了训练时间。
这些共同导致AlexNet成功的进步标志着AI历史上的一个转折点,激发了学术界和科技界对深度学习的浓厚兴趣。因此,2013年被许多人认为是深度学习真正开始起飞的拐点。
同样发生在2013年,尽管有点被AlexNet的喧嚣所淹没了,但变分自编码器(VAE)的发展也同样重要。VAE是一种能够学习表示和生成数据(如图像和声音)的生成模型。他们通过学习输入数据在低维空间(即潜在空间)中的压缩表示来工作。这使得它们可以通过从这个学习到的潜在空间中采样来生成新的数据。VAE后来被证明为生成建模和数据生成开辟了新的途径,应用于艺术、设计和游戏等领域。
2014年:生成对抗网络
第二年,即2014年6月,深度学习领域又迎来了另一项重大进展,Ian Goodfellow和他的同事提出了生成对抗网络,或GAN。
GAN是一种能够生成与训练集相似的新数据样本的神经网络。本质上,同时训练两个网络:(1)一个生成器网络生成假的或合成的样本,(2)一个判别器网络评估它们的真实性。这种训练是在一个类似游戏的设置中进行的,生成器试图创建能够欺骗判别器的样本,而判别器则试图正确地识别出假样本。
当时,GAN代表了一种强大而新颖的数据生成工具,不仅用于生成图像和视频,还用于生成音乐和艺术。它们还促进了无监督学习的进步,这是一个被广泛认为是不发达和具有挑战性的领域,它们展示了在不依赖显式标签的情况下生成高质量数据样本的可能性。
2015年:ResNets和 NLP的突破
2015年,人工智能领域在计算机视觉和自然语言处理 (NLP) 方面取得了长足进步。
Kaiming He 及其同事发表了一篇 题为“图像识别的深度残差学习”的论文,其中他们介绍了残差神经网络或 ResNets 的概念——通过添加快捷方式让信息更容易地通过网络流动的架构。与常规神经网络中的每一层都将前一层的输出作为输入不同,在 ResNet 中, 添加了额外的残差连接,这些连接会跳过一个或多个层并直接连接到网络中的更深层。
因此,ResNets 能够解决 梯度消失的问题,这使得训练更深层的神经网络成为可能,这超出了当时认为的可能性。这反过来又导致图像分类和对象识别任务的显着改进。
大约在同一时间,研究人员在循环神经网络 ( RNN ) 和长短期记忆 ( LSTM ) 模型的开发方面取得了长足进步。尽管自 1990 年代以来就已经存在,但这些模型在 2015 年左右才开始引起轰动,主要是由于以下因素:(1) 可获得更大、更多样化的训练数据集,(2) 计算能力和硬件的改进,这能够训练更深入和更复杂的模型,以及 (3) 在此过程中进行的修改,例如更复杂的门控机制。
因此,这些架构使语言模型能够更好地理解文本的上下文和含义,从而极大地改进了语言翻译、文本生成和情感分析等任务。那个时候 RNN 和 LSTM 的成功为我们今天看到的大型语言模型 (LLM) 的发展铺平了道路。
2016:阿尔法围棋
在 1997 年加里·卡斯帕罗夫 (Garry Kasparov) 被 IBM 的深蓝 (Deep Blue) 击败后,另一场人机大战在 2016 年震惊了世界:谷歌的 AlphaGo 击败了围棋世界冠军李世石 (Lee Sedol)。
李世石的失败标志着 AI 发展轨迹的另一个重要里程碑:它表明,在曾经被认为过于复杂而计算机无法处理的游戏中,机器甚至可以胜过最熟练的人类玩家。AlphaGo结合 深度强化学习 和 蒙特卡洛树搜索,分析了之前游戏中的数百万个棋局,并评估了可能的最佳走法——这种策略在这种情况下远远超过了人类的决策。
2017:Transformer架构和语言模型
可以说,2017年是最具有里程碑意义的一年,为我们今天所见证的生成式人工智能的突破奠定了基础。
2017年12月,Vaswani和他的同事发表了开创性的论文“Attention is all you need”,介绍了利用自注意力概念来处理顺序输入数据的变换器架构。这使得对长距离依赖关系的更有效的处理成为可能,这之前一直是传统RNN架构的一个挑战。
Transformer 由两个基本组件组成:编码器和解码器。编码器负责对输入数据进行编码,例如,可以是一个单词序列。然后它获取输入序列并应用多层自注意力和前馈神经网络来捕获句子中的关系和特征并学习有意义的表示。
从本质上讲,self-attention 允许模型理解句子中不同单词之间的关系。与按固定顺序处理单词的传统模型不同,Transformers 实际上会同时检查所有单词。 他们根据每个词与句子中其他词的相关性,为每个词分配一种叫做 注意力分数的东西。
另一方面,解码器从编码器获取编码表示并产生输出序列。在机器翻译或文本生成等任务中,解码器根据从编码器接收到的输入生成翻译后的序列。与编码器类似,解码器也由多层自注意力和前馈神经网络组成。但是,它包含一个额外的注意力机制,使其能够专注于编码器的输出。然后,这允许解码器在生成输出时考虑来自输入序列的相关信息。
