











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






情感识别精准度提升:利用多个数据集训练模型
2023年06月28日 由 Alex 发表
170433
0
介绍
本文带你进入构建情感识别模型的旅程,使用著名的VGG模型和全面的FER数据集。我们深入探讨情感识别的基本原理,探索VGG背后的原理,并深入FER数据集。然后,我们将涵盖所有项目组成部分和流程,从数据准备、模型训练和实验跟踪到模型评估,使你具备构建自己情感识别模型的技能。
项目概述
在这个项目中,我们将利用在ImageNet上预训练的VGG19模型。VGG模型在ImageNet基准测试中取得了强大的性能,表明它们在不同的视觉识别任务中具有很好的泛化能力。它在图像识别方面非常准确,并且具有深层网络和小的3x3卷积滤波器。虽然像ResNet这样的其他模型允许更复杂的网络并且推理速度更快,但VGG模型的泛化能力更好,这在面部识别任务中非常重要。
在深入研究代码之前,让我们花点时间分析一下项目架构。
FER数据集是什么?
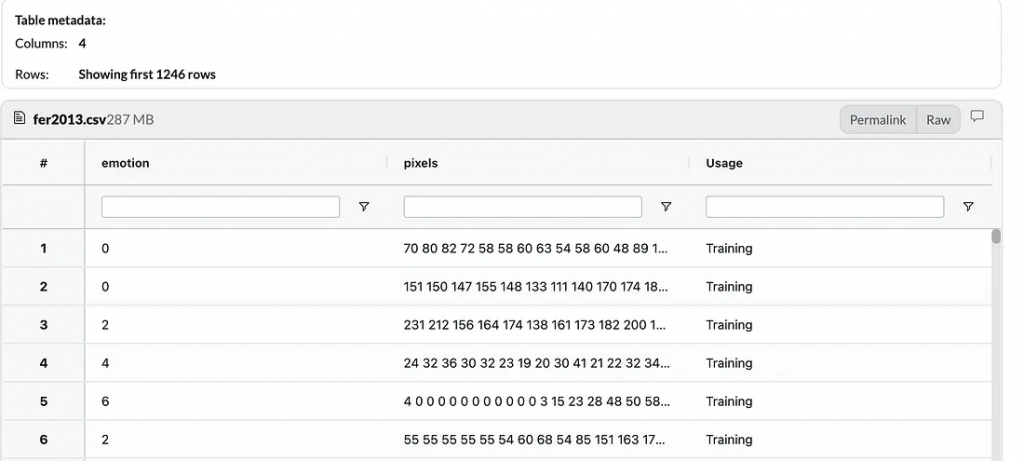
FER(Facial Expression Recognition)是一个于2013年发布的开源数据集。该数据集在一篇名为“Challenges in Representation Learning: A Report on Three Machine Learning Contests”的论文中由Pierre-Luc Carrier和Aaron Courville介绍。它包含了尺寸为48x48像素的剪裁人脸图像,以一个2304个像素的平坦数组表示。

