











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






计算机视觉提示和技巧(二)
2023年06月27日 由 Alex 发表
121163
0
在第一部分中,讲述了使用FiftyOne 的实用指南。在本文中将继续讨论嵌入。
FiftyOne是什么?
FiftyOne是一个开源机器学习工具集,它使数据科学团队能够通过帮助他们管理高质量的数据集、评估模型、发现错误、可视化嵌入并更快地投入生产,从而提高计算机视觉模型的性能。
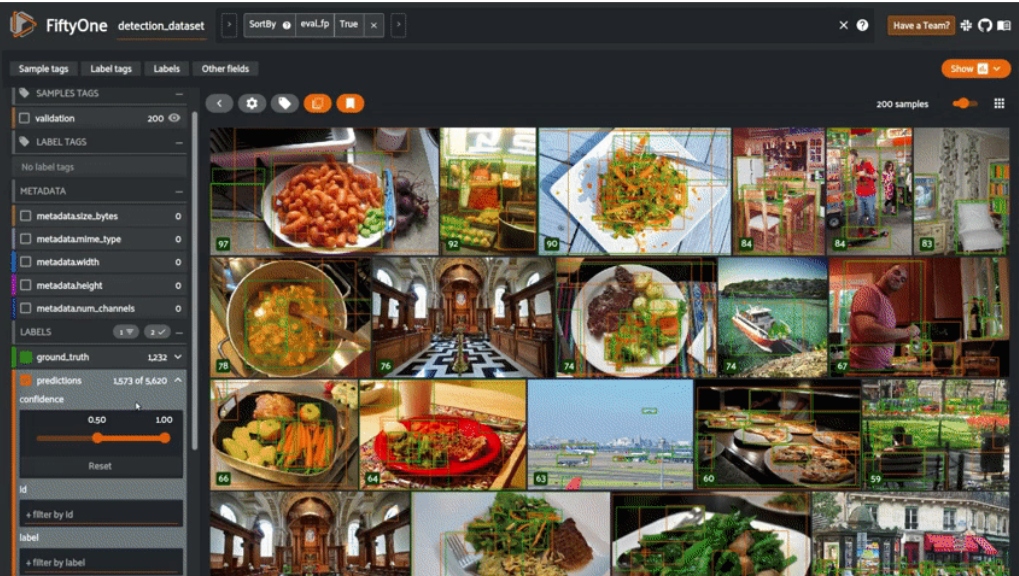
上图显示已经使它启动和运行。
接下来,让我们深入了解下计算机视觉提示和技巧。
嵌入入门介绍
嵌入是在计算机视觉中用于将图像或视频的视觉特征表示为数值向量的技术。这些向量通常比原始源媒体的维度低,捕捉到了视觉数据的基本特征,可以用于后续的任务,如图像分类、目标检测和图像检索。
在FiftyOne中,嵌入由FiftyOne Brain管理,FiftyOne Brain是一个提供强大的机器学习技术的库,旨在将你对数据的整理从艺术形式转变为可量化的科学形式。使用嵌入使得分析和可视化数据集变得容易,并加速了机器学习工作流程。
计算嵌入的样本属性(唯一性、相似性等)
如果想要在计算机视觉中利用嵌入的优势,但不确定从何处开始,FiftyOne可以帮助你。任何利用嵌入的FiftyOne Brain方法都配备了一个默认的通用嵌入模型。
这意味着在许多情况下,你可以使用开箱即用的Brain方法来评估数据集中样本的属性。
