











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从零开始打造语义搜索引擎:构建嵌入式模型
2023年06月13日 由 Alex 发表
156029
0
我们将从BERT和sentence-transformers开始,通过BEIR等语义搜索基准、 SGPT和E5等现代模型,最后构建我们的玩具嵌入模型。
语义搜索的问题
语义搜索系统的基本设计,正如大多数矢量搜索供应商所宣传的那样,有两个简单的(这很讽刺)步骤:
1.计算文档和查询的嵌入。在某处。在某种程度上。自己想办法。
2.将它们上传到矢量搜索引擎,享受更好的语义搜索。
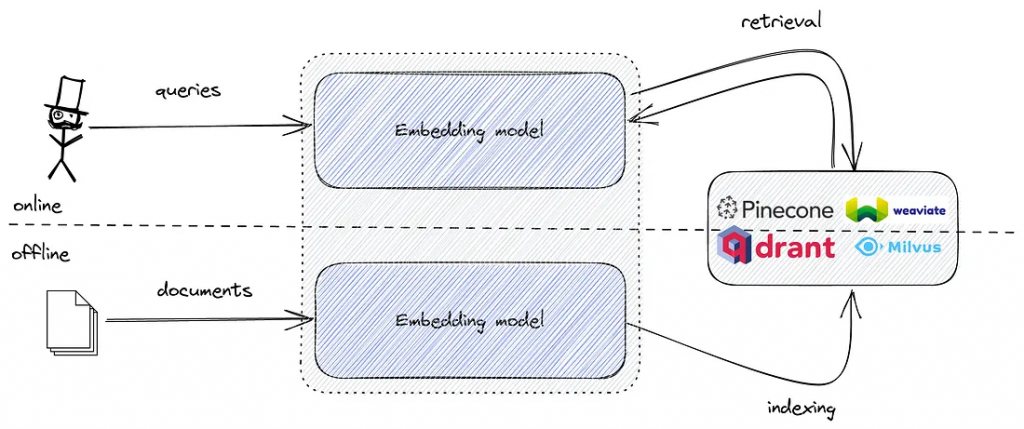
您的语义搜索和您的嵌入模型一样好,但选择模型通常被认为不在大多数早期采用者的范围之内。因此,每个人都使用sentence-transformers/all-MiniLM-L6-v2,希望能够获得最好的效果。
但这种方法有更多开放性问题而不是答案:
1.嵌入模型之间有区别吗?OpenAI和Cohere的付费模型更好吗?
2.他们如何处理多种语言?大型1B+模型有什么好处吗?
3.基于嵌入的密集检索是众多语义搜索方法之一。它比SPLADEv2和ELSER等新时代的稀疏方法更好吗?
嵌入式的兔子洞
我们将专注于选择并构建最好的语义搜索嵌入模型。目前的计划:
1.嵌入模型简介。基线嵌入,如BERT、MiniLM、DeBERTaV3和GPT-*系列。如何用BEIR基准来评估嵌入质量?目前的BEIR获奖者及其优缺点。
2.解剖sentence-transformers / all-MiniLM-L6-v2。为什么是MiniLM而不是BERT?训练过程,1B句子对数据集,以及如此小而古老的模型如何在BEIR基准上表现如此出色。
3.超越MiniLM-L6-v2与microsoft/E5。将所有LLM的最新进展整合到一个语义搜索模型中:数据集去噪、非对称嵌入和额外的IR微调。能否进一步改进?
