











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






解决多标签分类问题(包括案例研究)
2017年09月01日 由 yining 发表
623497
0
由于某些原因,回归和分类问题总会引起机器学习领域的大部分关注。多标签分类在数据科学中是一个比较令人头疼的问题。在这篇文章中,我将给你一个直观的解释,说明什么是多标签分类,以及如何解决这个问题。
让我们来看看下面的图片。

如果我问你这幅图中有一栋房子,你会怎样回答? 选项为“Yes”或“No”。
或者这样问,所有的东西(或标签)与这幅图有什么关系?

在这些类型的问题中,我们有一组目标变量,被称为多标签分类问题。那么,这两种情况有什么不同吗? 很明显,有很大的不同,因为在第二种情况下,任何图像都可能包含不同图像的多个不同的标签。
但在深入讲解多标签之前,我想解释一下它与多分类问题有何不同,让我们试着去理解这两组问题的不同之处。
用一个例子来理解这两者之间的区别。
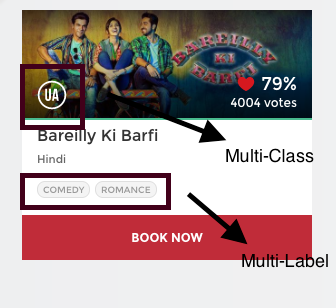
对于任何一部电影,电影的中央委员会会根据电影的内容颁发证书。例如,如果你看上面的图片,这部电影被评为“UA”(意思是“12岁以下儿童需在父母陪同下观看”)。还有其他类型的证书类,如“A”(仅限于成人)或“U”(不受限制的公开放映),但可以肯定的是,每部电影只能在这三种类型的证书中进行分类。简而言之,有多个类别,但每个实例只分配一个,因此这些问题被称为多类分类问题。
同时,你回顾一下这张图片,这部电影被归类为喜剧和浪漫类型。但不同的是,这一次,每部电影都有可能被分成一个或多个不同的类别。
所以每个实例都可以使用多个类别进行分配。因此,这些类型的问题被称为多标签分类问题。
现在你应该可以区分多标签和多分类问题了。那么,让我们开始处理多标签这种类型的问题。
Scikit-learn提供了一个独立的库scikit-multilearn,用于多种标签分类。为了更好的理解,让我们开始在一个多标签的数据集上进行练习。scikit-multilearn库地址:http://scikit.ml/api/datasets.html
你可以从MULAN package提供的存储库中找到实际的数据集。这些数据集以ARFF格式呈现。存储库地址:http://mulan.sourceforge.net/datasets-mlc.html
因此,为了开始使用这些数据集,请查看下面的Python代码,将其加载到你的计算机上。在这里,我已经从存储库中下载了酵母(yeast)数据集。
这就是数据集的样子。
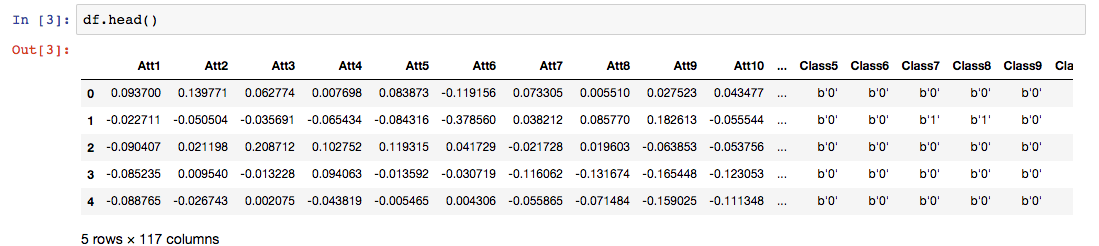
在这里,Att表示属性或独立变量,class表示目标变量。
出于实践目的,我们有另一个选项来生成一个人工的多标签数据集。
让我们了解一下上面所使用的参数。
