











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌推出AudioPaLM:文本与语音相遇的地方
2023年06月27日 由 daydream 发表
843584
0
大型科技公司谷歌在生成式人工智能领域大放异彩,推出了AudioPaLM,这是一个全新的多模态语言模型,结合了谷歌于2023年Google I/O会议上发布的大型语言模型PaLM-2和去年发布的生成式音频模型AudioLM的能力。AudioPaLM建立了一个全面的多模态框架,能够处理和生成文本内容和口语语言。
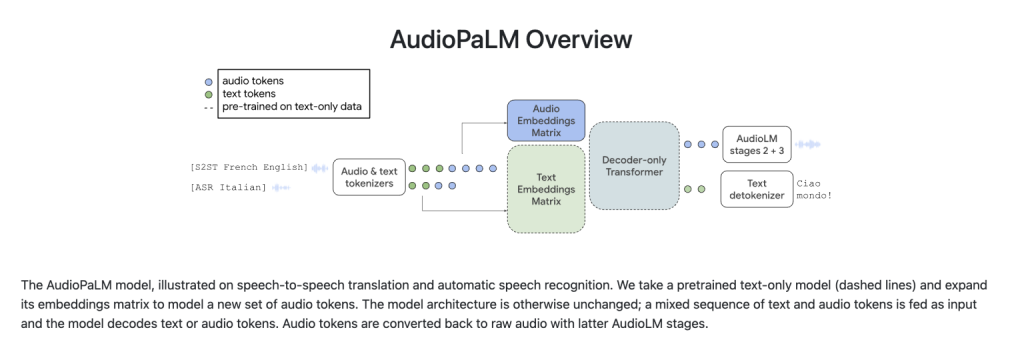
AudioPaLM的应用领域非常广泛,包括语音识别和语音对语音翻译等。借助AudioLM的专业知识,AudioPaLM继承了捕捉说话者身份和语调等非语言线索的能力,同时还整合了PaLM-2等基于文本的语言模型中蕴含的语言知识。此外,AudioPaLM展示了音频语言模型的独特特征,例如基于简明的口语提示将语音从一种语言转换为另一种语言的能力。
AudioPaLM以大规模Transformer模型为基础框架,通过增加专门的音频标记来扩展现有的基于文本的语言模型的词汇表。这样,配合基本的任务描述,就能训练一个仅包含解码器的单一模型,能够处理涉及语音和文本的各种组合任务。这些任务包括语音识别、文本到语音合成和语音对语音翻译。通过这种方法,我们将传统上分立的模型整合到一个统一的架构和训练过程中。
AudioPaLM在语音翻译基准测试中取得了出色的性能,并在语音识别任务中取得了有竞争力的结果。它还展示了将语音转换为文本的能力,甚至对以前未见过的语言对也不需要先前的训练。
除了语音生成,AudioPaLM还可以生成包括原始语言的转录或直接翻译的转录,或者生成原始语音的语音文本。AudioPaLM在语音翻译基准测试中取得了最佳结果,并在语音识别任务中展现出有竞争力的性能。
该模型还可以保留副语言信息,例如说话人身份和语调,这些信息在传统的语音到文本翻译系统中经常丢失。该系统有望在基于自动和人工评估的语音质量方面优于现有解决方案。
研究人员在论文中表示:“在音频标记化方面还存在进一步的研究机会,旨在识别理想的音频标记属性,开发测量技术,并进行相应的优化。此外,在生成式音频任务中,需要更加完善的基准测试和度量标准,以推动研究进展,因为当前的基准测试主要集中在语音识别和翻译领域。”
科技巨头在音乐生成领域的战斗刚刚开始
这并不是谷歌第一次在音频生成领域推出一些东西。早在一月份,它就发布了MusicLM,这是一种高保真音乐生成模型,可以从基于AudioLM构建的文本描述中创建音乐。它使用分层序列到序列方法来生成 24 kHz 的稳定音乐。它还引入了MusicCaps,这是一个由5.5k音乐文本对组成的精选数据集,旨在评估文本到音乐的生成。
谷歌的竞争对手在这个领域也不甘落后
Microsoft最近推出了Pengi,这是一种音频语言模型,利用了从文本生成任务到音频任务的迁移学习。通过整合音频和文本输入,Pengi可以生成自由形式的文本输出,无需额外的微调。
此外,由马克·扎克伯格领导的Meta还推出了MusicGen,它利用了Transformer架构的强大功能,根据文本提示创作音乐,并将生成的音乐与现有的旋律结合起来。与语言模型类似,MusicGen可以预测音乐作品的下一节,从而创作出连贯和结构化的作品。它使用Meta的EnCodec音频标记器以并行方式高效处理标记。该模型训练于2万小时的授权音乐数据集,确保能够获得各种音乐风格和作品。它还发布了Voicebox,这是一个多语言生成式AI模型,可以通过上下文学习执行各种语音生成任务,甚至是它没有明确训练过的任务。
