











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伪排练:NLP灾难性遗忘的解决方案
2017年08月29日 由 yuxiangyu 发表
622227
0
有时,你需要对预先训练的模型进行微调,以添加新标签或纠正某些特定错误。这可能会出现“灾难性遗忘”的问题。而伪排练是一个很好的解决方案:使用原始模型标签实例,并通过微调更新进行混合。
当你优化连续两次的学习问题可能会出现灾难性遗忘问题,第一个问题的权重被用来作为第二个问题权重的初始化的一部分。很多工作已经进入设计对初始化不那么敏感的优化算法。理想情况下,我们的优化做到最好,无论权重如何初始化,都会为给定的问题找到最优解。但显然我们还没有达到我们的目标。这意味着如果你连续优化两个问题,灾难性遗忘很可能发生。
这一点在Hal Daumé博客文章得到了很好的体现,最近在Jason Eisner的Twitter上重申了这一点。Yoav Goldberg也在他的书中讨论了这个问题,并提供了关于使用预先训练的矢量的更好的技术细节。
spaCy中的多任务学习
灾难性的遗忘问题最近对于spaCy用户变得更加相关,因为spaCy v2的部分语音,命名实体,句法依赖和句子分割模型都由一个卷积神经网络产生的输入表示。这允许各种型号共享了大部分的权重,使得整个模型非常小 - 最新版本只有18MB,而之前的线性模型几乎有1GB。多任务输入表示法也可以通过该doc.tensor属性用于其他任务,例如文本分类和语义相似度判定。
SPACY V2.0.0A10
为了帮助你避免灾难性遗忘问题,最新的spaCy v2.0 alpha模型将多任务CNN与本地CNN进行混合,具体到每个任务。它允许你单独更新任务,而无需写入共享组件。
然而,在所有这些模型之间共享权重存在一个微妙的陷阱。假设你正在解析短命令,那么你有很多例子,你知道第一个单词是一个必须的动词。默认的spaCy模式在这种类型的输入上表现不佳,因此我们想在一些我们要处理的文本类型用户命令的例子中更新模型。
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u'search for pictures of playful rodents')
spacy.displacy.serve(doc)
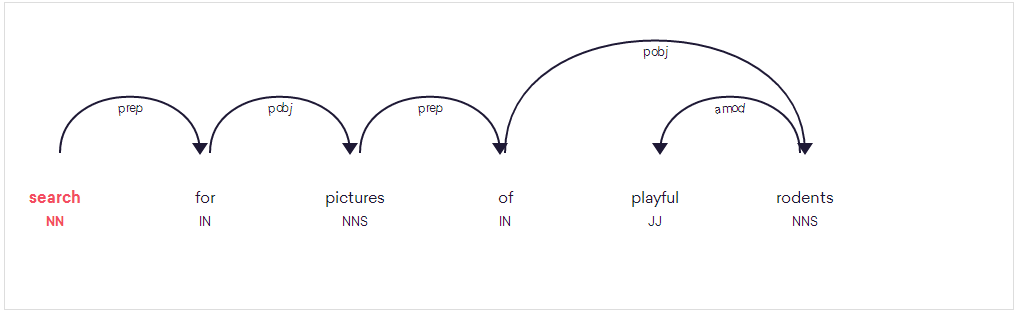
这种解析是错误的 - 它将动词“搜索”当成了名词。如果你知道句子的第一个单词应该是动词,那么你仍然可以用它来更新spaCy的模型。为了更新模型,我们将一个
Doc实例和一个GoldParse实例传递给nlp.update()方法:from spacy.gold import GoldParse
new_tags = [None] * len(doc)
new_tags[0] = 'VBP'
gold = GoldParse(doc, tags=new_tags)
nlp.update(doc, gold, update_shared=True)
这些
None值表示没有对这些标签的监督,所以预测的梯度为零。依赖性解析或实体识别器没有标签,因此这些模型的权重将不会被更新。然而,所有模型共享相同的输入表示法,因此如果这种表示法更新,所有模型都可能受到影响。为了解决这个问题,spaCy v2.0.0a10引入了一个新的标志:update_shared。此标志默认设置为False。如果我们对这个例子进行了一些更新,我们将得到一个正确标记它的模型。然而,从一个例子来看,模型没有办法猜测它应该学习什么级别的一般性。是否所有词都标记为
VBP?这句话的第一个词是什么?是否搜索了所有实例?我们需要向模型提供更多有关我们正在寻找的解决方案的信息,学习问题将不受约束,我们也不可能获得我们想要的解决方案。越过隐喻
为了使“忘记”隐喻在这里明确化,我们可以声明整体多任务模型从“知道”如何标记实体并为书面英语的各种类型生成依赖分析开始。然后我们集中了一些更具体的修正,但这导致模型失去了更多通用的能力。这个隐喻使得这个问题很令人惊讶:为什么我们的AI如此愚蠢和脆弱?这是隐喻失去效用的重点,我们需要更仔细地思考发生了什么。
当我们调用
nlp.update()时,我们要求模型产生对当前权重的分析。然后为每个子任务计算误差梯度,并通过反向传播更新权重。从本质上讲,我们增加权重直到我们得到一组产生误差梯度接近于零的分析的权重。任何一组零损失的权重都是稳定的。思考依据模型的“记忆”或“遗忘”未必有用。它只是优化你要求它优化的功能 - 有时很好,有时很差。有时我们有理由相信,优化一个目标的解决方案对另一目标的影响也是好的。但是如果我们没有对这个限制明确的编码的话,那就很难说还是这样了。