4.DIY 嵌入,一个零样本 metarank-v0 模型。将MiniLM和E5的所有优点结合到一个带有一些额外秘诀的模型中。去噪和训练数据准备。我们能在一台RTX 4090上安装和训练它吗?
5.DIY 嵌入,微调的 metarank-v1 模型。E5在MS MARCO+SNLI上微调。然后我们可以对完整的BEIR设置进行微调吗?我们能让它多语言化吗?
Transformer:所有LLM的祖先
原始的Transformer体系结构可以看作是一个将输入文本转换为输出文本的黑盒。但神经网络本身并不理解文本;它们只说数字——所有的内部转换都是数字的。
Transformer 由两个主要模块组成:
1.编码器:以数字形式接收文本输入,并生成输入语义的嵌入表示。
2.解码器:逆过程,采取嵌入,并预测下一个文本标记。
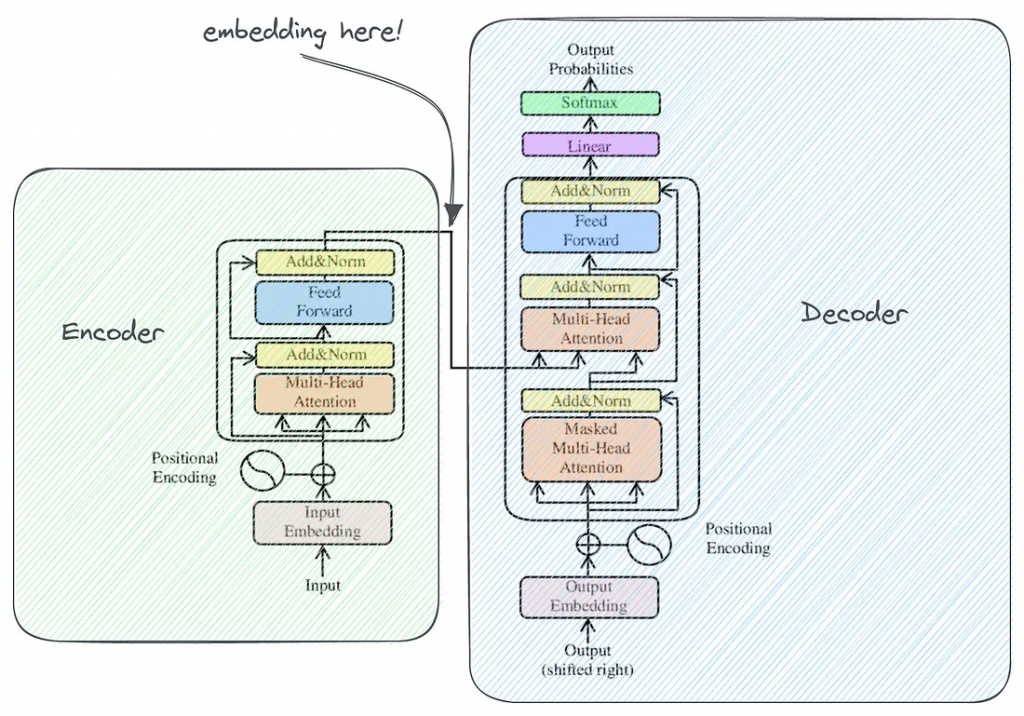
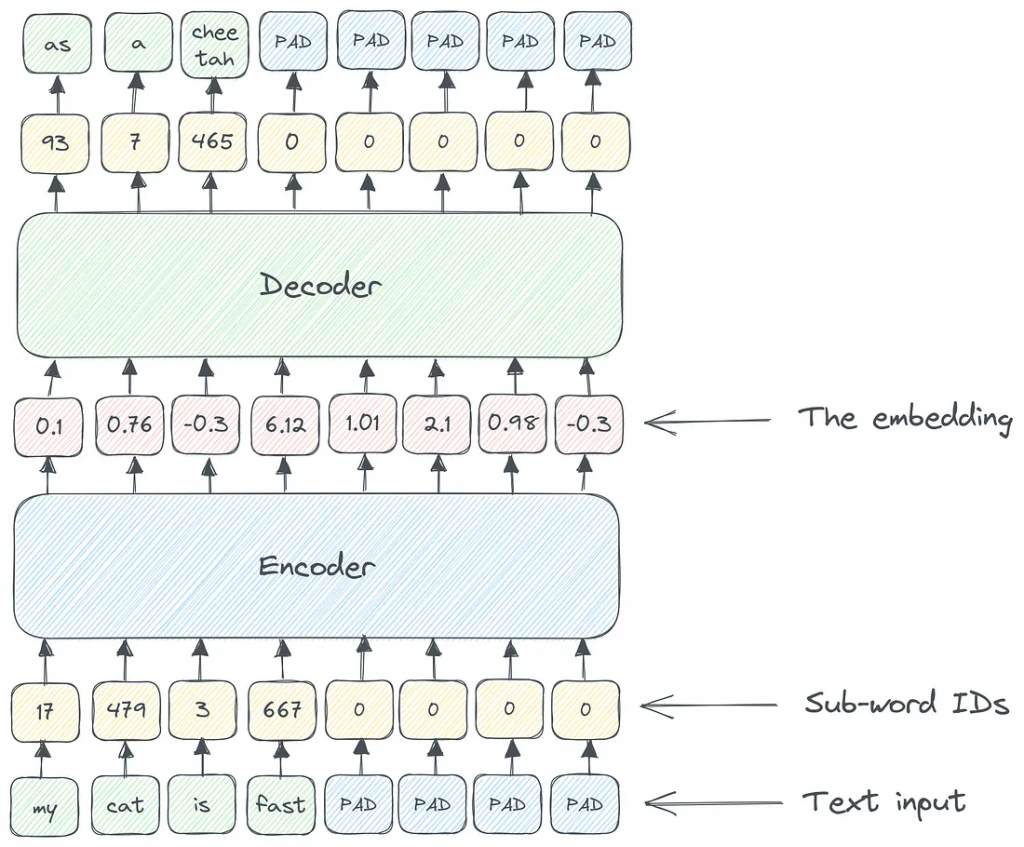
所以在编码器和解码器之间,有一个输入的嵌入表示。input和embedding都是数值向量,但两者仍有显著区别:
1.输入向量只是来自预定义字典(对于BERT,词汇表大小为32K)的术语标识符序列,填充为固定长度。
2.嵌入向量是输入的内部表示。这就是网络如何看待你的输入。你可能会认为类似的文档会有类似的内部表示。
几年后,出现了一个充满活力的基于transformer的不同文本处理模型系列,其中有两个主要的独立分支:
1.BERT-like,只使用transformer的编码器部分。擅长分类、总结和实体识别。
2.GPT系列,只有解码器。擅长翻译、QA等生成任务。
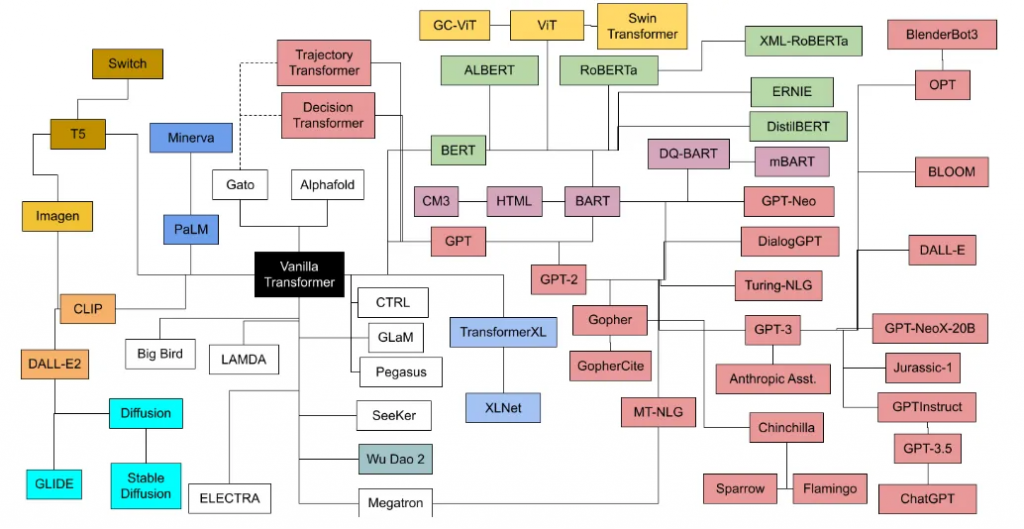
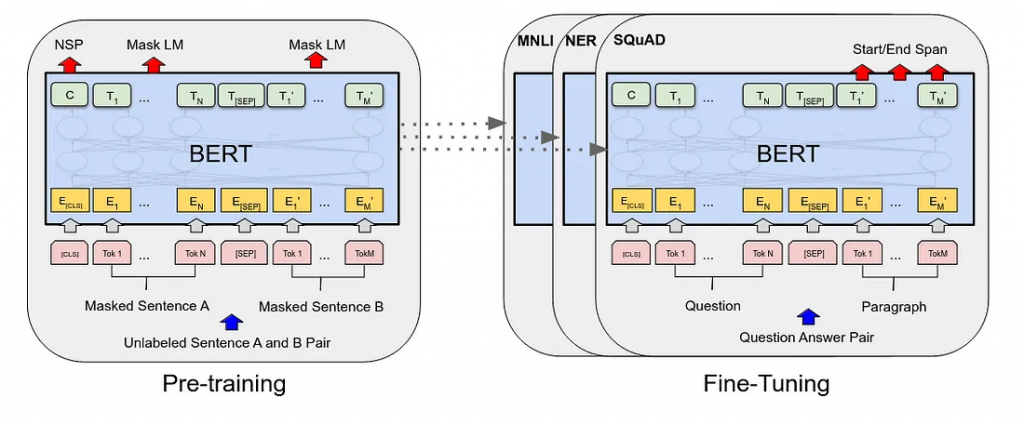
在上面的图像中,您可以看到BERT和GPT模型子系列之间的分裂。传统上,BERT子代最常用于语义搜索领域。
BERT模型
