











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌的PaLM-E将视觉和语言人工智能结合用于机器人控制
2023年06月28日 由 Susan 发表
109120
0
谷歌机器人团队的研究人员最近宣布了PaLM-E,它是他们的PaLM和Vision Transformer (ViT)模型的结合体,专门用于控制机器人。PaLM-E处理来自机器人传感器的多模态输入数据,并输出文本命令来控制机器人的执行器。除了在几个机器人任务上表现良好外,PaLM-E还在OK-VQA基准测试上胜过了其他模型。
PaLM-E通过将多模态传感器数据包括在大型语言模型(LLM)的输入中,解决了对大型语言模型进行rounding或体现的问题。这些输入首先经过编码器处理,将它们投影到LLM用于语言输入标记的嵌入空间中,从而得到由文本和其他数据组成的多模态句子。然后,PaLM-E生成文本输出,例如对输入问题的回答或机器人的高层指示。根据谷歌的说法:
"PaLM-E推动了一般性能模型的训练界限,可以同时处理视觉、语言和机器人技术,并且能够将从视觉和语言领域到机器人领域的知识转移... PaLM-E不仅为构建能够从其他数据源中获益的更强大的机器人提供了一条道路,还可能成为使用多模态学习的其他更广泛应用的关键推动因素,包括统一迄今为止看似分离的任务能力。"
谷歌的机器人研究人员已经将几个先前的LLM系统开源,用于机器人控制。在2022年,InfoQ报道了两个项目,即使用LLM输出高级行动计划的SayCan和使用LLM输出低级机器人控制代码的Code-as-Policies。
PaLM-E基于一个预训练的PaLM语言模型。机器人的传感器数据被注入到一个文本输入中;例如,该模型可以处理诸如“What happened between and ?”(“在和之间发生了什么?”)这样的输入问题,其中“img_1”和“img_2”是由ViT编码的图像,并映射到与文本输入令牌相同的嵌入空间。在这种情况下,模型的输出将是对问题的回答。谷歌为多种输入模态创建了编码器,包括机器人状态向量(例如3D姿态信息)、3D场景表示和机器人环境中物体的实体引用。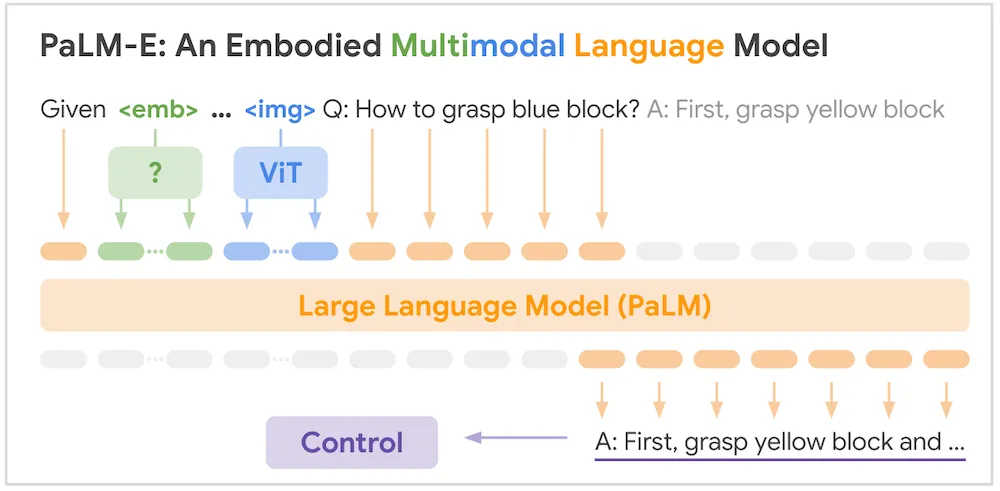
PaLM-E 模型架构。图片来源:https://ai.googleblog.com/2023/03/palm-e-embodied-multimodal-language.html
研究人员通过使用PaLM-E控制模拟和现实世界中的机器人执行多个任务进行了评估:抓取和堆叠物体、在桌面环境中推动物体以及在厨房环境中移动机器人的操作。PaLM-E能够为机器人制定“长期规划”,在桌面推动任务中能够泛化到训练中未见过的任务。在厨房中,该机器人能够“即使在对抗性干扰下”完成长期规划任务。
一些用户在Hacker News的讨论中对这项工作进行了评论。有一个用户想知道模型性能是否随参数数量的增加而扩展。另一个用户回答说:
“性能确实随着参数的增加而提升,尽管这并不是线性关系。正如谷歌在其对Chinchilla LLM的研究中发现的那样,性能也随着训练集的大小增加而提升。他们能够通过工作来确定给定大小的模型的最佳训练量,以充分利用预算。因此,即使我们不发现任何更好的模型架构,尽管我们可能会找到,如果增加模型的规模、训练语料库和预算,我们应该能够获得更出色的模型性能。”
