











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






AI电话对抗多模态模型:创新和智能的决斗
2023年06月25日 由 Alex 发表
516639
0
生成式人工智能(Generative AI)正处于火热状态。尤其是在过去的几个月中,多模态机器学习(multimodal machine learning)领域迎来了爆炸性的增长——这种人工智能技术将不同的“模态”(例如文本、图像和音频)之间的概念连接起来。举例来说,Midjourney 是一个多模态的文本到图像模型,因为它接受自然语言输入并生成图像输出。这一领域近期引发广泛关注的里程碑是 Meta AI 的ImageBind,它能够以相同的“空间”表示6种不同类型的输入。
在所有这些令人兴奋的发展中,我想要对多模态模型进行测试,看看它们实际上有多好。特别是,我想要回答以下三个问题:
1.哪种文本到图像的模式是最好的?
2.哪个图像到文本的模型是最好的?
3.哪个更重要——图像到文本,还是文本到图像?
当然,从训练数据到模型架构,每个模型都有自己的偏差,所以并不存在真正的最佳模型。但是我们仍然可以在一般环境中对模型进行测试!
为了回答这些问题,我决定玩一个受到桌游Telestrations启发的AI Telephone游戏。
Telestrations(远程通讯)很像电话游戏:玩家们依次传递信息,将来自一侧的信息传递给另一侧的人,并按顺序将他们对信息的理解传达给下一个人。随着游戏的进行,原始的信息不可避免地会发生变化,甚至可能完全丢失。然而,Telestrations有所不同之处在于它添加了双模态的交流方式:玩家们在绘画(或插图)描述和以文本形式描述之间交替进行。
AI电话游戏玩法如下:
1.每个“游戏”将配对一个图像到文本(I2T)模型和一个文本到图像(T2I)模型
2.给定初始提示,我们使用T2I模型生成图像。
3.然后,我们将该图像传递到I2T模型中以生成描述。
4.我们重复步骤2和步骤3的固定次数n(在我们的例子中n=10)。
5.最后,我们量化了原始提示和最终描述之间的差异。
在本文中,我将向你详细介绍整个过程,以便你也可以玩AI电话游戏!最后,我将回答那三个激发好奇心的问题。
注:AI电话游戏与循环一致性的概念紧密相关。在训练过程中,在损失函数中加入循环一致性项,可以激励模型在电话游戏中有效地减少信息的退化。据我所知,在本实验中考虑的模型中,没有一个模型是以循环一致性为考虑因素进行训练的。
本文结构如下:
1.选择多模态模型
2.生成提示
3.创建电话线
4.进行对话
5.可视化和分析结果
要运行此代码,你需要安装FiftyOne开源库以进行数据集策划、OpenAI Python库以及Replicate Python客户端。
选择竞争对手
多模态模型的领域非常广阔:截至撰写本文时,仅Hugging Face就有4425个T2I模型和155个I2T模型。玩AI Telephone与所有这些模型(甚至其中的一小部分)都是不可行的。我首要任务是将这个潜在候选模型的范围缩小到一个更可控的竞争对手组合。
选择API
在开始这个项目时,我知道自己将使用许多模型。其中一些潜在的模型非常庞大,并且许多模型需要自己的环境,具有独特的要求。考虑到我计划将每个T2I模型与每个I2T模型配对,将这些模型本地安装以玩AI Telephone游戏可能会导致潜在的依赖问题。
为了避免这个问题,我决定只使用可以通过API访问的模型。特别是,我选择主要使用Replicate,其简单的接口使我可以以即插即用的方式使用T2I和I2T模型。我使用的几乎所有模型都是开源的。
文本到图像模型
在选择T2I模型时,我从Replicate的文本到图像集合中选择了模型。我的选择标准是模型需要便宜、快速和相对流行(根据Replicate上模型的“运行”次数判断)。此外,模型需要是通用目的的,意味着我不会考虑外插、生成徽标或动漫风格的模型。
根据这些要求,我选择了Stable Diffusion和Feed forward VQGAN CLIP。最初,我也使用了DALL-E Mini,但在早期测试中,我对模型的性能感到失望,所以我将该模型替换为OpenAI的DALL-E2,我通过OpenAI的图像生成终端访问该模型。
附带说明一下,将注意力集中在可以通过API访问的模型上意味着我没有考虑Midjourney。其没有官方API,我也不想使用非官方API,也不想逐个在Discord上输入提示并逐个下载生成的图像。
为了使这个过程尽可能的即插即用,我采取了面向对象的方法。我定义了一个基础的Text2Image类,该类公开了一个generate_image(text)的方法:
对于Replicate的模型,只需要设置model_name属性,即可识别Replicate上的模型。例如,对于Stable Diffusion模型,类的定义如下:
对于其他模型,例如DALL-E2,可以重载generate_image(text)方法:
这些T2I模型中的每一个都会返回生成的图像的URL,然后可以直接将其传递给我们的I2T模型。
图像到文本模型
我使用了类似的过程来确定I2T竞争对手,评估Replicate的图像到文本集合中的候选模型。在查看集合中所有模型的示例后,我挑选出了六个模型:BLIP、BLIP-2、CLIP前缀字幕、使用CLIP奖励进行细粒度图像字幕、mPLUG-Owl和MiniGPT-4。其他模型也很有吸引力,如CLIP Interrogator,它试图逆向工程一个可以用来生成相似图像的提示。但在AI电话游戏中,这感觉有点像作弊!