例如,在训练模型时,唯一的样本可以帮助模型理解和表示数据集中的分布。为了辅助这个过程,FiftyOne Brain提供了一种计算图像"唯一性"的方法,帮助你回答诸如"我应该选择哪些数据进行注释?"这样的问题。下面是如何轻松计算快速入门数据集中图像的唯一性:
相似地,在构建数据集或训练模型时,你是否曾经想过找到与感兴趣的图像或对象相似的示例?FiftyOne Brain也可以轻松计算可视化相似性。你可以使用默认(MobileNetv2)嵌入模型计算数据集中样本的相似性,并将结果存储在Brain key 中image_sim:
然后,你可以根据相似性对样本进行排序,或使用此信息查找潜在的重复图像。
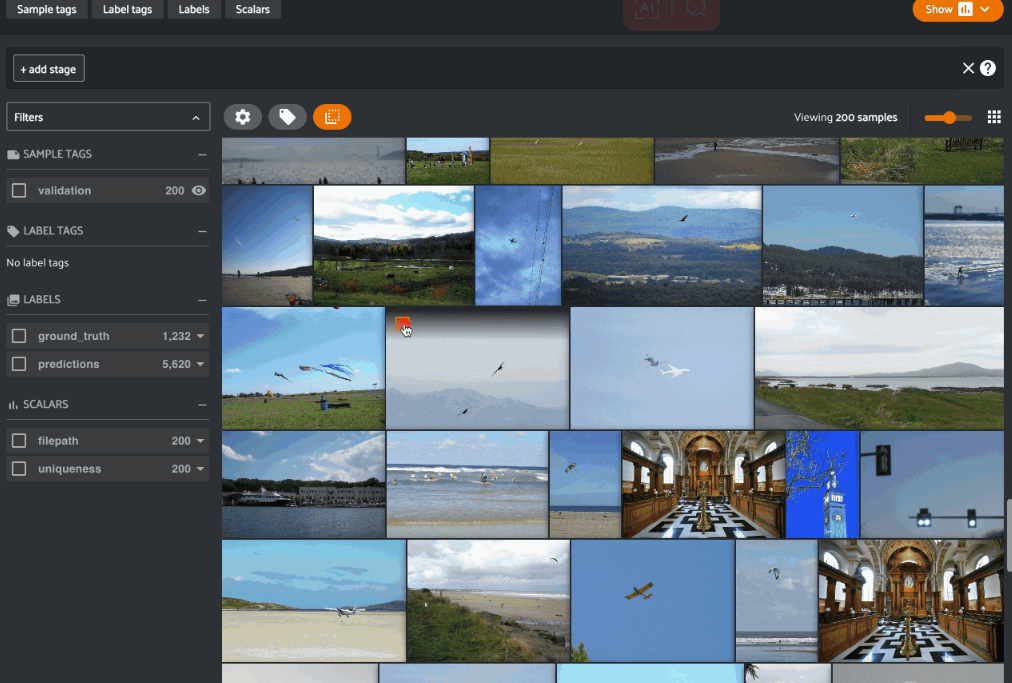
可视化嵌入
在计算机视觉中,嵌入的另一个应用是可视化。通过将嵌入与uMAP或tSNE等降维技术配对,你可以将数据绘制到低维空间中,从而能够识别类簇并更好地理解数据中的模式。
在FiftyOne中,所有将嵌入、降维技术和绘图结合起来的逻辑都封装在FiftyOne Brain的compute_visualization()方法的易于使用的界面中。
如果我们想为快速入门数据集生成默认嵌入,并使用uMAP将嵌入向量的维度降低到两个维度以便可视化数据集,可以运行以下代码:
然后,我们可以可视化这些结果,并根据标签进行着色。
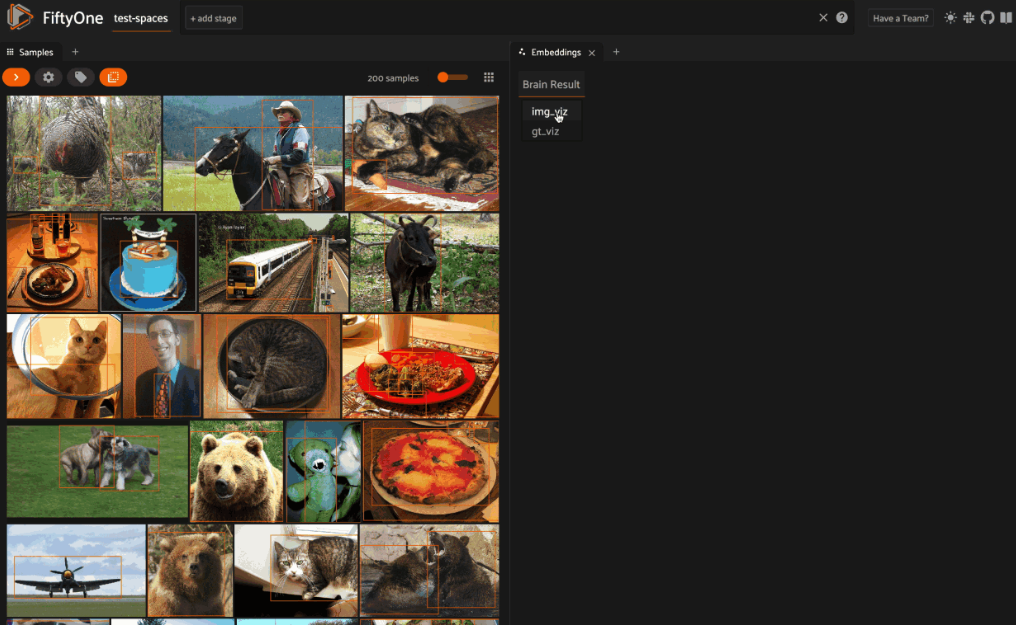
使用自己的嵌入模型
如果你正在处理更专业化或特定于应用的计算机视觉数据,使用自己的自定义模型生成嵌入可能会有所帮助。幸运的是,所有利用嵌入的FiftyOne Brain方法,从compute_uniqueness()和compute_similarity()到compute_visualization()都支持这一点!