BERT模型似乎很适合我们的语义搜索问题,因为它可以简化为针对特定查询的相关和不相关文档的二元分类任务。
但是BERT嵌入最初并不是为了语义相似性:该模型被训练来预测大型文本语料库上的被屏蔽词。相似的文本有相似的嵌入,这是一个很好的自发副作用。
但“最初不是为语义相似性而设计”只是一种观点。是否有一种方法可以客观地衡量参考数据集的好坏?
BEIR基准
学术论文“BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models”为IR方法提供了一套参考基准和数据集。这让模型质量之争变得不那么有趣了,现在有了一个排行榜来比较你的嵌入模型和竞争对手。

BEIR基准提出了一组19个不同的IR数据集和所有用于搜索质量评估的机制。
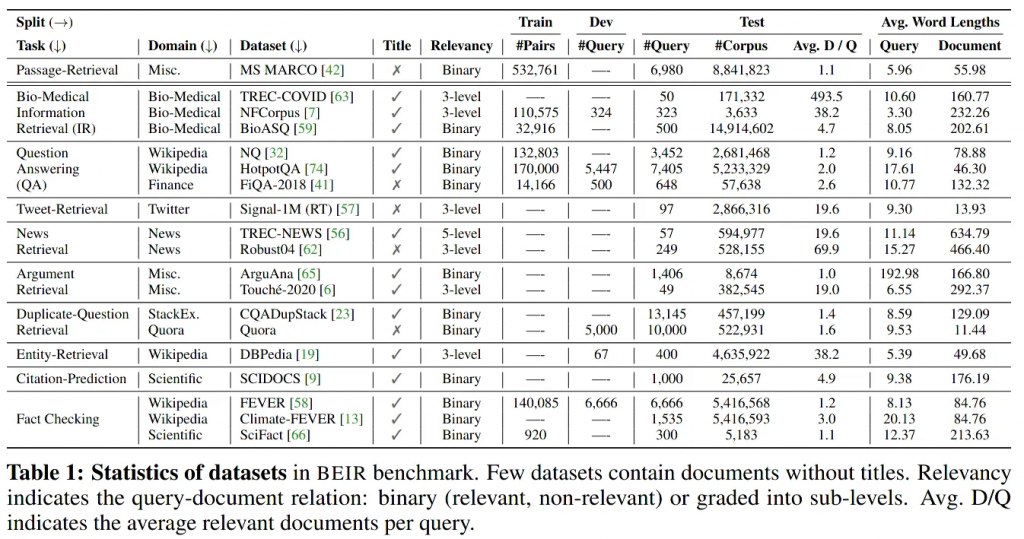
原始论文还在整个数据集上对几个基线方法进行了基准测试。2021年得出的主要结论是,BM25是一个棘手的问题,也是一个强有力的基线。
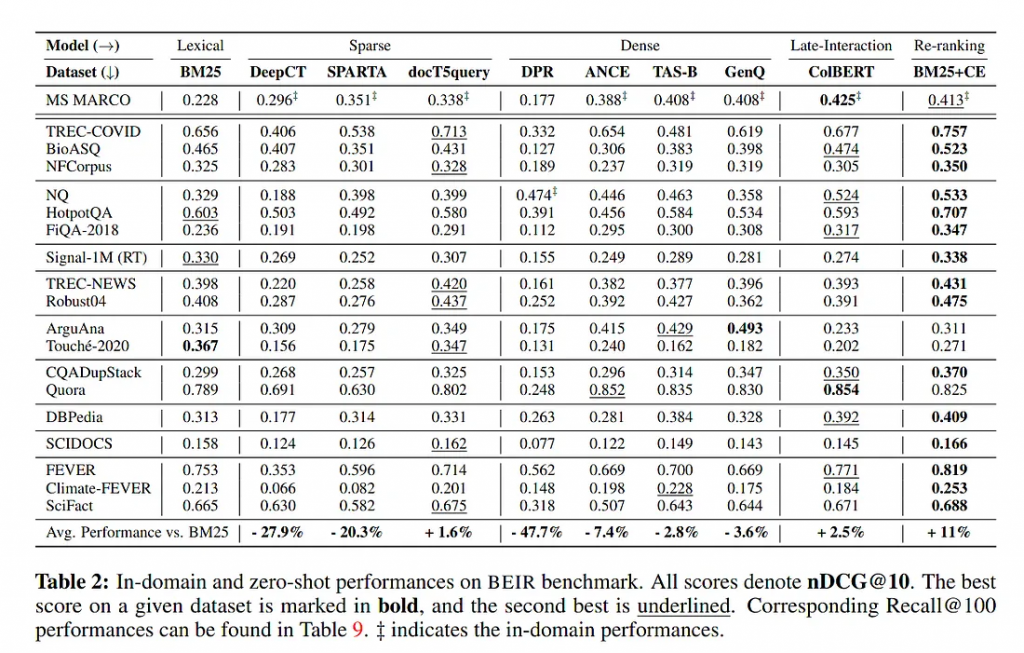
后来,BEIR被合并到一个更广泛的基准套件中:MTEB,Massive Text Embedding Benchmark。运行它很容易(如果你有128GB的内存,现代GPU和8小时的空闲时间):
让我们回到“原始BERT嵌入不适用于语义搜索”的论点。如果我们在BEIR/MTEB基准测试中将bert-base-uncased与顶级句子转换器模型all-MiniLM-L6-v2和all-mpnet-base-v2 并排运行,我们将看到以下数字:
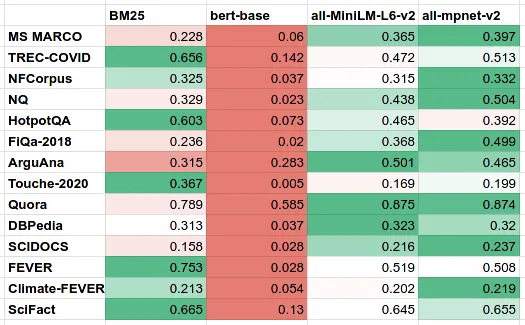
从这张表我们可以得出两个明显的结论:
1.原始的BERT嵌入是为了预测下一个单词,而不是为了语义搜索和文档相似度。现在你可以知道为什么了。
2.BM25仍然是一个强大的基线——即使是针对语义相似性进行了调整的大型MPNET模型也无法始终优于它。