在6个I2T候选模型中,我能够很快地从争论中排除两个模型:BLIP-2生成的响应总是太短而无用,而CLIP Caption Reward模型生成的响应通常是不连贯的。
与T2I模型直接类比,我定义了一个基础Image2Text类,公开了一个generate_text(image_url)方法:
然后我为每个模型创建子类。BLIP子类如下所示:
所有模型实例化的task_description属性都相同,即“写一篇有关这张图片的详细描述”。
生成提示
为了尽量“科学”地进行,我认为最好不要自己生成初始提示。取而代之的是(仅限娱乐),我将任务外包给ChatGPT。我问道:
我正在使用文本到图像和图像到文本的AI模型玩一款AI电话游戏。我希望根据这些模型在长时间对话过程中保留复杂语义信息的能力来评估它们。你的任务是为我提供10个文本提示,我可以用这些提示来进行这些AI电话游戏。你必须给我一个 3 个简单、3 个中等、3 个困难和 1 个超难(不可能)的提示。
以下是ChatGPT生成的一些提示:
更科学的方法会更加有意识地选择使用的提示及其分类。
然后,我将ChatGPT生成的文本提示构造为Prompt对象,其中包含提示文本和ChatGPT分配的“难度”级别:
电话线路
玩AI Telephone所需的最后一个组件是“电话线路”本身。我创建了一个TelephoneLine类,用于封装T2I模型和I2T模型之间的连接。通过一个电话线路进行“电话游戏”,调用play(prompt, nturns=10),其中对话从初始提示开始,并在nturns来回进行。
对于每个玩的游戏,对话会以唯一的名称记录下来,该名称是由哈希T2I模型名称、I2T模型名称和提示文本(get_conversation_name()方法)生成的。
我还为类添加了一个save_conversations_to_dataset()方法,该方法将来自电话线路上所有游戏的生成图像和所有相关对话内容保存到FiftyOne数据集中:
进行对话
拥有所有的基本组件,玩AI电话游戏非常简单!
我们可以实例化T2I和I2T模型:
然后为每一对创建一条电话线:
然后加载我们的提示:
然后创建一个FiftyOne数据集,我们将使用该数据集存储生成的图像和对话中的所有相关信息:
然后我们可以运行所有120个电话游戏:
在FiftyOne App中,点击菜单栏中的划分符号,按对话分组图像,从下拉菜单中选择conversation_name,然后切换选择器为ordered并选择step_number。
结果与结论
为了评估对话的质量——纯粹根据最终描述的含义与初始提示的含义的接近程度,我决定为提示和描述生成嵌入,并计算两者之间的余弦距离(在[0,2]中)。
对于嵌入模型,我希望找到一个能够嵌入文本和图像的模型,考虑到综合模态性质的特点。最终,我选择使用ImageBind,原因如下:
1. 其他流行的联合图像文本嵌入模型,如CLIP和BLIP与我在实验中使用的模型(BLIP和CLIP前缀字幕)有关,我希望避免使用相同类型的模型进行评估可能带来的任何可能的偏见。
2.许多文本嵌入模型都有一个很小的max_token_count——文本中允许嵌入的标记的最大数量。例如,CLIP的max_token_count=77。我们的一些描述比这长得多。幸运的是,ImageBind的最大令牌计数要长得多。
3.我一直想尝试ImageBind,这是一个很好的机会!
我在embed_text(text)函数中将Replicate的ImageBind API进行封装:
为了避免冗余计算,我对提示进行了哈希处理,并在字典中存储了提示的嵌入。这样,我们只需要对每个T2I-I2T对话线路嵌入提示一次:
然后,按对话名称对样本进行分组,迭代这些组,计算每个步骤的文本嵌入,并记录文本嵌入与初始提示嵌入之间的余弦距离(越小越好):