PaLM-E网站上有几个演示视频,展示了由模型控制的机器人执行任务的场景。
来源:https://www.infoq.com/news/2023/06/google-palm-e-robot/?topicPageSponsorship=b2206c17-c7cf-47e8-aee9-0514a0817c31&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng
PaLM-E通过将多模态传感器数据包括在大型语言模型(LLM)的输入中,解决了对大型语言模型进行rounding或体现的问题。这些输入首先经过编码器处理,将它们投影到LLM用于语言输入标记的嵌入空间中,从而得到由文本和其他数据组成的多模态句子。然后,PaLM-E生成文本输出,例如对输入问题的回答或机器人的高层指示。根据谷歌的说法:
"PaLM-E推动了一般性能模型的训练界限,可以同时处理视觉、语言和机器人技术,并且能够将从视觉和语言领域到机器人领域的知识转移... PaLM-E不仅为构建能够从其他数据源中获益的更强大的机器人提供了一条道路,还可能成为使用多模态学习的其他更广泛应用的关键推动因素,包括统一迄今为止看似分离的任务能力。"
谷歌的机器人研究人员已经将几个先前的LLM系统开源,用于机器人控制。在2022年,InfoQ报道了两个项目,即使用LLM输出高级行动计划的SayCan和使用LLM输出低级机器人控制代码的Code-as-Policies。
PaLM-E基于一个预训练的PaLM语言模型。机器人的传感器数据被注入到一个文本输入中;例如,该模型可以处理诸如“What happened between
PaLM-E 模型架构。图片来源:https://ai.googleblog.com/2023/03/palm-e-embodied-multimodal-language.html
研究人员通过使用PaLM-E控制模拟和现实世界中的机器人执行多个任务进行了评估:抓取和堆叠物体、在桌面环境中推动物体以及在厨房环境中移动机器人的操作。PaLM-E能够为机器人制定“长期规划”,在桌面推动任务中能够泛化到训练中未见过的任务。在厨房中,该机器人能够“即使在对抗性干扰下”完成长期规划任务。
一些用户在Hacker News的讨论中对这项工作进行了评论。有一个用户想知道模型性能是否随参数数量的增加而扩展。另一个用户回答说:
“性能确实随着参数的增加而提升,尽管这并不是线性关系。正如谷歌在其对Chinchilla LLM的研究中发现的那样,性能也随着训练集的大小增加而提升。他们能够通过工作来确定给定大小的模型的最佳训练量,以充分利用预算。因此,即使我们不发现任何更好的模型架构,尽管我们可能会找到,如果增加模型的规模、训练语料库和预算,我们应该能够获得更出色的模型性能。”
PaLM-E网站上有几个演示视频,展示了由模型控制的机器人执行任务的场景。
来源:https://www.infoq.com/news/2023/06/google-palm-e-robot/?topicPageSponsorship=b2206c17-c7cf-47e8-aee9-0514a0817c31&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消