sparse(稀疏):如果是True,返回一个稀疏矩阵,稀疏矩阵表示一个有大量零元素的矩阵。
n_labels:每个实例的标签的平均数量。
return_indicator:“sparse”在稀疏的二进制指示器格式中返回Y。
allow_unlabeled:如果是True,有些实例可能不属于任何类。
你一定会注意到,我们到处都使用了稀疏矩阵,而scikit-multilearn也建议使用稀疏格式的数据,因为在实际数据集中非常罕见。一般来说,分配给每个实例的标签的数量要少得多。
好了,现在我们已经准备好了数据集,让我们快速学习解决多标签问题的技术。
基本上,有三种方法来解决一个多标签分类问题,即:
在这个方法中,我们将尝试把多标签问题转换为单标签问题。这种方法可以用三种不同的方式进行:
4.4.1二元关联(Binary Relevance)
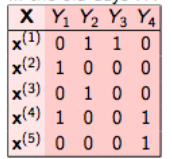
这是最简单的技术,它基本上把每个标签当作单独的一个类分类问题。例如,让我们考虑如下所示的一个案例。我们有这样的数据集,X是独立的特征,Y是目标变量。
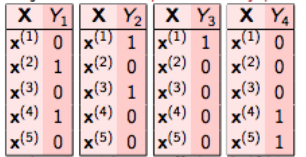
在二元关联中,这个问题被分解成4个不同的类分类问题,如下图所示。
我们不需要手动操作,multi-learn库在python中提供了它的实现。那么,让我们看看它在随机生成的数据上的实现。
注意:在这里,我们使用了Naive Bayes的算法,你也可以使用任何其他的分类算法。
现在,在一个多标签分类问题中,我们不能简单地用我们的标准来计算我们的预测的准确性。所以,我们将使用accuracy score。这个函数计算子集的精度,这意味着预测的标签集应该与真正的标签集完全匹配。
那么,让我们计算一下预测的准确性。
我们的准确率达到了45%,还不算太糟。它是最简单和有效的方法,但是这种方法的惟一缺点是它不考虑标签的相关性,因为它单独处理每个目标变量。
4.1.2分类器链(Classifier Chains)
在这种情况下,第一个分类器只在输入数据上进行训练,然后每个分类器都在输入空间和链上的所有之前的分类器上进行训练。
让我们试着通过一个例子来理解这个问题。在下面给出的数据集里,我们将X作为输入空间,而Y作为标签。
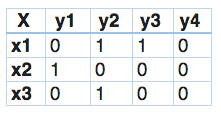
在分类器链中,这个问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量。

这与二元关联非常相似,唯一的区别在于它是为了保持标签相关性而形成的。那么,让我们尝试使用multi-learn库来实现它。
我们可以看到,使用这个我们得到了21%的准确率,这比二元关联要低得多。可能是因为没有标签相关性,因为我们已经随机生成了数据。
4.1.3标签Powerset(Label Powerset)
在这方面,我们将问题转化为一个多类问题,一个多类分类器在训练数据中发现的所有唯一的标签组合上被训练。让我们通过一个例子来理解它。
