











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






识别图像内容的人工智能新方法
2023年06月27日 由 Samoyed 发表
711732
0
生成式人工智能程序可以根据文本提示生成图像。这些模型在生成单个物体的图像时效果最好,创造完整的场景仍然很困难。来自ITC学院的UT研究人员Michael Ying Yang最近开发了一种新方法,可以从图像中绘制场景,作为生成逼真连贯图像的蓝本。他和他的团队最近在IEEE Transactions on Pattern Analysis and Machine Intelligence杂志上发表了他们的研究结果。
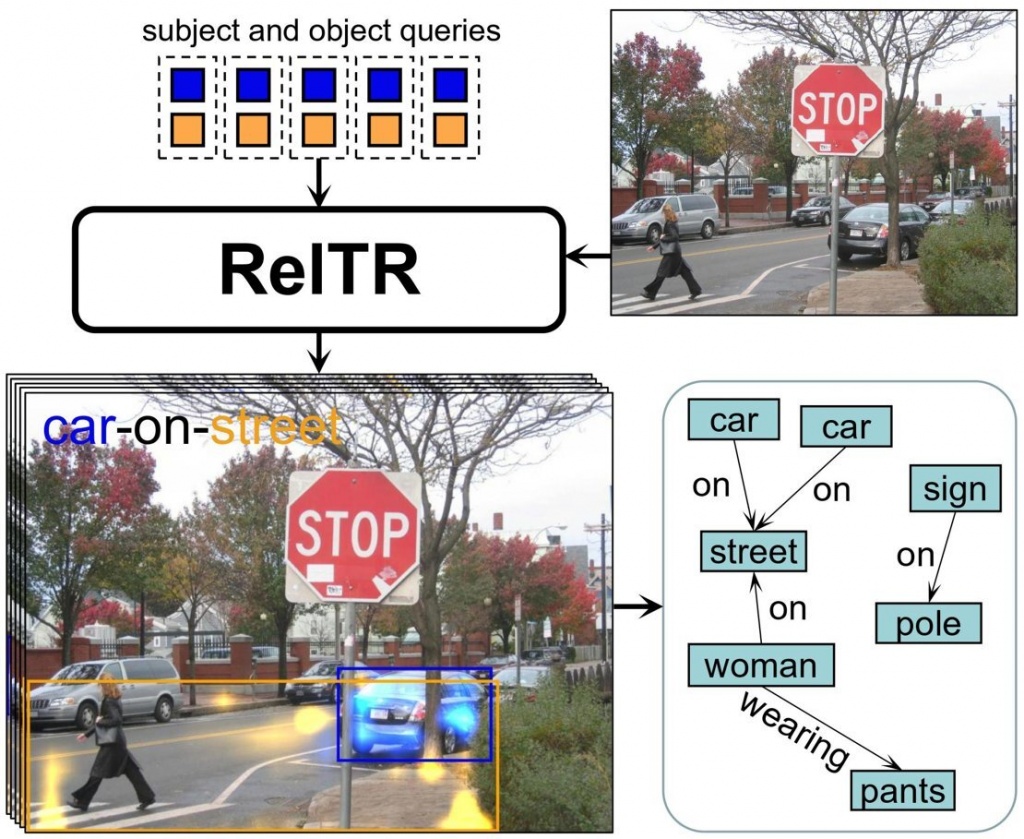
人类非常擅长定义对象之间的关系。“我们可以看到一把椅子在地板上,一只狗在街上走,但是人工智能模型很难发现这些。”地理信息科学和地球观测学院(ITC)场景理解组的助理教授Yang解释说。提高计算机检测和理解视觉关系的能力是图像生成所需的,并且对自动驾驶汽车和机器人的感知也有帮助。
从两阶段到单阶段
目前,有一些可以对图像的含义进行理解的方法,但速度很慢。这些方法采用两阶段的方法。首先,它们映射场景中的所有对象。在第二步中,一些特定的神经网络遍历所有可能的连接,然后用正确的关系标记它们。
这种方法必须通过的连接数量随着对象的数量呈指数增长。“我们的模型只需要一个步骤。它能同时自动预测主体、客体及其关系。”Yang说。
检测关系
对于这种单阶段方法,模型查看场景中物体的视觉特征,并关注与确定关系最相关的细节。它强调物体相互作用或相互联系的重要区域。这些技术和相对较少的训练数据足以识别不同对象之间最重要的关系。剩下唯一要做的就是生成它们如何连接的描述。
“该模型检测到在一张示例图片中,该男子很可能与棒球棒互动。然后训练它来描述最可能的关系:‘人——挥动——棒球棒,’”Yang说。
来源:https://techxplore.com/news/2023-06-ai-method-graphing-scenes-images.html
人类非常擅长定义对象之间的关系。“我们可以看到一把椅子在地板上,一只狗在街上走,但是人工智能模型很难发现这些。”地理信息科学和地球观测学院(ITC)场景理解组的助理教授Yang解释说。提高计算机检测和理解视觉关系的能力是图像生成所需的,并且对自动驾驶汽车和机器人的感知也有帮助。
从两阶段到单阶段
目前,有一些可以对图像的含义进行理解的方法,但速度很慢。这些方法采用两阶段的方法。首先,它们映射场景中的所有对象。在第二步中,一些特定的神经网络遍历所有可能的连接,然后用正确的关系标记它们。
这种方法必须通过的连接数量随着对象的数量呈指数增长。“我们的模型只需要一个步骤。它能同时自动预测主体、客体及其关系。”Yang说。
检测关系
对于这种单阶段方法,模型查看场景中物体的视觉特征,并关注与确定关系最相关的细节。它强调物体相互作用或相互联系的重要区域。这些技术和相对较少的训练数据足以识别不同对象之间最重要的关系。剩下唯一要做的就是生成它们如何连接的描述。
“该模型检测到在一张示例图片中,该男子很可能与棒球棒互动。然后训练它来描述最可能的关系:‘人——挥动——棒球棒,’”Yang说。
来源:https://techxplore.com/news/2023-06-ai-method-graphing-scenes-images.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消