然后,我计算了在难度一定的情况下,每个T2I-I2T对在所有提示中的平均得分,并绘制了结果。图像上打印了I2T和T2I模型,以及用于生成该图像的文本(红色)和从该图像生成的描述(绿色)。
简单
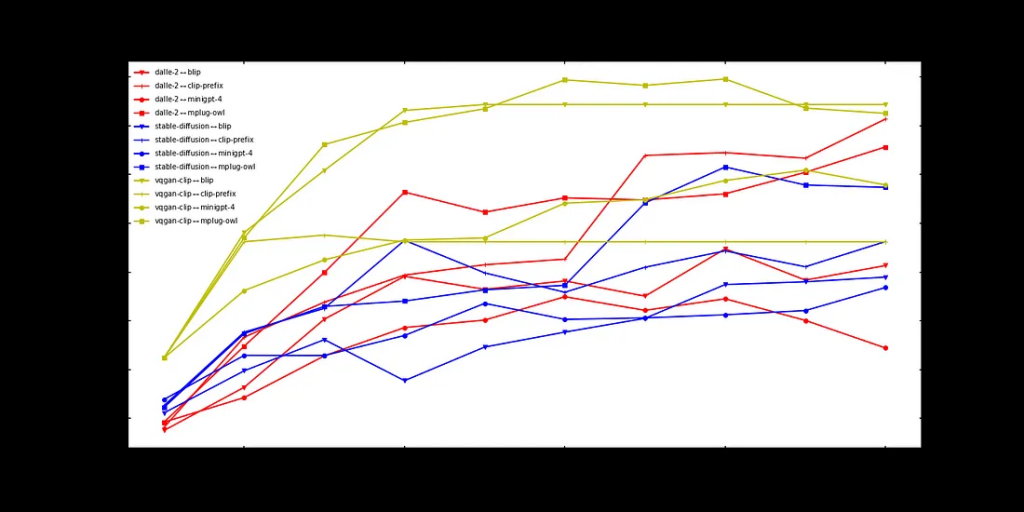
对于简单的提示,性能往往最大程度上取决于文本到图像模型。DALL-E2和Stable Diffusion明显优于VQGAN-CLIP。MiniGPT-4是表现最好的几个对中的成员。
以下是上面介绍的简单提示的一些例子:
在使用MiniGPT-4(稍微逊色的是BLIP)的游戏中,苹果始终保持在正中央,而对于涉及CLIP前缀的游戏,苹果随着时间的推移逐渐消失。
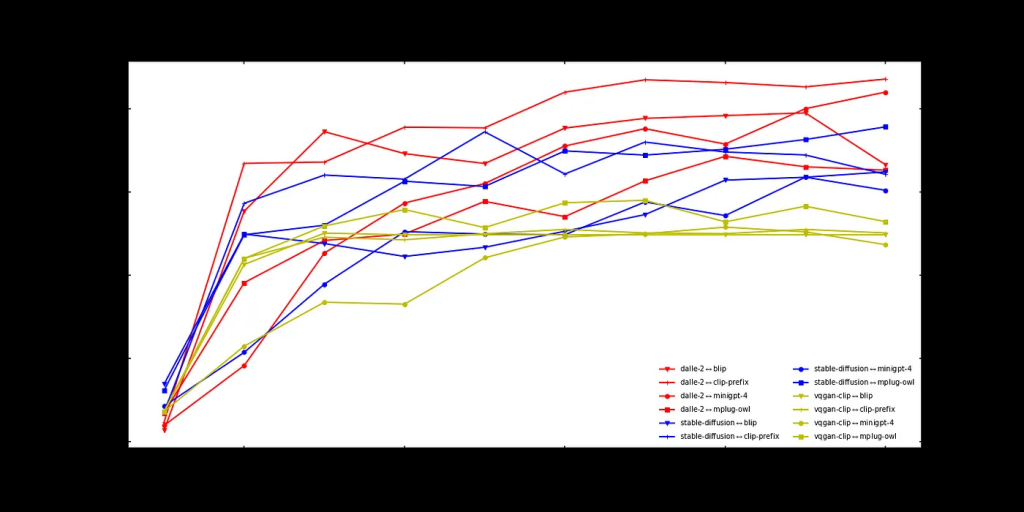
中等
当提示变得有点困难时,情况就开始改变了。
在几乎所有的游戏中,主题在第四或第五步左右发生变化。早期,MiniGPT-4处于优势地位。但到了游戏结束时,这种优势似乎已经完全丧失。
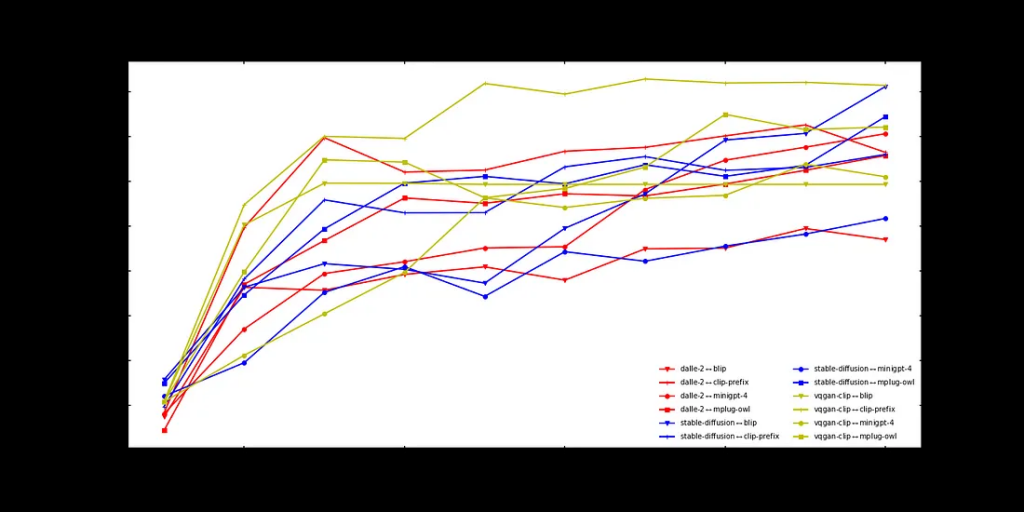
困难
到了提示变得具有挑战性的时候,我们开始看到一些有趣的现象:在早期阶段,图像到文本模型最重要(MiniGPT-4最好,而CLIP前缀在大部分情况下最差)。然而,在后期阶段,文本到图像模型变得最重要。此外,VQGAN-CLIP在这里表现最好!
有人可能担心“更好”可能只意味着保持一致,而不准确地表示原始概念。然而,当我们看一些例子时,我们可以发现情况并非如此。

以图片中突出显示的例子为例,初始提示是关于“繁忙的市场”的“困难”提示。虽然VQGAN-CLIP生成的图像无疑有些颗粒状,但主题仍然可以辨认出来,并且与原始提示相当接近。
不可能的
不出所料,我们的竞争对手在这里表现都不太好。也许可以说VQGAN-CLIP是赢家。但在大多数情况下,这只是一片噪音。
总结
这种探索还远非科学:我只观察了十个提示,没有真正验证它们的难度级别。我只进行了十次来回对话的交流;并且我只评估了一个指标的性能。
很明显,哪些T2I和I2T模型表现最佳在很大程度上取决于提示的复杂性以及你希望让模型进行多长时间的对话。然而,值得注意的几个关键观察结果如下:
1.VQGAN-CLIP在更具挑战性的提示上可能表现更好,但这并不意味着它是更好的T2I模型。与Stable Diffusion或DALL-E2生成的图像相比,VQGAN-CLIP生成的图像通常更缺乏连贯性和全局一致性。
2.上述分析都是关于语义相似性的,没有考虑到样式。这些图像的样式在AI电话游戏中会发生很大变化。据我个人观察,像mPLUG-Owl这样给出长描述的I2T模型的样式更加一致,而像BLIP这样描述更受主题影响的模型的样式更不一致。
3.经过大约5到6次迭代,这些博弈基本上都趋同于稳定的平衡。
4.尽管嵌入模型ImageBind是多模态的,但连续图像嵌入和文本嵌入之间的距离远大于连续图像或连续描述之间的距离。总的来说,它们遵循相同的趋势,但程度较轻,这就是我没有在图表中包含它们的原因。
来源:https://towardsdatascience.com/ai-telephone-a-battle-of-multimodal-models-282b01daf044
在所有这些令人兴奋的发展中,我想要对多模态模型进行测试,看看它们实际上有多好。特别是,我想要回答以下三个问题:
1.哪种文本到图像的模式是最好的?
2.哪个图像到文本的模型是最好的?
3.哪个更重要——图像到文本,还是文本到图像?
当然,从训练数据到模型架构,每个模型都有自己的偏差,所以并不存在真正的最佳模型。但是我们仍然可以在一般环境中对模型进行测试!