任何使用嵌入的FiftyOne Brain方法都允许你以三种方式指定自己的嵌入。
前两种方法涉及可选的embeddings参数,这对于已经预先计算嵌入的情况非常有用。你可以将已经预先计算的嵌入作为输入给出,形式为num_samples x num_embedding_dims的数组,或者可以传递数据集中包含嵌入的字段的名称:
作为替代方案,如果你还没有计算嵌入,可以传入模型,供FiftyOne用于计算嵌入:
任何具有logits的模型都应该有效,你可以通过验证print(model.has_embeddings)是否返回True来检查模型是否支持嵌入。
计算对象补丁的嵌入
正如你可以计算图像的嵌入一样,FiftyOne允许你计算对象补丁的嵌入,使用内置方法compute_patch_embeddings()以类似于compute_embeddings()的方式工作。为了计算ground truth对象的嵌入,我们只需使用“ground_truth”作为patches字段:
或者,当你指定patches_field参数时,Brain方法如compute_similarity()和compute_visualization()原生支持补丁数据:
使用CLIP执行零样本分类
在过去的几年中,嵌入技术的进步使计算机视觉领域出现了一系列新的应用和用例。在这方面最具突破性的一个进展,是嵌入多模态数据到一个共享嵌入空间的技术的发展和完善。
特别是,在OpenAI的CLIP模型中,开创性的对比式语言-图像预训练使得可以将知识从一个领域转移到另一个领域。这为零样本计算机视觉模型的显著改进铺平了道路。
FiftyOne模型库中CLIP多模态嵌入模型的PyTorch实现使得利用CLIP的多模态嵌入进行图像分类变得非常简单。
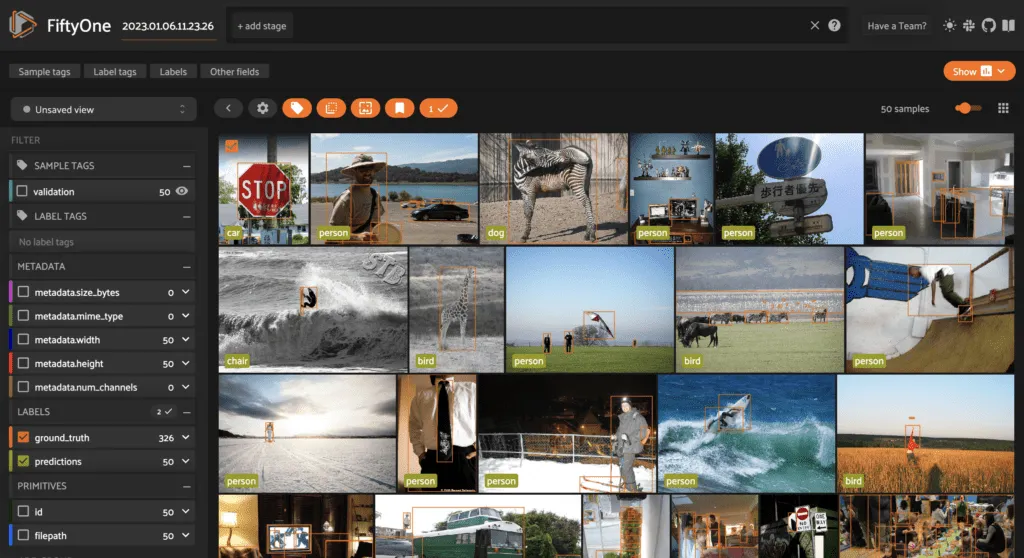
下面是在COCO验证数据上执行零样本分类并使用自定义类别标签的示例:
来源:https://medium.com/voxel51/fiftyone-computer-vision-embeddings-tips-and-tricks-mar-31-2023-625b9d9202cd
FiftyOne是什么?