此后,Transformer 架构已成为 LLM 开发的关键组成部分,并导致 NLP 领域的重大改进,例如机器翻译、语言建模和问答。
2018:GPT-1、BERT 和图神经网络
在Vaswani等人发布论文的几个月后,OpenAI于2018年6月推出了G enerative P retrained Transformer,或者简称为 GPT-1。它利用 transformer 架构有效地捕获文本中的远程依赖关系。GPT-1 是首批证明无监督预训练有效性的模型之一,然后对特定 NLP 任务进行微调。
谷歌也利用了仍然相当新颖的 transformer 架构,他们在 2018 年底发布并开源了他们自己的预训练方法,称为 B idirectional Encoder R epresentations from Transformers,或 BERT。与以前以单向方式处理文本的模型(包括 GPT-1)不同,BERT 同时在两个方向上考虑每个单词的上下文。为了说明这一点,作者提供了一个非常直观的例子:
…在句子“我访问了银行账户”中,一个单向的上下文模型会根据“我访问了”来表示“银行”,但不会考虑“账户”。然而,BERT使用它的前后上下文来表示“银行”——“我访问了……账户”——从一个深层神经网络的最底层开始,使它深度双向。
双向性的概念是如此强大,以至于它使BERT在各种基准任务上超越了最先进的自然语言处理系统。
除了GPT-1和BERT之外,图神经网络,或GNN,也在那一年引起了一些关注。它们属于一类专门设计用于处理图数据的神经网络。GNN利用消息传递算法在图的节点和边之间传播信息。这使得网络能够以一种更直观的方式学习数据的结构和关系。
这项工作使得从数据中获得更敏锐的洞察力成为可能,并因此扩大了深度学习可以应用的问题范围。借助GNN,社交网络分析、推荐系统和药物发现等领域取得了重大进展。
2019:GPT-2 和改进的生成模型
2019 年标志着生成模型取得了几项显着进步,尤其是GPT-2的引入 。通过在许多 NLP 任务中实现最先进的性能,该模型确实让同行望尘莫及,此外,它还能够生成高度逼真的文本,事后看来,这让我们对即将发生的事情有了一个预告。
该领域的其他改进包括 DeepMind 的 BigGAN和 NVIDIA 的StyleGAN,前者生成的高质量图像几乎与真实图像没有区别, 后者允许更好地控制这些生成图像的外观。
总的来说,这些现在被称为生成式AI的进步扩展了该领域的界限
2020年:GPT-3和自监督学习
此后不久,另一种模型诞生了,它甚至在科技界之外也已成为家喻户晓的名字: GPT-3。该模型代表了 LLM 的规模和能力的重大飞跃。综上所述,GPT-1 只有区区 1.17 亿个参数。对于 GPT-2,这个数字上升到 15 亿,对于 GPT-3,这个数字上升到 1750 亿。
大量的参数空间使 GPT-3 能够在各种提示和任务中生成非常连贯的文本。它还在各种 NLP 任务中展示了令人印象深刻的性能,例如文本完成、问题回答,甚至创意写作。
此外,GPT-3 再次强调了使用自我监督学习的潜力,它允许模型在大量未标记数据上进行训练。这样做的好处是,这些模型可以获得对语言的广泛理解,而无需进行大量针对特定任务的培训,这使其更加经济。
2021年:AlphaFold 2、DALL·E 和 GitHub Copilot
从蛋白质折叠到图像生成和自动编码辅助,2021年是一个多事之秋,这要归功于AlphaFold 2、DALL·E和GitHub Copilot的发布。
AlphaFold 2被誉为期待已久的数十年来蛋白质折叠问题的解决方案。DeepMind的研究人员扩展了变换器架构,创建了evoformer块——利用进化策略进行模型优化的架构——来构建一个能够根据其一维氨基酸序列预测蛋白质三维结构的模型。这一突破有巨大的潜力,可以革新药物发现、生物工程以及我们对生物系统的理解等领域。
OpenAI今年再次登上新闻头条,他们发布了DALL·E。从本质上讲,这个模型结合了GPT风格的语言模型和图像生成的概念,能够根据文本描述生成高质量的图像。
为了说明这个模型有多强大,参考下面的图片,它是根据“飞行汽车的未来世界的油画”这个提示生成的。
最后,GitHub发布了后来成为每个开发者的最好朋友的Copilot。这是与OpenAI合作实现的,OpenAI提供了底层的语言模型Codex,它是在大量公开可用的代码上进行训练的,并因此学会了理解和生成各种编程语言的代码。开发者可以通过简单地提供一个代码注释,说明他们想要解决的问题,然后模型就会建议代码来实现解决方案。其他功能包括能够用自然语言描述输入代码和在编程语言之间转换代码。
2022: ChatGPT和Stable Diffusion