为了回答这些问题,我决定玩一个受到桌游Telestrations启发的AI Telephone游戏。
Telestrations(远程通讯)很像电话游戏:玩家们依次传递信息,将来自一侧的信息传递给另一侧的人,并按顺序将他们对信息的理解传达给下一个人。随着游戏的进行,原始的信息不可避免地会发生变化,甚至可能完全丢失。然而,Telestrations有所不同之处在于它添加了双模态的交流方式:玩家们在绘画(或插图)描述和以文本形式描述之间交替进行。
AI电话游戏玩法如下:
1.每个“游戏”将配对一个图像到文本(I2T)模型和一个文本到图像(T2I)模型
2.给定初始提示,我们使用T2I模型生成图像。
3.然后,我们将该图像传递到I2T模型中以生成描述。
4.我们重复步骤2和步骤3的固定次数n(在我们的例子中n=10)。
5.最后,我们量化了原始提示和最终描述之间的差异。
在本文中,我将向你详细介绍整个过程,以便你也可以玩AI电话游戏!最后,我将回答那三个激发好奇心的问题。
注:AI电话游戏与循环一致性的概念紧密相关。在训练过程中,在损失函数中加入循环一致性项,可以激励模型在电话游戏中有效地减少信息的退化。据我所知,在本实验中考虑的模型中,没有一个模型是以循环一致性为考虑因素进行训练的。
本文结构如下:
1.选择多模态模型
2.生成提示
3.创建电话线
4.进行对话
5.可视化和分析结果
要运行此代码,你需要安装FiftyOne开源库以进行数据集策划、OpenAI Python库以及Replicate Python客户端。
pip install fiftyone openai replicate
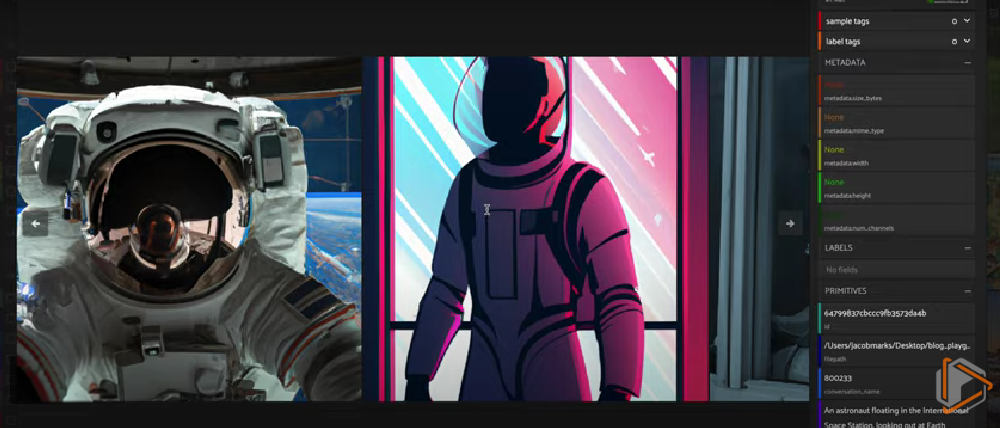
DALL-E2 和 BLIP 之间的 AI 电话游戏中的图像进展
选择竞争对手
多模态模型的领域非常广阔:截至撰写本文时,仅Hugging Face就有4425个T2I模型和155个I2T模型。玩AI Telephone与所有这些模型(甚至其中的一小部分)都是不可行的。我首要任务是将这个潜在候选模型的范围缩小到一个更可控的竞争对手组合。
选择API
在开始这个项目时,我知道自己将使用许多模型。其中一些潜在的模型非常庞大,并且许多模型需要自己的环境,具有独特的要求。考虑到我计划将每个T2I模型与每个I2T模型配对,将这些模型本地安装以玩AI Telephone游戏可能会导致潜在的依赖问题。
为了避免这个问题,我决定只使用可以通过API访问的模型。特别是,我选择主要使用Replicate,其简单的接口使我可以以即插即用的方式使用T2I和I2T模型。我使用的几乎所有模型都是开源的。
文本到图像模型
在选择T2I模型时,我从Replicate的文本到图像集合中选择了模型。我的选择标准是模型需要便宜、快速和相对流行(根据Replicate上模型的“运行”次数判断)。此外,模型需要是通用目的的,意味着我不会考虑外插、生成徽标或动漫风格的模型。
根据这些要求,我选择了Stable Diffusion和Feed forward VQGAN CLIP。最初,我也使用了DALL-E Mini,但在早期测试中,我对模型的性能感到失望,所以我将该模型替换为OpenAI的DALL-E2,我通过OpenAI的图像生成终端访问该模型。
附带说明一下,将注意力集中在可以通过API访问的模型上意味着我没有考虑Midjourney。其没有官方API,我也不想使用非官方API,也不想逐个在Discord上输入提示并逐个下载生成的图像。
为了使这个过程尽可能的即插即用,我采取了面向对象的方法。我定义了一个基础的Text2Image类,该类公开了一个generate_image(text)的方法:
import replicate
class Text2Image(object):
"""Wrapper for a Text2Image model."""
def __init__(self):
self.name = None
self.model_name = None
def generate_image(self, text):
response = replicate.run(self.model_name, input={"prompt": text})
if type(response) == list:
response = response[0]
return response
对于Replicate的模型,只需要设置model_name属性,即可识别Replicate上的模型。例如,对于Stable Diffusion模型,类的定义如下:
class StableDiffusion(Text2Image):
"""Wrapper for a StableDiffusion model."""
def __init__(self):
self.name = "stable-diffusion"
self.model_name = "stability-ai/stable-diffusion:27b93a2413e7f36cd83da926f3656280b2931564ff050bf9575f1fdf9bcd7478"
对于其他模型,例如DALL-E2,可以重载generate_image(text)方法:
import openai
class DALLE2(Text2Image):
"""Wrapper for a DALL-E 2 model."""
def __init__(self):
self.name = "dalle-2"
def generate_image(self, text):
response = openai.Image.create(
prompt=text,
n=1,
size="512x512"
)
return response['data'][0]['url']
这些T2I模型中的每一个都会返回生成的图像的URL,然后可以直接将其传递给我们的I2T模型。
图像到文本模型
我使用了类似的过程来确定I2T竞争对手,评估Replicate的图像到文本集合中的候选模型。在查看集合中所有模型的示例后,我挑选出了六个模型:BLIP、BLIP-2、CLIP前缀字幕、使用CLIP奖励进行细粒度图像字幕、mPLUG-Owl和MiniGPT-4。其他模型也很有吸引力,如CLIP Interrogator,它试图逆向工程一个可以用来生成相似图像的提示。但在AI电话游戏中,这感觉有点像作弊!