但是为什么相似的嵌入模型在语义搜索任务上如此不同呢?
排行榜
目前(2023年6月)MTEB/BEIR基准的排行榜上似乎都是不知名的名字:
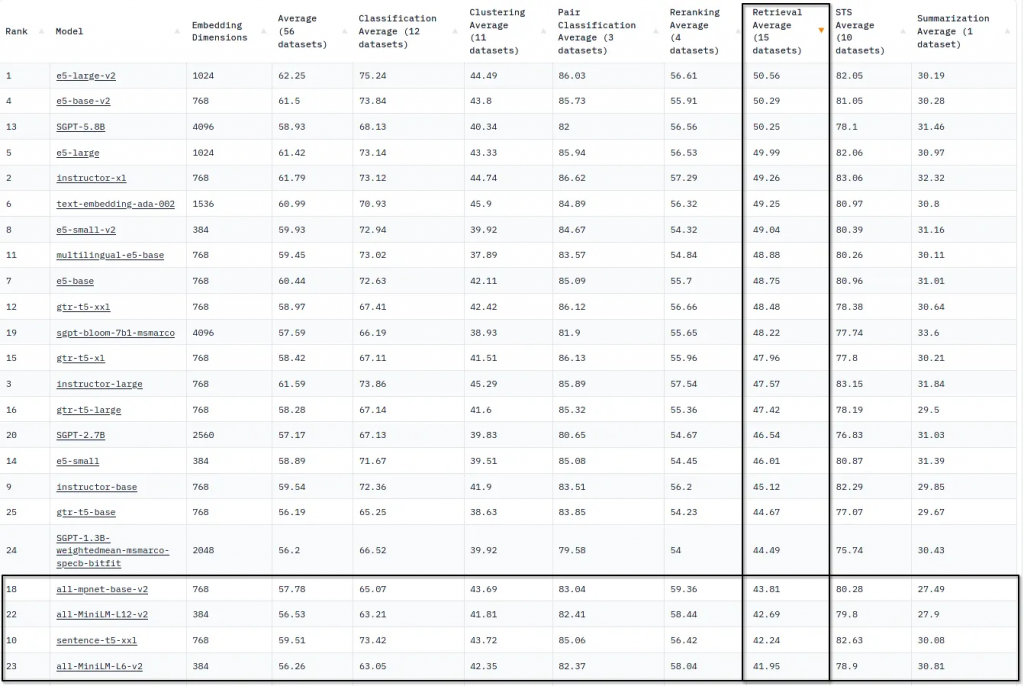
我们可以用以下方式总结当前最先进的语义搜索:
1.SBERT模型(all-MiniLM-L6-v2、all-MiniLM-L12-v2和all-mpnet-base-v2)在简单性和排名质量之间取得了很好的平衡。
2.SGPT (5.8B, 2.7B, 1.3B)是基于LoRa优化的开源GPT-NeoX排名模型的最新版本。
3.GTR-T5是Google的开源语义搜索嵌入模型,以T5 LLM为基础。
4.E5 (v1和v2)是Microsoft最新的嵌入模型。
我们可以通过构建语义搜索模型的两种哲学来看待这四个模型族:
1.性能。模型越小,搜索延迟越低,索引速度越快。巨大的SGPT和GTR模型只能在昂贵的GPU上运行。
2.大小。模型中参数数量越多,检索质量越好。all- minilm-l6-v2是一个非常棒的模型,但是它太小了,无法用10M参数捕获搜索中的所有语义差异。
在大小和性能之间找到平衡对于构建优秀的嵌入模型至关重要。
嵌入与稀疏检索
嵌入是众多搜索方式中的一种。旧的BM25仍然是一个强大的基线,还有一些新的“稀疏”检索方法,如SPLADEv2和ColBERT,它们结合了术语搜索和神经网络的优势。
在下表中,试图汇总以下来源的所有公开可用的 BEIR 分数:
1.MTEB结果存储库包含排行榜中使用的所有原始分数。它还包括OpenAI商业嵌入的分数,包括最新的ada-2模型。
2.ColBERT, SPLADEv2和BEIR论文的ArXiv预印本。
3.Vespa的ColBERT实施和Elastic的ELSER的博文。
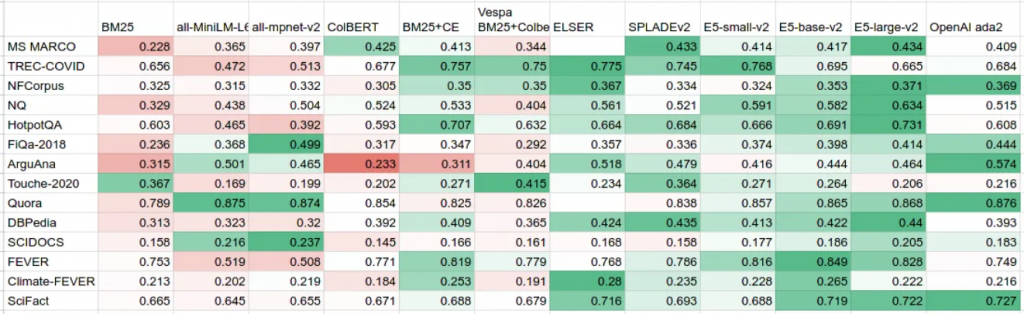
如果将这张表与两年前发布的BEIR表进行比较,你可能会注意到BM25被认为是一个强有力的基线——但BM25在2023年不再是一个明显的赢家。