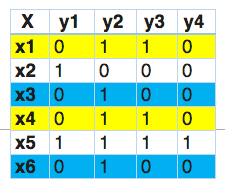
在这一点上,我们发现x1和x4有相同的标签。同样的,x3和x6有相同的标签。因此,标签powerset将这个问题转换为一个单一的多类问题,如下所示。
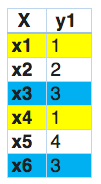
因此,标签powerset给训练集中的每一个可能的标签组合提供了一个独特的类。让我们看看它在Python中的实现。
这使我们在之前讨论过的三个问题中得到了最高的准确性,57%。唯一的缺点是随着训练数据的增加,类的数量也会增加。因此,增加了模型的复杂性,并降低了精确度。
现在,让我们看一下解决多标签分类问题的第二种方法。
改编算法来直接执行多标签分类,而不是将问题转化为不同的问题子集。例如,kNN的多标签版本是由MLkNN表示的。那么,让我们快速地在我们的随机生成的数据集上实现这个。
很好,你的测试数据已经达到了69%的准确率。
在一些算法中,例如随机森林(Random Forest)和岭回归(Ridge regression),Sci-kit learn提供了多标签分类的内置支持。因此,你可以直接调用它们并预测输出。
如果你想了解更多关于其他类型的改编算法,你可以查看multi-learn库。地址:http://scikit.ml/api/api/skmultilearn.adapt.html#module-skmultilearn.adapt
集成总是能产生更好的效果。Scikit-Multilearn库提供不同的组合分类功能,你可以使用它来获得更好的结果。
对于直接实现,你可以查看:http://scikit.ml/api/classify.html#ensemble-approaches
在现实世界中,多标签分类问题非常普遍。所以,来看看我们能在哪些领域找到它们。
我们知道歌曲会被分类为不同的流派。他们也被分类为,如“放松的平静”,或“悲伤的孤独”等等情感或情绪的基础。
来源:http://lpis.csd.auth.gr/publications/tsoumakas-ismir08.pdf
使用图像的多标签分类也有广泛的应用。图像可以被标记为不同的对象、人或概念。

多标签分类在生物信息学领域有很多用途,例如,在酵母数据集中的基因分类。它还被用来使用几个未标记的蛋白质来预测蛋白质的多重功能。
谷歌新闻所做的是,将每条新闻都标记为一个或多个类别,这样它就会显示在不同的类别之下。
例如,看看下面的图片。
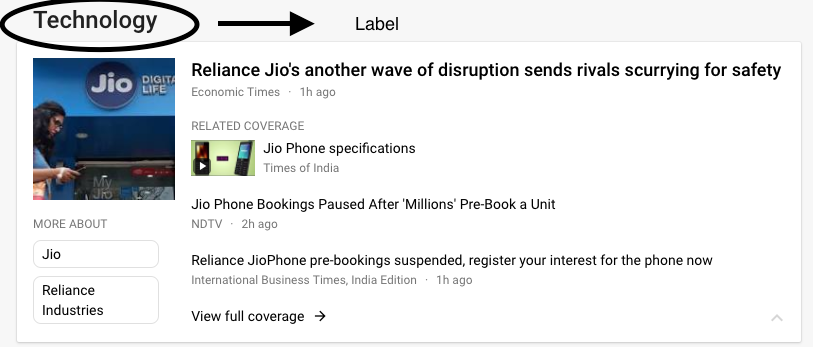
同样的新闻出现在“Technology”,“Latest” 等类别中,因为它已经被分类为不同的标签。从而使其成为一个多标签分类问题。
1.多标签分类是什么?
让我们来看看下面的图片。
如果我问你这幅图中有一栋房子,你会怎样回答? 选项为“Yes”或“No”。
或者这样问,所有的东西(或标签)与这幅图有什么关系?