在6个I2T候选模型中,我能够很快地从争论中排除两个模型:BLIP-2生成的响应总是太短而无用,而CLIP Caption Reward模型生成的响应通常是不连贯的。
与T2I模型直接类比,我定义了一个基础Image2Text类,公开了一个generate_text(image_url)方法:
class Image2Text(object):
"""Wrapper for an Image2Text model."""
def __init__(self):
self.name = None
self.model_name = None
self.task_description = "Write a detailed description of this image."
def generate_text(self, image_url):
response = replicate.run(
self.model_name,
input={
"image": image_url,
"prompt": self.task_description,
}
)
return response
然后我为每个模型创建子类。BLIP子类如下所示:
class BLIP(Image2Text):
"""Wrapper for a BLIP model."""
def __init__(self):
super().__init__()
self.name = "blip"
self.model_name = "salesforce/blip:2e1dddc8621f72155f24cf2e0adbde548458d3cab9f00c0139eea840d0ac4746"
所有模型实例化的task_description属性都相同,即“写一篇有关这张图片的详细描述”。
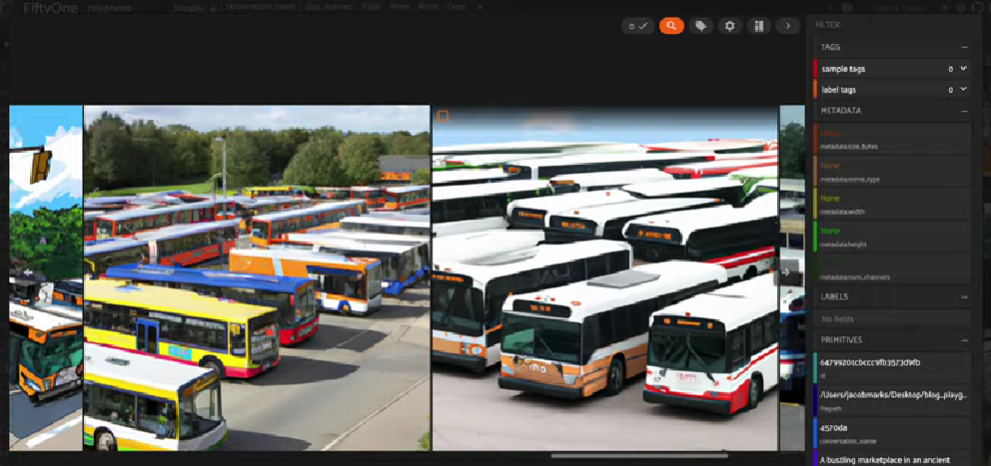
DALL-E2与mPLUG-Owl在AI电话游戏中的图像进展。
生成提示
为了尽量“科学”地进行,我认为最好不要自己生成初始提示。取而代之的是(仅限娱乐),我将任务外包给ChatGPT。我问道:
I'm playing a game of telephone using text-to-image and image-to-text AI models.
I want to evaluate these models based on their ability to retain complex semantic
information over the course of long conversations. Your job is to give me 10 text
prompts that I can use to run these games of telephone. You must give me one 3
easy, 3 medium, 3 hard, and 1 ultra-hard prompt
我正在使用文本到图像和图像到文本的AI模型玩一款AI电话游戏。我希望根据这些模型在长时间对话过程中保留复杂语义信息的能力来评估它们。你的任务是为我提供10个文本提示,我可以用这些提示来进行这些AI电话游戏。你必须给我一个 3 个简单、3 个中等、3 个困难和 1 个超难(不可能)的提示。
以下是ChatGPT生成的一些提示:
Easy:
"A red apple sitting on a wooden table with sunlight streaming in from a window."
Medium:
"An astronaut floating in the International Space Station, looking out at Earth through the window, with a space capsule docked in the background."
Hard:
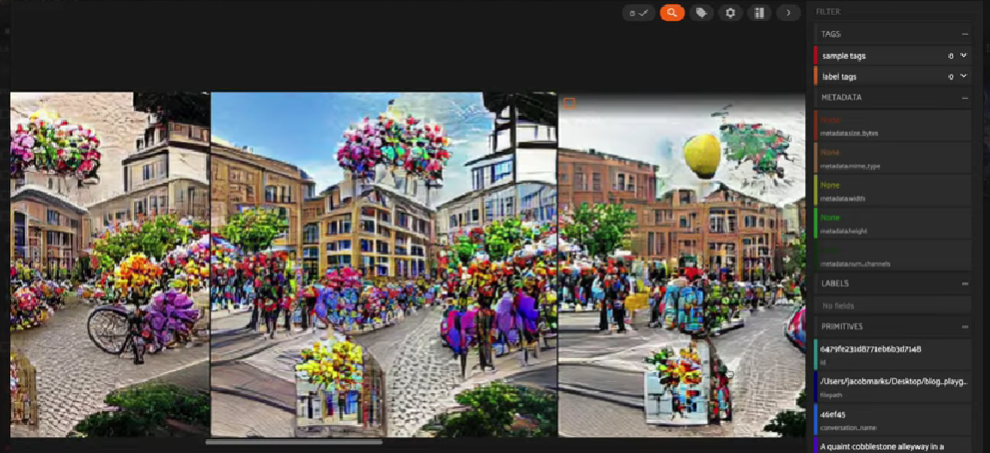
"A bustling marketplace in an ancient Middle Eastern city. Traders haggling over spices and silks, camels carrying goods, the sun setting behind a mosque with a crescent moon visible."