另一个观察结果是稀疏(例如:ELSER和SPLADEv2)和密集(E5)检索方法在质量上非常接近。因此,在这个领域没有明显的赢家,但看到如此激烈的竞争是件很棒的。
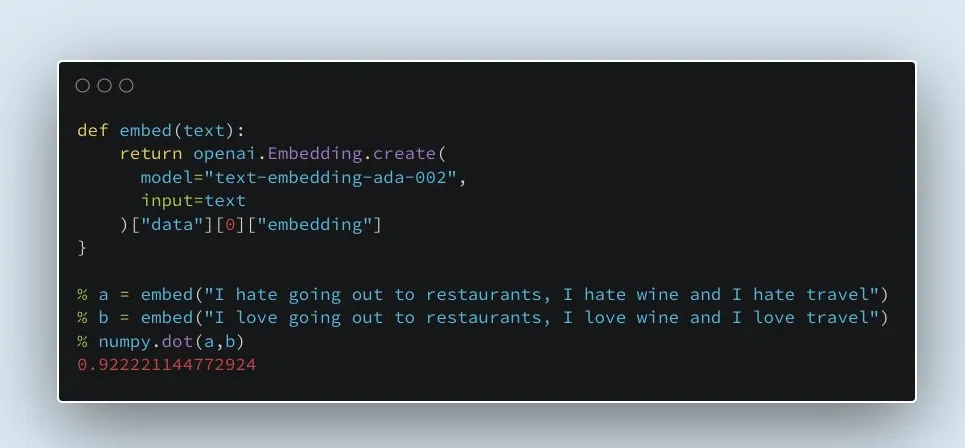
对稀疏与密集检索方法之争的个人看法:
1.密集检索更具前瞻性。从SBERT升级到E5只需要10行代码,这大大提高了检索质量。矢量搜索引擎保持不变,不需要额外的工程设计。
2.稀疏检索产生的幻觉较少,可以处理精确匹配和关键字匹配。NDCG@10并不是衡量搜索质量的唯一标准。
但辩论仍在进行中,我们将随时为您提供最新消息。
大型模型的隐性成本
有一个普遍的观点认为,模型越大,检索质量越好。从MTEB排行榜可以清楚地看出这一点,但它忽略了为这些模式提供服务是简单和廉价的重要和实用特征。
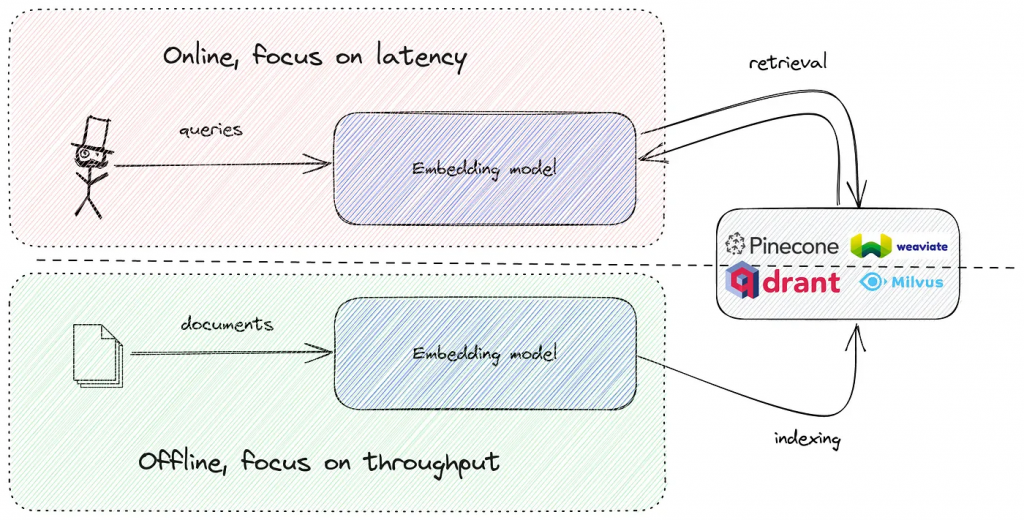
在实践中,你需要运行嵌入模型两次:
1.在索引阶段脱机。这是一个批处理作业,需要高吞吐量,但对延迟不敏感。
2.在线嵌入搜索查询,对每个搜索请求。
像SBERT和E5这样的小型模型可以在合理的延迟预算内轻松地在CPU上运行,但是如果超过500M参数(SGPT就是这种情况),则无法避免使用GPU。而且GPU现在很贵。
为了查看真实的延迟数字,我们为ONNX推理制作了一个基于JVM的小型基准测试。
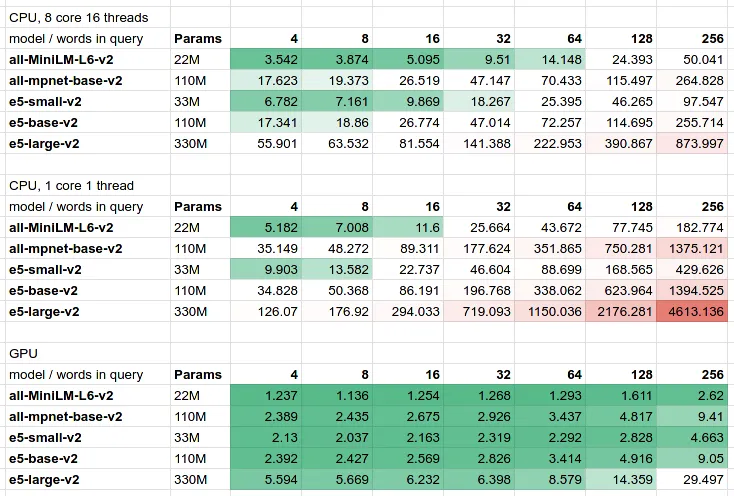
从表格中可以看出:
1.在CPU和GPU上,参数数量和延迟之间存在线性依赖关系。像SGPT-1.3B这样的大型模型对于简短的4字查询的估计延迟应该是200ms,这对于面向客户的工作负载来说通常太大了。
2.存在延迟/成本/质量的权衡。你的语义搜索是快速、廉价、精确的——任选其二。
不只有英语
世界上不只是说英语。但大多数模型和评估框架只关注英语:
1.原始的BERT词汇表主要是在英语数据上训练的,在其他语言上很弱。