在这些类型的问题中,我们有一组目标变量,被称为多标签分类问题。那么,这两种情况有什么不同吗? 很明显,有很大的不同,因为在第二种情况下,任何图像都可能包含不同图像的多个不同的标签。
但在深入讲解多标签之前,我想解释一下它与多分类问题有何不同,让我们试着去理解这两组问题的不同之处。
2.多标签vs多分类
用一个例子来理解这两者之间的区别。
对于任何一部电影,电影的中央委员会会根据电影的内容颁发证书。例如,如果你看上面的图片,这部电影被评为“UA”(意思是“12岁以下儿童需在父母陪同下观看”)。还有其他类型的证书类,如“A”(仅限于成人)或“U”(不受限制的公开放映),但可以肯定的是,每部电影只能在这三种类型的证书中进行分类。简而言之,有多个类别,但每个实例只分配一个,因此这些问题被称为多类分类问题。
同时,你回顾一下这张图片,这部电影被归类为喜剧和浪漫类型。但不同的是,这一次,每部电影都有可能被分成一个或多个不同的类别。
所以每个实例都可以使用多个类别进行分配。因此,这些类型的问题被称为多标签分类问题。
现在你应该可以区分多标签和多分类问题了。那么,让我们开始处理多标签这种类型的问题。
3.加载和生成多标签数据集
Scikit-learn提供了一个独立的库scikit-multilearn,用于多种标签分类。为了更好的理解,让我们开始在一个多标签的数据集上进行练习。scikit-multilearn库地址:http://scikit.ml/api/datasets.html
你可以从MULAN package提供的存储库中找到实际的数据集。这些数据集以ARFF格式呈现。存储库地址:http://mulan.sourceforge.net/datasets-mlc.html
因此,为了开始使用这些数据集,请查看下面的Python代码,将其加载到你的计算机上。在这里,我已经从存储库中下载了酵母(yeast)数据集。
import scipy
from scipy.io import arff
data, meta = scipy.io.arff.loadarff('/Users/shubhamjain/Documents/yeast/yeast-train.arff')
df = pd.DataFrame(data)
这就是数据集的样子。
在这里,Att表示属性或独立变量,class表示目标变量。
出于实践目的,我们有另一个选项来生成一个人工的多标签数据集。
from sklearn.datasets import make_multilabel_classification
# this will generate a random multi-label dataset
X, y = make_multilabel_classification(sparse = True, n_labels = 20,
return_indicator = 'sparse', allow_unlabeled = False)
让我们了解一下上面所使用的参数。
sparse(稀疏):如果是True,返回一个稀疏矩阵,稀疏矩阵表示一个有大量零元素的矩阵。
n_labels:每个实例的标签的平均数量。
return_indicator:“sparse”在稀疏的二进制指示器格式中返回Y。
allow_unlabeled:如果是True,有些实例可能不属于任何类。
你一定会注意到,我们到处都使用了稀疏矩阵,而scikit-multilearn也建议使用稀疏格式的数据,因为在实际数据集中非常罕见。一般来说,分配给每个实例的标签的数量要少得多。
好了,现在我们已经准备好了数据集,让我们快速学习解决多标签问题的技术。
4.解决多标签分类问题的技术
基本上,有三种方法来解决一个多标签分类问题,即:
- 问题转换
- 改编算法
- 集成方法
4.1问题转换
在这个方法中,我们将尝试把多标签问题转换为单标签问题。这种方法可以用三种不同的方式进行:
- 二元关联(Binary Relevance)
- 分类器链(Classifier Chains)
- 标签Powerset(Label Powerset)
4.4.1二元关联(Binary Relevance)
这是最简单的技术,它基本上把每个标签当作单独的一个类分类问题。例如,让我们考虑如下所示的一个案例。我们有这样的数据集,X是独立的特征,Y是目标变量。
在二元关联中,这个问题被分解成4个不同的类分类问题,如下图所示。
我们不需要手动操作,multi-learn库在python中提供了它的实现。那么,让我们看看它在随机生成的数据上的实现。
# using binary relevance
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.naive_bayes import GaussianNB
# initialize binary relevance multi-label classifier
# with a gaussian naive bayes base classifier
classifier = BinaryRelevance(GaussianNB())
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
注意:在这里,我们使用了Naive Bayes的算法,你也可以使用任何其他的分类算法。
现在,在一个多标签分类问题中,我们不能简单地用我们的标准来计算我们的预测的准确性。所以,我们将使用accuracy score。这个函数计算子集的精度,这意味着预测的标签集应该与真正的标签集完全匹配。
那么,让我们计算一下预测的准确性。
from sklearn.metrics import accuracy_score
accuracy_score(y_test,predictions)
0.45454545454545453