Impossible:
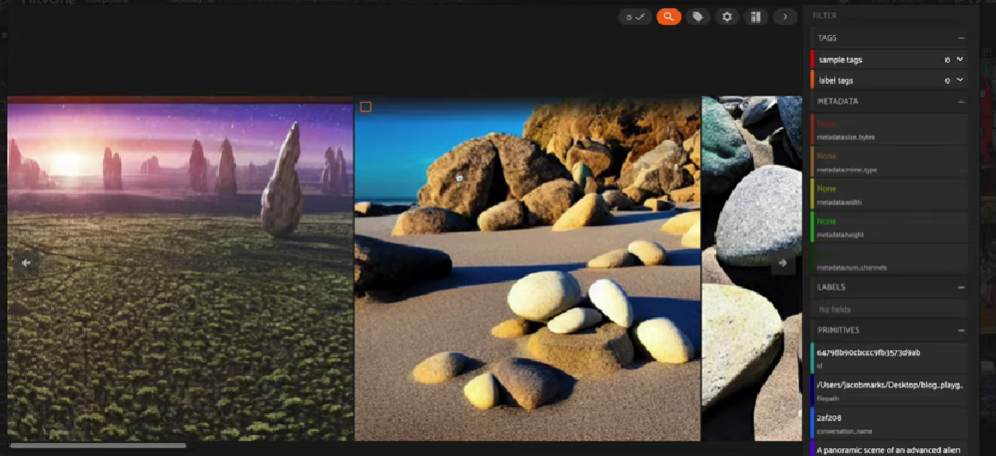
"A panoramic scene of an advanced alien civilization on a distant exoplanet. Interstellar vehicles flying in an indigo sky above towering crystalline structures. Aliens with varying physical features are interacting, engaging in activities like exchanging energy orbs, communicating through light patterns, and tending to exotic, bio-luminescent flora. The planet’s twin moons are visible in the horizon over a glistening alien ocean."
更科学的方法会更加有意识地选择使用的提示及其分类。
然后,我将ChatGPT生成的文本提示构造为Prompt对象,其中包含提示文本和ChatGPT分配的“难度”级别:
class Prompt(object):
def __init__(self, text, level):
self.text = text
self.level = level
levels = ["easy", "medium", "hard", "impossible"]
level_prompts = [easy_texts, medium_texts, hard_texts, impossible_texts]
def get_prompts():
prompts = []
for level, texts in zip(levels, level_prompts):
for text in texts:
prompts.append(Prompt(text, level))
return prompts
VQGAN-CLIP与MiniGPT-4在AI电话游戏中的图像进展
电话线路
玩AI Telephone所需的最后一个组件是“电话线路”本身。我创建了一个TelephoneLine类,用于封装T2I模型和I2T模型之间的连接。通过一个电话线路进行“电话游戏”,调用play(prompt, nturns=10),其中对话从初始提示开始,并在nturns来回进行。
import os
import hashlib
import fiftyone as fo
from fiftyone import ViewField as F
class TelephoneLine(object):
"""Class for playing telephone with AI."""
def __init__(self, t2i, i2t):
self.t2i = t2i
self.i2t = i2t
self.name = f"{t2i.name}_{i2t.name}"
self.conversations = {}
def get_conversation_name(self, text):
full_name = f"{self.name}{text}"
hashed_name = hashlib.md5(full_name.encode())
return hashed_name.hexdigest()[:6]
def play(self, prompt, nturns = 10):
"""Play a game of telephone."""
print(f"Connecting {self.t2i.name} <-> {self.i2t.name} with prompt: {prompt.text[:20]}...")
texts = [prompt.text]
image_urls = []
for _ in range(nturns):
image_url = self.t2i.generate_image(texts[-1])
text = self.i2t.generate_text(image_url)
texts.append(text)
image_urls.append(image_url)
conversation_name = self.get_conversation_name(prompt.text)
self.conversations[conversation_name] = {
"texts": texts,
"image_urls": image_urls,
"level": prompt.level
}
对于每个玩的游戏,对话会以唯一的名称记录下来,该名称是由哈希T2I模型名称、I2T模型名称和提示文本(get_conversation_name()方法)生成的。
我还为类添加了一个save_conversations_to_dataset()方法,该方法将来自电话线路上所有游戏的生成图像和所有相关对话内容保存到FiftyOne数据集中:
def save_conversations_to_dataset(self, dataset):
"""Save conversations to a dataset."""
for conversation_name in self.conversations.keys():
conversation = self.conversations[conversation_name]
prompt = conversation["texts"][0]
level = conversation["level"]
image_urls = conversation["image_urls"]
texts = conversation["texts"]
for i in range(len(image_urls)):
filename = f"{conversation_name}_{i}.jpg"
filepath = os.path.join(IMAGES_DIR, filename)
download_image(image_urls[i], filepath)
sample = fo.Sample(
filepath = filepath,
conversation_name = conversation_name,
prompt = prompt,
level = level,
t2i_model = self.t2i.name,
i2t_model = self.i2t.name,
step_number = i,
text_before = texts[i],
text_after = texts[i+1]
)
dataset.add_sample(sample)
AI电话游戏中稳定扩散与CLIP前缀字幕之间的图像进展
进行对话
拥有所有的基本组件,玩AI电话游戏非常简单!