2.几乎所有的嵌入模型都是在英语文本语料库上训练的,所以它们都有轻微的偏向。
如果您向BERT 分词器提供非英语文本,则会发生这种情况:
BERT分词器不能正确地将德语单词作为单独的标记处理,必须将其拆分为子单词。相比之下,多语言XLM标记器对相同句子的处理要好得多。
幸运的是,本文中提到的大多数模型都有多语言版本:
1.E5: multilingual- E5 -base,是多语言XLM-Roberta-base的对齐版本。
2.SGPT: SGPT - BLOOM,它基于BLOOM模型。
3.SBERT:基于mUSE的多语言MiniLM-L12-v2。
这些模型是通过知识提炼过程产生的,因此它们不需要专门的多语言相似句子训练数据集。
综上所述,本章的主要结论如下:
1.要在搜索质量上超越BM25并不容易。考虑到它不需要调优,你可以在3分钟内生成一个Elasticsearch/OpenSearch集群——在2023年依赖它仍然是实用的。
2.最近在稀疏和密集检索领域都有很多进展。SGPT和E5不到1年,而SPLADE和ELSER则更年轻。
3.稀疏/密集方法之间没有单一的赢家,但是IR行业融合成一个单一的基准测试工具,使用MTEB/BEIR套件来衡量检索质量。
来源:https://medium.com/metarank/from-zero-to-semantic-search-embedding-model-592e16d94b61
语义搜索的问题
语义搜索系统的基本设计,正如大多数矢量搜索供应商所宣传的那样,有两个简单的(这很讽刺)步骤:
1.计算文档和查询的嵌入。在某处。在某种程度上。自己想办法。
2.将它们上传到矢量搜索引擎,享受更好的语义搜索。
您的语义搜索和您的嵌入模型一样好,但选择模型通常被认为不在大多数早期采用者的范围之内。因此,每个人都使用sentence-transformers/all-MiniLM-L6-v2,希望能够获得最好的效果。
但这种方法有更多开放性问题而不是答案:
1.嵌入模型之间有区别吗?OpenAI和Cohere的付费模型更好吗?