然而,目前被认为是生成AI领域领导者的Microsoft支持的OpenAI似乎在这场音乐生成的竞赛中迷失了方向。ChatGPT创建者最近没有在这个领域发布任何公告。
来源:https://analyticsindiamag.com/google-unveils-audiopalm-where-text-meets-voice/
AudioPaLM的应用领域非常广泛,包括语音识别和语音对语音翻译等。借助AudioLM的专业知识,AudioPaLM继承了捕捉说话者身份和语调等非语言线索的能力,同时还整合了PaLM-2等基于文本的语言模型中蕴含的语言知识。此外,AudioPaLM展示了音频语言模型的独特特征,例如基于简明的口语提示将语音从一种语言转换为另一种语言的能力。
AudioPaLM以大规模Transformer模型为基础框架,通过增加专门的音频标记来扩展现有的基于文本的语言模型的词汇表。这样,配合基本的任务描述,就能训练一个仅包含解码器的单一模型,能够处理涉及语音和文本的各种组合任务。这些任务包括语音识别、文本到语音合成和语音对语音翻译。通过这种方法,我们将传统上分立的模型整合到一个统一的架构和训练过程中。
AudioPaLM在语音翻译基准测试中取得了出色的性能,并在语音识别任务中取得了有竞争力的结果。它还展示了将语音转换为文本的能力,甚至对以前未见过的语言对也不需要先前的训练。
除了语音生成,AudioPaLM还可以生成包括原始语言的转录或直接翻译的转录,或者生成原始语音的语音文本。AudioPaLM在语音翻译基准测试中取得了最佳结果,并在语音识别任务中展现出有竞争力的性能。
该模型还可以保留副语言信息,例如说话人身份和语调,这些信息在传统的语音到文本翻译系统中经常丢失。该系统有望在基于自动和人工评估的语音质量方面优于现有解决方案。
研究人员在论文中表示:“在音频标记化方面还存在进一步的研究机会,旨在识别理想的音频标记属性,开发测量技术,并进行相应的优化。此外,在生成式音频任务中,需要更加完善的基准测试和度量标准,以推动研究进展,因为当前的基准测试主要集中在语音识别和翻译领域。”
科技巨头在音乐生成领域的战斗刚刚开始
这并不是谷歌第一次在音频生成领域推出一些东西。早在一月份,它就发布了MusicLM,这是一种高保真音乐生成模型,可以从基于AudioLM构建的文本描述中创建音乐。它使用分层序列到序列方法来生成 24 kHz 的稳定音乐。它还引入了MusicCaps,这是一个由5.5k音乐文本对组成的精选数据集,旨在评估文本到音乐的生成。
谷歌的竞争对手在这个领域也不甘落后
Microsoft最近推出了Pengi,这是一种音频语言模型,利用了从文本生成任务到音频任务的迁移学习。通过整合音频和文本输入,Pengi可以生成自由形式的文本输出,无需额外的微调。
此外,由马克·扎克伯格领导的Meta还推出了MusicGen,它利用了Transformer架构的强大功能,根据文本提示创作音乐,并将生成的音乐与现有的旋律结合起来。与语言模型类似,MusicGen可以预测音乐作品的下一节,从而创作出连贯和结构化的作品。它使用Meta的EnCodec音频标记器以并行方式高效处理标记。该模型训练于2万小时的授权音乐数据集,确保能够获得各种音乐风格和作品。它还发布了Voicebox,这是一个多语言生成式AI模型,可以通过上下文学习执行各种语音生成任务,甚至是它没有明确训练过的任务。
然而,目前被认为是生成AI领域领导者的Microsoft支持的OpenAI似乎在这场音乐生成的竞赛中迷失了方向。ChatGPT创建者最近没有在这个领域发布任何公告。
来源:https://analyticsindiamag.com/google-unveils-audiopalm-where-text-meets-voice/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消