我们的准确率达到了45%,还不算太糟。它是最简单和有效的方法,但是这种方法的惟一缺点是它不考虑标签的相关性,因为它单独处理每个目标变量。
4.1.2分类器链(Classifier Chains)
在这种情况下,第一个分类器只在输入数据上进行训练,然后每个分类器都在输入空间和链上的所有之前的分类器上进行训练。
让我们试着通过一个例子来理解这个问题。在下面给出的数据集里,我们将X作为输入空间,而Y作为标签。
在分类器链中,这个问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量。
这与二元关联非常相似,唯一的区别在于它是为了保持标签相关性而形成的。那么,让我们尝试使用multi-learn库来实现它。
# using classifier chains
from skmultilearn.problem_transform import ClassifierChain
from sklearn.naive_bayes import GaussianNB
# initialize classifier chains multi-label classifier
# with a gaussian naive bayes base classifier
classifier = ClassifierChain(GaussianNB())
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.21212121212121213
我们可以看到,使用这个我们得到了21%的准确率,这比二元关联要低得多。可能是因为没有标签相关性,因为我们已经随机生成了数据。
4.1.3标签Powerset(Label Powerset)
在这方面,我们将问题转化为一个多类问题,一个多类分类器在训练数据中发现的所有唯一的标签组合上被训练。让我们通过一个例子来理解它。
在这一点上,我们发现x1和x4有相同的标签。同样的,x3和x6有相同的标签。因此,标签powerset将这个问题转换为一个单一的多类问题,如下所示。
因此,标签powerset给训练集中的每一个可能的标签组合提供了一个独特的类。让我们看看它在Python中的实现。
# using Label Powerset
from skmultilearn.problem_transform import LabelPowerset
from sklearn.naive_bayes import GaussianNB
# initialize Label Powerset multi-label classifier
# with a gaussian naive bayes base classifier
classifier = LabelPowerset(GaussianNB())
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.5757575757575758
这使我们在之前讨论过的三个问题中得到了最高的准确性,57%。唯一的缺点是随着训练数据的增加,类的数量也会增加。因此,增加了模型的复杂性,并降低了精确度。
现在,让我们看一下解决多标签分类问题的第二种方法。
4.2改编算法
改编算法来直接执行多标签分类,而不是将问题转化为不同的问题子集。例如,kNN的多标签版本是由MLkNN表示的。那么,让我们快速地在我们的随机生成的数据集上实现这个。
from skmultilearn.adapt import MLkNN
classifier = MLkNN(k=20)
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.69
很好,你的测试数据已经达到了69%的准确率。
在一些算法中,例如随机森林(Random Forest)和岭回归(Ridge regression),Sci-kit learn提供了多标签分类的内置支持。因此,你可以直接调用它们并预测输出。
如果你想了解更多关于其他类型的改编算法,你可以查看multi-learn库。地址:http://scikit.ml/api/api/skmultilearn.adapt.html#module-skmultilearn.adapt
4.3集成方法
集成总是能产生更好的效果。Scikit-Multilearn库提供不同的组合分类功能,你可以使用它来获得更好的结果。
对于直接实现,你可以查看:http://scikit.ml/api/classify.html#ensemble-approaches
5.案例研究
在现实世界中,多标签分类问题非常普遍。所以,来看看我们能在哪些领域找到它们。
5.1音频分类
我们知道歌曲会被分类为不同的流派。他们也被分类为,如“放松的平静”,或“悲伤的孤独”等等情感或情绪的基础。
来源:http://lpis.csd.auth.gr/publications/tsoumakas-ismir08.pdf
5.2图像分类
使用图像的多标签分类也有广泛的应用。图像可以被标记为不同的对象、人或概念。
5.3生物信息学
多标签分类在生物信息学领域有很多用途,例如,在酵母数据集中的基因分类。它还被用来使用几个未标记的蛋白质来预测蛋白质的多重功能。
5.4文本分类
谷歌新闻所做的是,将每条新闻都标记为一个或多个类别,这样它就会显示在不同的类别之下。
例如,看看下面的图片。
图片来源:https://news.google.com/news/headlines/section/topic/TECHNOLOGY.en_in/Technology?ned=in&hl=en-IN
同样的新闻出现在“Technology”,“Latest” 等类别中,因为它已经被分类为不同的标签。从而使其成为一个多标签分类问题。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消