2.他们如何处理多种语言?大型1B+模型有什么好处吗?
3.基于嵌入的密集检索是众多语义搜索方法之一。它比SPLADEv2和ELSER等新时代的稀疏方法更好吗?
嵌入式的兔子洞
我们将专注于选择并构建最好的语义搜索嵌入模型。目前的计划:
1.嵌入模型简介。基线嵌入,如BERT、MiniLM、DeBERTaV3和GPT-*系列。如何用BEIR基准来评估嵌入质量?目前的BEIR获奖者及其优缺点。
2.解剖sentence-transformers / all-MiniLM-L6-v2。为什么是MiniLM而不是BERT?训练过程,1B句子对数据集,以及如此小而古老的模型如何在BEIR基准上表现如此出色。
3.超越MiniLM-L6-v2与microsoft/E5。将所有LLM的最新进展整合到一个语义搜索模型中:数据集去噪、非对称嵌入和额外的IR微调。能否进一步改进?
4.DIY 嵌入,一个零样本 metarank-v0 模型。将MiniLM和E5的所有优点结合到一个带有一些额外秘诀的模型中。去噪和训练数据准备。我们能在一台RTX 4090上安装和训练它吗?
5.DIY 嵌入,微调的 metarank-v1 模型。E5在MS MARCO+SNLI上微调。然后我们可以对完整的BEIR设置进行微调吗?我们能让它多语言化吗?
Transformer:所有LLM的祖先
原始的Transformer体系结构可以看作是一个将输入文本转换为输出文本的黑盒。但神经网络本身并不理解文本;它们只说数字——所有的内部转换都是数字的。
Transformer 由两个主要模块组成:
1.编码器:以数字形式接收文本输入,并生成输入语义的嵌入表示。
2.解码器:逆过程,采取嵌入,并预测下一个文本标记。
所以在编码器和解码器之间,有一个输入的嵌入表示。input和embedding都是数值向量,但两者仍有显著区别:
1.输入向量只是来自预定义字典(对于BERT,词汇表大小为32K)的术语标识符序列,填充为固定长度。
2.嵌入向量是输入的内部表示。这就是网络如何看待你的输入。你可能会认为类似的文档会有类似的内部表示。
几年后,出现了一个充满活力的基于transformer的不同文本处理模型系列,其中有两个主要的独立分支:
1.BERT-like,只使用transformer的编码器部分。擅长分类、总结和实体识别。
2.GPT系列,只有解码器。擅长翻译、QA等生成任务。
在上面的图像中,您可以看到BERT和GPT模型子系列之间的分裂。传统上,BERT子代最常用于语义搜索领域。
BERT模型
BERT模型似乎很适合我们的语义搜索问题,因为它可以简化为针对特定查询的相关和不相关文档的二元分类任务。
但是BERT嵌入最初并不是为了语义相似性:该模型被训练来预测大型文本语料库上的被屏蔽词。相似的文本有相似的嵌入,这是一个很好的自发副作用。
但“最初不是为语义相似性而设计”只是一种观点。是否有一种方法可以客观地衡量参考数据集的好坏?
BEIR基准
学术论文“BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models”为IR方法提供了一套参考基准和数据集。这让模型质量之争变得不那么有趣了,现在有了一个排行榜来比较你的嵌入模型和竞争对手。
BEIR基准提出了一组19个不同的IR数据集和所有用于搜索质量评估的机制。
原始论文还在整个数据集上对几个基线方法进行了基准测试。2021年得出的主要结论是,BM25是一个棘手的问题,也是一个强有力的基线。
后来,BEIR被合并到一个更广泛的基准套件中:MTEB,Massive Text Embedding Benchmark。运行它很容易(如果你有128GB的内存,现代GPU和8小时的空闲时间):
from mteb import MTEB
from sentence_transformers import SentenceTransformer
# load the model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# run a subset of all benchmarks
evaluation = MTEB(tasks=["MSMARCO"])
results = evaluation.run(model, output_folder="results")
view rawmteb.py hosted with by GitHub
让我们回到“原始BERT嵌入不适用于语义搜索”的论点。如果我们在BEIR/MTEB基准测试中将bert-base-uncased与顶级句子转换器模型all-MiniLM-L6-v2和all-mpnet-base-v2 并排运行,我们将看到以下数字:
从这张表我们可以得出两个明显的结论:
1.原始的BERT嵌入是为了预测下一个单词,而不是为了语义搜索和文档相似度。现在你可以知道为什么了。
2.BM25仍然是一个强大的基线——即使是针对语义相似性进行了调整的大型MPNET模型也无法始终优于它。
但是为什么相似的嵌入模型在语义搜索任务上如此不同呢?