保留以前行为的一种方法是编码一个反对过多改变参数的偏见。然而,这种类型的正则化惩罚并不总能很好的接近我们的需求。在深层神经网络中,模型权重与其预测行为之间的关系是非线性的。更深入的网络可能是完全混乱的。我们实际关心的是输出而不是参数值,这就是我们如何构建目标的方法。随着模型变得越来越复杂和线性越来越少,最好避免尝试猜测这些参数是什么样的。
伪排练
以上这一切引导我们想到一个非常简单的办法来解决“灾难性遗忘”问题。当我们开始微调模型时,我们希望得到一个正确使用新的训练实例的解决方案,同时产生与原始输出相似的输出。这很容易做到:我们可以根据需要生成同样多的原始输出。然后只需要创建一些原始输出和新实例的混合。不必惊讶,这并不是新的建议。
revision_data = []
# Apply the initial model to raw examples. You'll want to experiment
# with finding a good number of revision texts. It can also help to
# filter out some data.
for doc in nlp.pipe(revision_texts):
tags = [w.tag_ for w in doc]
heads = [w.head.i for w in doc]
deps = [w.dep_ for w in doc]
entities = [(e.start_char, e.end_char, e.label_) for e in doc.ents]
revision_data.append((doc, GoldParse(doc, tags=doc_tags, heads=heads,
deps=deps, entities=entities)))
# Now shuffle the previous behaviour into the new fine-tuning data, and
# update with them together. You might want to upsample the fine-tuning
# examples (e.g. include 5 copies of it). This lets you use a better
# variety of revision data without changing the ratio of revision : tuning
# data.
n_epoch = 5
batch_size = 32
for i in range(n_epoch):
examples = revision_data + fine_tune_data
losses = {}
random.shuffle(examples)
for batch in partition_all(batch_size, examples):
docs, golds = zip(*batch)
nlp.update(docs, golds, losses=losses)
在这个过程中的一个重要是,你将混合到新素材中的“修订练习” 不能由当前优化的权重中产生。你应该保持修订材料静态的模型。否则,该模型会稳定不重要的解决方案。如果你正在传输实例,则需要在内存中保存两个模型副本。或者,您可以预先分析一批文本,然后使用注释来稳定微调。
这个方法还有待改进。此时,spaCy将教学模式提供的分析与任何其他类型的黄金标准数据相同。这看起来很不现实,因为模型使用了日志丢失。对于词性标签器,这意味着“80%置信度标签为‘NN’”的原始预测被转换为“100%置信度标签为‘NN’”。最好是对由教学模式返回的分布进行监督,或者也可以使用日志丢失。
总结
在计算机视觉和自然语言处理中预训练模型是常见的。图像,视频,文本和音频输入具有丰富的内部结构,可从大型培训样本和广泛的任务中学习。这些预先训练的模型在对特定的感兴趣问题进行“微调”时尤为有用。然而,微调过程可能会引入“灾难性遗忘”的问题:发现优化特定微调数据的解决方案,一般化也随之丢失。
有些人提出使用正规化处罚来解决这个问题。然而,这对与前面的参数空间模型相近的解决方案的首选项进行了编码,而我们真正想要的是接近于在输出空间中的前一个模型的解决方案。伪排练是实现这一点的好方法:使用初始模型预测一些实例,并通过微调数据进行混合。这代表了一个模型的目标,它的行为与预训练的模型类似,除了微调数据。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消