AI 在过去十年的快速发展最终带来了突破性的进展:OpenAI 的 ChatGPT,这是一个聊天机器人,于 2022 年 11 月发布。该工具代表了 NLP 领域的前沿成就,能够生成连贯且与上下文相关的响应到范围广泛的查询和提示。此外,它还可以进行对话、提供解释、提供创意建议、协助解决问题、编写和解释代码,甚至可以模拟不同的性格或写作风格。
与机器人交互的简单直观的界面也刺激了使用性的急剧提高。以前,主要是科技界的人会玩弄最新的基于人工智能的发明。然而,如今,人工智能工具已经渗透到几乎每一个专业领域,从软件工程师到作家、音乐家和广告商。许多公司也使用这个模型来自动化诸如客户支持、语言翻译或回答常见问题等服务。事实上,我们看到的自动化浪潮重新引发了一些担忧,并激发了关于哪些工作可能面临被自动化的风险的讨论。
尽管ChatGPT在2022年占据了很大的关注度,但在图像生成方面也取得了重大进展。Stability AI发布了一种稳定扩散模型,这是一种潜在的文本到图像扩散模型,能够根据文本描述生成逼真的图像。
Stable diffusion是传统扩散模型的扩展,传统扩散模型通过迭代地向图像添加噪声,然后反转过程来恢复数据。它旨在通过不直接对输入图像进行操作,而是对它们的低维表示或潜在空间进行操作来加速这个过程。此外,扩散过程通过将用户提供的嵌入式文本提示添加到网络中来修改,从而使其能够在每次迭代中指导图像生成过程。
总体而言,ChatGPT和Stable Diffusion在2022年的发布突显了多模态、生成式人工智能的潜力,并引发了这一领域进一步发展和投资的巨大推动。
2023: LLMs和聊天机器人
毫无疑问,今年已经成为了LLMs和聊天机器人的年代。越来越多的模型正在以越来越快的速度开发和发布。
例如,2月24日,Meta AI发布了LLaMA—— 一种在大多数基准测试中优于GPT-3的LLM,尽管参数数量要少得多。不到一个月后,即3月14日,OpenAI 发布了GPT-4 ——GPT-3的更大、更强大的多模式版本。虽然 GPT-4的确切参数数量未知,但据推测有数万亿。
3 月 15 日,斯坦福大学的研究人员发布了 Alpaca,这是一种轻量级语言模型,它是从 LLaMA 在指令跟随演示中进行微调的。几天后,即 3 月 21 日,谷歌推出了其 ChatGPT 竞争对手:Bard。谷歌也刚刚于本月初的5月10日发布了其最新的 LLM, PaLM-2 。随着该领域的快速发展,很有可能在你阅读本文时又出现了另一种模型。
我们还看到越来越多的公司将这些模型融入到他们的产品中。例如,Duolingo 宣布了其基于 GPT-4 的 Duolingo Max,这是一个新的订阅层,旨在为每个人提供量身定制的语言课程。Slack 还推出了一款名为Slack GPT的人工智能助手 ,它可以做草稿回复或总结话题等事情。此外,Shopify 还为公司的 Shop 应用程序引入了一个支持 ChatGPT 的助手,它可以帮助客户使用各种提示识别所需的产品。
有趣的是,如今人工智能聊天机器人甚至被视为人类治疗师的替代品。例如,美国聊天机器人应用程序Replika正在为用户提供“关心的 AI 伴侣,总是在这里倾听和交谈,总是在你身边”。它的创始人Eugenia Kuyda表示,该应用程序拥有各种各样的客户,从自闭症儿童到寻求朋友的孤独成年人。
在我们结束之前,我想强调一下,这可能是过去十年人工智能发展的高潮:人们真的在使用必应!今年早些时候,微软推出了其基于GPT-4的“网络版copilot”,该版本的copilot专为搜索定制,并且首次成为了谷歌在搜索业务中长期占据主导地位的有力竞争者。
回顾与展望
回顾过去十年的 AI 发展,很明显,我们正在见证一场变革,这场变革对我们的工作、经商和互动方式产生了深远影响。生成模型(尤其是 LLM)最近取得的大部分重大进展似乎都秉承了“越大越好”的普遍信念,指的是模型的参数空间。这在 GPT 系列中尤为明显,该系列从 1.17 亿个参数 (GPT-1) 开始,并且在每个连续模型增加大约一个数量级之后,在 GPT-4 中达到顶峰,可能有数万亿个参数。
然而,根据最近的一次 采访,OpenAI CEO Sam Altman 认为我们已经到了“越大越好”时代的尽头。展望未来,他仍然认为参数数量会呈上升趋势,但未来模型改进的主要重点将放在提高模型的能力、实用性和安全性上。
后者尤为重要。考虑到这些强大的人工智能工具现在已经掌握在普通公众的手中,不再局限于研究实验室的受控环境,我们现在比以往任何时候都更需要谨慎行事,确保这些工具是安全的,并符合人类的最佳利益。希望我们能看到和其他领域一样多的人工智能安全方面的发展和投资。
来源:https://www.kdnuggets.com/2023/06/ten-years-ai-review.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
你必须了解的十大自主AI代理








广告


写评论取消
回复取消