我们可以实例化T2I和I2T模型:
## Image2Text models
mplug_owl = MPLUGOwl()
blip = BLIP()
clip_prefix = CLIPPrefix()
mini_gpt4 = MiniGPT4()
image2text_models = [mplug_owl, blip, clip_prefix, mini_gpt4]
## Text2Image models
vqgan_clip = VQGANCLIP()
sd = StableDiffusion()
dalle2 = DALLE2()
text2image_models = [sd, dalle2, vqgan_clip]
然后为每一对创建一条电话线:
combos = [(t2i, i2t) for t2i in text2image_models for i2t in image2text_models]
lines = [TelephoneLine(*combo) for combo in combos]
然后加载我们的提示:
prompts = get_prompts()
然后创建一个FiftyOne数据集,我们将使用该数据集存储生成的图像和对话中的所有相关信息:
import fiftyone as fo
dataset = fo.Dataset(name = 'telephone', persistent=True)
dataset.add_sample_field("conversation_name", fo.StringField)
dataset.add_sample_field("prompt", fo.StringField)
dataset.add_sample_field("level", fo.StringField)
dataset.add_sample_field("t2i_model", fo.StringField)
dataset.add_sample_field("i2t_model", fo.StringField)
dataset.add_sample_field("step_number", fo.IntField)
dataset.add_sample_field("text_before", fo.StringField)
dataset.add_sample_field("text_after", fo.StringField)
然后我们可以运行所有120个电话游戏:
from tqdm import tqdm
for line in tqdm(lines):
for prompt in prompts:
line.play(prompt, nturns = 10)
line.save_conversations_to_dataset(dataset)
session = fo.launch_app(dataset)
在FiftyOne App中,点击菜单栏中的划分符号,按对话分组图像,从下拉菜单中选择conversation_name,然后切换选择器为ordered并选择step_number。
结果与结论
为了评估对话的质量——纯粹根据最终描述的含义与初始提示的含义的接近程度,我决定为提示和描述生成嵌入,并计算两者之间的余弦距离(在[0,2]中)。
from scipy.spatial.distance import cosine as cosine_distance
对于嵌入模型,我希望找到一个能够嵌入文本和图像的模型,考虑到综合模态性质的特点。最终,我选择使用ImageBind,原因如下:
1. 其他流行的联合图像文本嵌入模型,如CLIP和BLIP与我在实验中使用的模型(BLIP和CLIP前缀字幕)有关,我希望避免使用相同类型的模型进行评估可能带来的任何可能的偏见。
2.许多文本嵌入模型都有一个很小的max_token_count——文本中允许嵌入的标记的最大数量。例如,CLIP的max_token_count=77。我们的一些描述比这长得多。幸运的是,ImageBind的最大令牌计数要长得多。
3.我一直想尝试ImageBind,这是一个很好的机会!
我在embed_text(text)函数中将Replicate的ImageBind API进行封装:
MODEL_NAME = "daanelson/imagebind:0383f62e173dc821ec52663ed22a076d9c970549c209666ac3db181618b7a304"
def embed_text(text):
response = replicate.run(
MODEL_NAME,
input={
"text_input": text,
"modality": "text"
}
)
return np.array(response)
为了避免冗余计算,我对提示进行了哈希处理,并在字典中存储了提示的嵌入。这样,我们只需要对每个T2I-I2T对话线路嵌入提示一次:
import hashlib
def hash_prompt(prompt):
return hashlib.md5(prompt.encode()).hexdigest()[:6]
### Embed initial prompts
prompt_embeddings = {}
dataset.add_sample_field("prompt_hash", fo.StringField)
## Group samples by initial prompt
## Add hash to all samples in group
prompt_groups = dataset.group_by("prompt")