FiftyOne是一个开源机器学习工具集,它使数据科学团队能够通过帮助他们管理高质量的数据集、评估模型、发现错误、可视化嵌入并更快地投入生产,从而提高计算机视觉模型的性能。
上图显示已经使它启动和运行。
接下来,让我们深入了解下计算机视觉提示和技巧。
嵌入入门介绍
嵌入是在计算机视觉中用于将图像或视频的视觉特征表示为数值向量的技术。这些向量通常比原始源媒体的维度低,捕捉到了视觉数据的基本特征,可以用于后续的任务,如图像分类、目标检测和图像检索。
在FiftyOne中,嵌入由FiftyOne Brain管理,FiftyOne Brain是一个提供强大的机器学习技术的库,旨在将你对数据的整理从艺术形式转变为可量化的科学形式。使用嵌入使得分析和可视化数据集变得容易,并加速了机器学习工作流程。
计算嵌入的样本属性(唯一性、相似性等)
如果想要在计算机视觉中利用嵌入的优势,但不确定从何处开始,FiftyOne可以帮助你。任何利用嵌入的FiftyOne Brain方法都配备了一个默认的通用嵌入模型。
这意味着在许多情况下,你可以使用开箱即用的Brain方法来评估数据集中样本的属性。
例如,在训练模型时,唯一的样本可以帮助模型理解和表示数据集中的分布。为了辅助这个过程,FiftyOne Brain提供了一种计算图像"唯一性"的方法,帮助你回答诸如"我应该选择哪些数据进行注释?"这样的问题。下面是如何轻松计算快速入门数据集中图像的唯一性:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# 加载数据集
dataset = foz.load_zoo_dataset("quickstart")
fob.compute_uniqueness(dataset)
相似地,在构建数据集或训练模型时,你是否曾经想过找到与感兴趣的图像或对象相似的示例?FiftyOne Brain也可以轻松计算可视化相似性。你可以使用默认(MobileNetv2)嵌入模型计算数据集中样本的相似性,并将结果存储在Brain key 中image_sim:
fob.compute_similarity(dataset, brain_key="image_sim")
然后,你可以根据相似性对样本进行排序,或使用此信息查找潜在的重复图像。
可视化嵌入
在计算机视觉中,嵌入的另一个应用是可视化。通过将嵌入与uMAP或tSNE等降维技术配对,你可以将数据绘制到低维空间中,从而能够识别类簇并更好地理解数据中的模式。
在FiftyOne中,所有将嵌入、降维技术和绘图结合起来的逻辑都封装在FiftyOne Brain的compute_visualization()方法的易于使用的界面中。
如果我们想为快速入门数据集生成默认嵌入,并使用uMAP将嵌入向量的维度降低到两个维度以便可视化数据集,可以运行以下代码:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
# 图像嵌入
fob.compute_visualization(dataset, brain_key="img_viz")
# 对象补丁嵌入
fob.compute_visualization(
dataset, patches_field="ground_truth", brain_key="gt_viz"
)
session = fo.launch_app(dataset)
然后,我们可以可视化这些结果,并根据标签进行着色。
使用自己的嵌入模型
如果你正在处理更专业化或特定于应用的计算机视觉数据,使用自己的自定义模型生成嵌入可能会有所帮助。幸运的是,所有利用嵌入的FiftyOne Brain方法,从compute_uniqueness()和compute_similarity()到compute_visualization()都支持这一点!