排行榜
目前(2023年6月)MTEB/BEIR基准的排行榜上似乎都是不知名的名字:
我们可以用以下方式总结当前最先进的语义搜索:
1.SBERT模型(all-MiniLM-L6-v2、all-MiniLM-L12-v2和all-mpnet-base-v2)在简单性和排名质量之间取得了很好的平衡。
2.SGPT (5.8B, 2.7B, 1.3B)是基于LoRa优化的开源GPT-NeoX排名模型的最新版本。
3.GTR-T5是Google的开源语义搜索嵌入模型,以T5 LLM为基础。
4.E5 (v1和v2)是Microsoft最新的嵌入模型。
我们可以通过构建语义搜索模型的两种哲学来看待这四个模型族:
1.性能。模型越小,搜索延迟越低,索引速度越快。巨大的SGPT和GTR模型只能在昂贵的GPU上运行。
2.大小。模型中参数数量越多,检索质量越好。all- minilm-l6-v2是一个非常棒的模型,但是它太小了,无法用10M参数捕获搜索中的所有语义差异。
在大小和性能之间找到平衡对于构建优秀的嵌入模型至关重要。
嵌入与稀疏检索
嵌入是众多搜索方式中的一种。旧的BM25仍然是一个强大的基线,还有一些新的“稀疏”检索方法,如SPLADEv2和ColBERT,它们结合了术语搜索和神经网络的优势。
在下表中,试图汇总以下来源的所有公开可用的 BEIR 分数:
1.MTEB结果存储库包含排行榜中使用的所有原始分数。它还包括OpenAI商业嵌入的分数,包括最新的ada-2模型。
2.ColBERT, SPLADEv2和BEIR论文的ArXiv预印本。
3.Vespa的ColBERT实施和Elastic的ELSER的博文。
如果将这张表与两年前发布的BEIR表进行比较,你可能会注意到BM25被认为是一个强有力的基线——但BM25在2023年不再是一个明显的赢家。
另一个观察结果是稀疏(例如:ELSER和SPLADEv2)和密集(E5)检索方法在质量上非常接近。因此,在这个领域没有明显的赢家,但看到如此激烈的竞争是件很棒的。
对稀疏与密集检索方法之争的个人看法:
1.密集检索更具前瞻性。从SBERT升级到E5只需要10行代码,这大大提高了检索质量。矢量搜索引擎保持不变,不需要额外的工程设计。
2.稀疏检索产生的幻觉较少,可以处理精确匹配和关键字匹配。NDCG@10并不是衡量搜索质量的唯一标准。
但辩论仍在进行中,我们将随时为您提供最新消息。
大型模型的隐性成本
有一个普遍的观点认为,模型越大,检索质量越好。从MTEB排行榜可以清楚地看出这一点,但它忽略了为这些模式提供服务是简单和廉价的重要和实用特征。
在实践中,你需要运行嵌入模型两次:
1.在索引阶段脱机。这是一个批处理作业,需要高吞吐量,但对延迟不敏感。
2.在线嵌入搜索查询,对每个搜索请求。
像SBERT和E5这样的小型模型可以在合理的延迟预算内轻松地在CPU上运行,但是如果超过500M参数(SGPT就是这种情况),则无法避免使用GPU。而且GPU现在很贵。
为了查看真实的延迟数字,我们为ONNX推理制作了一个基于JVM的小型基准测试。
从表格中可以看出:
1.在CPU和GPU上,参数数量和延迟之间存在线性依赖关系。像SGPT-1.3B这样的大型模型对于简短的4字查询的估计延迟应该是200ms,这对于面向客户的工作负载来说通常太大了。
2.存在延迟/成本/质量的权衡。你的语义搜索是快速、廉价、精确的——任选其二。
不只有英语
世界上不只是说英语。但大多数模型和评估框架只关注英语:
1.原始的BERT词汇表主要是在英语数据上训练的,在其他语言上很弱。
2.几乎所有的嵌入模型都是在英语文本语料库上训练的,所以它们都有轻微的偏向。
如果您向BERT 分词器提供非英语文本,则会发生这种情况:
from transformers import BertTokenizer, AutoTokenizer
bert = BertTokenizer.from_pretrained("bert-base-uncased")
e5 = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
en = bert.encode("There is not only English language")
print(bert.convert_ids_to_tokens(en))
# ['[CLS]', 'there', 'is', 'not', 'only', 'english', 'language', '[SEP]']
de = bert.encode("Es gibt nicht nur die englische Sprache")
print(bert.convert_ids_to_tokens(de))
# ['[CLS]', 'es', 'gi', '##bt', 'nic', '##ht', 'nur', 'die', 'eng', '##lis', '##che', 'sp', '##rac', '##he', '[SEP]']
de2 = e5.encode("Es gibt nicht nur die englische Sprache")
print(e5.convert_ids_to_tokens(de2))
# ['', '▁Es', '▁gibt', '▁nicht', '▁nur', '▁die', '▁englische', '▁Sprache', '']
view rawtoken.py hosted with by GitHub
BERT分词器不能正确地将德语单词作为单独的标记处理,必须将其拆分为子单词。相比之下,多语言XLM标记器对相同句子的处理要好得多。
幸运的是,本文中提到的大多数模型都有多语言版本:
1.E5: multilingual- E5 -base,是多语言XLM-Roberta-base的对齐版本。
2.SGPT: SGPT - BLOOM,它基于BLOOM模型。
3.SBERT:基于mUSE的多语言MiniLM-L12-v2。
这些模型是通过知识提炼过程产生的,因此它们不需要专门的多语言相似句子训练数据集。
综上所述,本章的主要结论如下:
1.要在搜索质量上超越BM25并不容易。考虑到它不需要调优,你可以在3分钟内生成一个Elasticsearch/OpenSearch集群——在2023年依赖它仍然是实用的。
2.最近在稀疏和密集检索领域都有很多进展。SGPT和E5不到1年,而SPLADE和ELSER则更年轻。
3.稀疏/密集方法之间没有单一的赢家,但是IR行业融合成一个单一的基准测试工具,使用MTEB/BEIR套件来衡量检索质量。
来源:https://medium.com/metarank/from-zero-to-semantic-search-embedding-model-592e16d94b61

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消