for pg in prompt_groups.iter_dynamic_groups():
prompt = pg.first().prompt
hash = hash_prompt(prompt)
prompt_embeddings[hash] = embed_text(prompt)
view = pg.set_field("prompt_hash", hash)
view.save("prompt_hash")
然后,按对话名称对样本进行分组,迭代这些组,计算每个步骤的文本嵌入,并记录文本嵌入与初始提示嵌入之间的余弦距离(越小越好):
dataset.add_sample_field("text_after_dist", fo.FloatField)
prompt_groups = dataset.group_by("conversation_name")
for cg in conversation_groups.iter_dynamic_groups(progress=True):
hash = cg.first().prompt_hash
prompt_embedding = prompt_embeddings[hash]
ordered_samples = cg.sort_by("step_number")
for sample in ordered_samples.iter_samples(autosave=True):
text_embedding = embed_text(sample.text_after)
sample["text_embedding"] = text_embedding
sample.text_after_dist = cosine_distance(
prompt_embedding,
text_embedding
)然后,我计算了在难度一定的情况下,每个T2I-I2T对在所有提示中的平均得分,并绘制了结果。图像上打印了I2T和T2I模型,以及用于生成该图像的文本(红色)和从该图像生成的描述(绿色)。
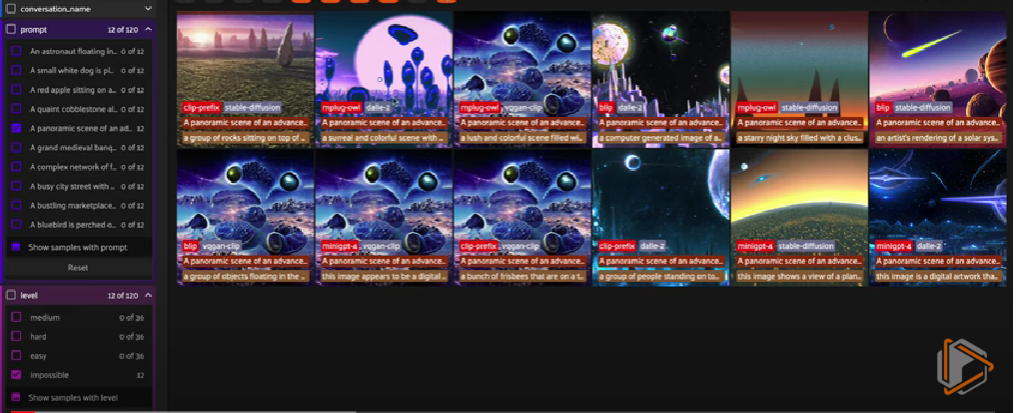
简单
对于简单的提示,性能往往最大程度上取决于文本到图像模型。DALL-E2和Stable Diffusion明显优于VQGAN-CLIP。MiniGPT-4是表现最好的几个对中的成员。
以下是上面介绍的简单提示的一些例子:
AI 电话可提供简单的提示,具有成对的文本到图像和图像到文本模型
在使用MiniGPT-4(稍微逊色的是BLIP)的游戏中,苹果始终保持在正中央,而对于涉及CLIP前缀的游戏,苹果随着时间的推移逐渐消失。
中等
当提示变得有点困难时,情况就开始改变了。
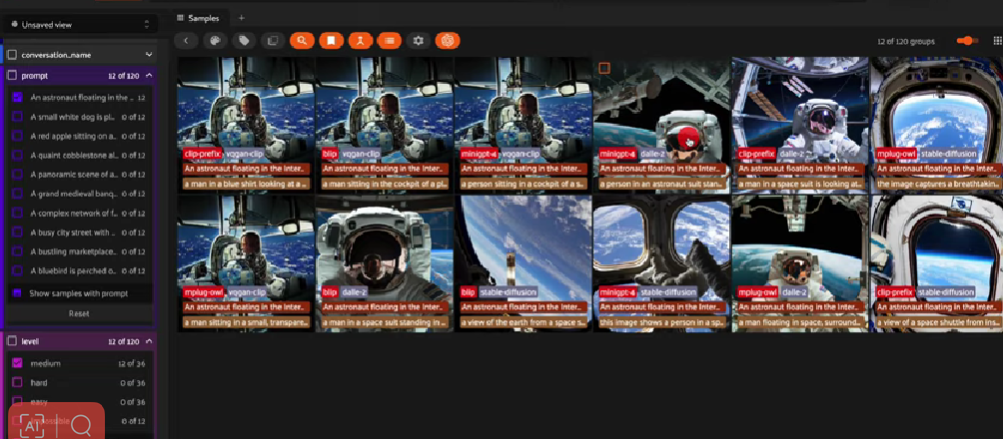
AI电话为中等难度提示,具有文本到图像和图像到文本模型对
在几乎所有的游戏中,主题在第四或第五步左右发生变化。早期,MiniGPT-4处于优势地位。但到了游戏结束时,这种优势似乎已经完全丧失。
困难
到了提示变得具有挑战性的时候,我们开始看到一些有趣的现象:在早期阶段,图像到文本模型最重要(MiniGPT-4最好,而CLIP前缀在大部分情况下最差)。然而,在后期阶段,文本到图像模型变得最重要。此外,VQGAN-CLIP在这里表现最好!
有人可能担心“更好”可能只意味着保持一致,而不准确地表示原始概念。然而,当我们看一些例子时,我们可以发现情况并非如此。
AI 电话用于硬提示,具有成对的文本到图像和图像到文本模型
以图片中突出显示的例子为例,初始提示是关于“繁忙的市场”的“困难”提示。虽然VQGAN-CLIP生成的图像无疑有些颗粒状,但主题仍然可以辨认出来,并且与原始提示相当接近。
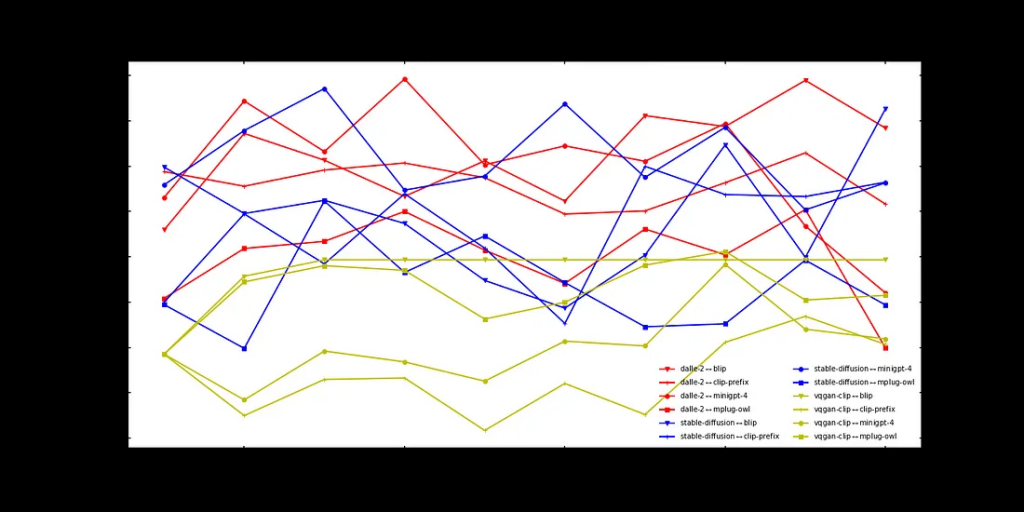
不可能的
不出所料,我们的竞争对手在这里表现都不太好。也许可以说VQGAN-CLIP是赢家。但在大多数情况下,这只是一片噪音。
AI 电话用于“不可能”提示,具有文本到图像和图像到文本模型对
总结
这种探索还远非科学:我只观察了十个提示,没有真正验证它们的难度级别。我只进行了十次来回对话的交流;并且我只评估了一个指标的性能。
很明显,哪些T2I和I2T模型表现最佳在很大程度上取决于提示的复杂性以及你希望让模型进行多长时间的对话。然而,值得注意的几个关键观察结果如下:
1.VQGAN-CLIP在更具挑战性的提示上可能表现更好,但这并不意味着它是更好的T2I模型。与Stable Diffusion或DALL-E2生成的图像相比,VQGAN-CLIP生成的图像通常更缺乏连贯性和全局一致性。
2.上述分析都是关于语义相似性的,没有考虑到样式。这些图像的样式在AI电话游戏中会发生很大变化。据我个人观察,像mPLUG-Owl这样给出长描述的I2T模型的样式更加一致,而像BLIP这样描述更受主题影响的模型的样式更不一致。
3.经过大约5到6次迭代,这些博弈基本上都趋同于稳定的平衡。
4.尽管嵌入模型ImageBind是多模态的,但连续图像嵌入和文本嵌入之间的距离远大于连续图像或连续描述之间的距离。总的来说,它们遵循相同的趋势,但程度较轻,这就是我没有在图表中包含它们的原因。
来源:https://towardsdatascience.com/ai-telephone-a-battle-of-multimodal-models-282b01daf044

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消