任何使用嵌入的FiftyOne Brain方法都允许你以三种方式指定自己的嵌入。
前两种方法涉及可选的embeddings参数,这对于已经预先计算嵌入的情况非常有用。你可以将已经预先计算的嵌入作为输入给出,形式为num_samples x num_embedding_dims的数组,或者可以传递数据集中包含嵌入的字段的名称:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# The BDD dataset must be manually downloaded. See the zoo docs for details
source_dir = "/path/to/dir-with-bdd100k-files"
# Load dataset
dataset = foz.load_zoo_dataset(
"bdd100k", split="validation", source_dir=source_dir,
)
# Compute embeddings
# You will likely want to run this on a machine with GPU, as this requires
# running inference on 10,000 images
model = foz.load_zoo_model("mobilenet-v2-imagenet-torch")
# option 1
embeddings = dataset.compute_embeddings(model)
results = fob.compute_visualization(dataset, embeddings=embeddings)
# option 2
embeddings = dataset.compute_embeddings(model, embeddings_field = “my_embeddings”)
results = fob.compute_visualization(dataset, embeddings=”my_embeddings”)
作为替代方案,如果你还没有计算嵌入,可以传入模型,供FiftyOne用于计算嵌入:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# The BDD dataset must be manually downloaded. See the zoo docs for details
source_dir = "/path/to/dir-with-bdd100k-files"
# Load dataset
dataset = foz.load_zoo_dataset(
"bdd100k", split="validation", source_dir=source_dir,
)
# Compute embeddings
# You will likely want to run this on a machine with GPU, as this requires
# running inference on 10,000 images
model = foz.load_zoo_model("mobilenet-v2-imagenet-torch")
# option 3
results = fob.compute_visualization(dataset, model = model)
任何具有logits的模型都应该有效,你可以通过验证print(model.has_embeddings)是否返回True来检查模型是否支持嵌入。
计算对象补丁的嵌入
正如你可以计算图像的嵌入一样,FiftyOne允许你计算对象补丁的嵌入,使用内置方法compute_patch_embeddings()以类似于compute_embeddings()的方式工作。为了计算ground truth对象的嵌入,我们只需使用“ground_truth”作为patches字段:
import fiftyone as fo
import fiftyone.zoo as foz
# Load zoo model
model = foz.load_zoo_model("inception-v3-imagenet-torch")
print(model.has_embeddings) # True
# Load zoo dataset
ataset = foz.load_zoo_dataset("quickstart")
dataset.compute_patch_embeddings(
model,
"ground_truth",
embeddings_field = "gt_embed"
)
或者,当你指定patches_field参数时,Brain方法如compute_similarity()和compute_visualization()原生支持补丁数据:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# Load zoo model
model = foz.load_zoo_model("inception-v3-imagenet-torch")
print(model.has_embeddings) # True
# Load zoo dataset
dataset = foz.load_zoo_dataset("quickstart")
# compute similarity of ground truth patches
fob.compute_similarity(dataset, patches_field = "ground_truth")
使用CLIP执行零样本分类
在过去的几年中,嵌入技术的进步使计算机视觉领域出现了一系列新的应用和用例。在这方面最具突破性的一个进展,是嵌入多模态数据到一个共享嵌入空间的技术的发展和完善。
特别是,在OpenAI的CLIP模型中,开创性的对比式语言-图像预训练使得可以将知识从一个领域转移到另一个领域。这为零样本计算机视觉模型的显著改进铺平了道路。
FiftyOne模型库中CLIP多模态嵌入模型的PyTorch实现使得利用CLIP的多模态嵌入进行图像分类变得非常简单。
下面是在COCO验证数据上执行零样本分类并使用自定义类别标签的示例:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"coco-2017",
split="validation",
dataset_name=fo.get_default_dataset_name(),
max_samples=50,
shuffle=True,
)
model = foz.load_zoo_model("clip-vit-base32-torch")
dataset.apply_model(model, label_field="predictions")
session = fo.launch_app(dataset)
# Make zero-shot predictions with custom classes
model = foz.load_zoo_model(
"clip-vit-base32-torch",
text_prompt="A photo of a",
classes=["person", "dog", "cat", "bird", "car", "tree", "chair"],
)
dataset.apply_model(model, label_field="predictions")
session.refresh()
来源:https://medium.com/voxel51/fiftyone-computer-vision-embeddings-tips-and-tricks-mar-31-2023-625b9d9202cd

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
计算机视觉提示和技巧(一)
下一篇
LLM并不像你想象的那么聪明








广告


写评论取消
回复取消