每张图像都有一个代表性的情感标签进行标注,使用以下映射:{0:'愤怒',1:'厌恶',2:'恐惧',3:'快乐',4:'悲伤',5:'惊讶',6:'中性'}
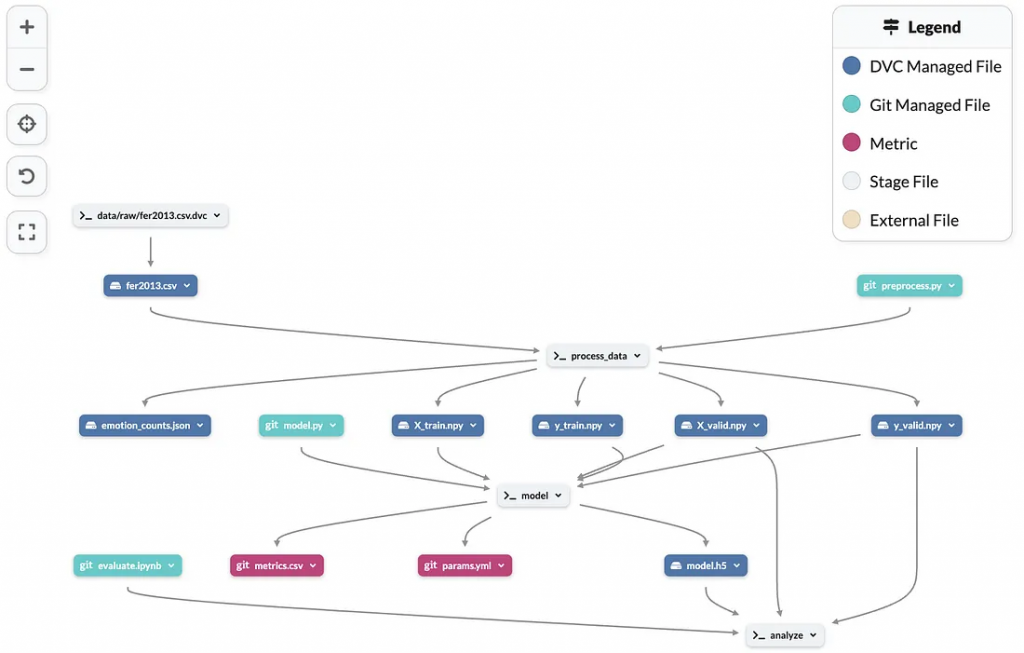
数据处理过程概述
本项目管道由DVC管理,分为三个阶段:
数据处理
预处理脚本涵盖了为训练准备数据的所有必要步骤。它有五个主要步骤:
首先,将数据重塑为48x48的numpy的2D数组,以使其与VGG模型兼容。然后,迭代地将数组从灰度转换为RGB。通过将灰度图像转换为RGB,我们使其与预训练的VGG模型兼容,并有效地在所有三个通道上复制灰度强度值,使模型能够在训练过程中从基于颜色的特征中获益。然后,使用以下代码对相应的标签进行编码:
最后,使用分层分割将数据分为训练集和验证集。
模型开发
现在,我们有了训练集和验证集的数据,可以开始构建模型、训练并运行实验以提高性能。下面的图片显示了一个标准的VGG19模型以及重组了模型最后一个块之后的模型。
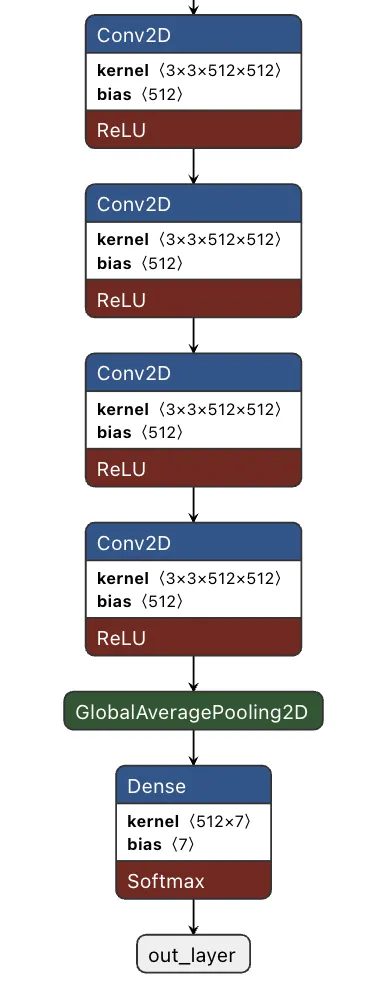
为了在训练之前保留模型在新数据集上的权重,我们将最后一个卷积块用FER数据集的输出层替换,用GlobalAveragePooling2D替换MaxPooling2D,并添加最后一个密集层用于模型的输出。
使用GlobalAveragePooling2D层可以通过计算每个特征图的平均值来减少计算时间,这迫使网络学习与任务相关的全局特征,从而得到一个具有更少数值的一维向量。虽然这是模型的一般架构,但还不适合部署。
数据增强
关于数据增强,我在先前的阶段存储了数据集中各类别标签的计数。正如你所看到的,这是一个不平衡的数据集;与厌恶和惊讶相比,快乐、中性和悲伤的数据点要多得多。
我们处理不平衡数据集的方法有两种。第一种方法是使用ImageDataGenerator生成更多的数据。这在深度学习任务中常用于通过随机旋转、平移、剪切、缩放、翻转和其他图像修改器生成更多的训练样本。应用这种技术将帮助模型更好地泛化,并改善测试集上的准确性,因为该模型对特定标签具有偏向性。下面是实现的方式。将数据生成器拟合到训练集并在模型训练过程中使用它。
处理不平衡数据集的第二种方法是在模型训练过程中传入类别权重。生成的权重可用于在训练过程中平衡损失函数。类别权重会自动根据输入数据的频率进行调整,计算公式为:n_samples / (n_classes * np.bincount(y))
在训练过程中,将class_weights_dict与train_datagen一起传入,以生成随机的数据批次并平衡损失函数。
回调函数(callbacks),即早停和学习率调度器,在训练过程中通过减小学习率(如果损失在几个epochs中没有降低)或完全停止训练来处理过拟合问题。
patience参数表示连续性能下降的epochs数量,该回调函数将应用于训练过程。
我们可以比较两个参数相匹配的实验。模型之间唯一的变化是在训练过程中纳入了类权重。正如你所看到的,添加了这个功能后,模型的性能稍微好一些。train_loss显著降低,验证精度也略有提高。
超参数搜索
调整模型的下一步是找到最佳的超参数组合。一种方法是使用Keras调参器。Keras调参器是一个内置的模块,通过搜索提供的一组特定的超参数来应用于Keras模型。
我创建了两个不同的实验。第一个实验专注于测试不同的优化器、学习率、批量大小和epochs的组合。我们将使用tune_model.ipynb运行这些实验。
超参数以hp对象的形式传递。它们被赋予最小值、最大值和步长,以提供可测试的值的范围。在搜索的第一次迭代中,我们想要测试不同的批量大小、epochs和学习率的组合。
hp对象被传递到构建模型函数中,每次试验时都会测试不同的值组合。试验的数量由max trials设置。根据超参数的数量、步长和整体范围,可能需要增加或减少试验的数量,以便调参器能够有效搜索这些参数的足够组合。目标是最大化验证准确性,如下所示。
MLFlow回调函数
还没有讨论的一个回调函数是mlflow_callback。该回调函数在每个epoch结束时跟踪模型准确度的变化,并将其记录为一个实验中的指标。为了将其纳入Keras调参器中,我创建了一个MLflow类,在每次试验的每个epoch结束时跟踪验证准确度的变化。
在开始Keras调参器的搜索时,mlflow回调函数设置了跟踪uri。你需要配置你自己的mlflow凭据。你必须在设置跟踪uri之前,在项目shell中将跟踪用户名和密码导出为环境变量,如下所示。
当完成试验时,将记录的度量指标和超参数存储在DagsHub仓库的实验选项卡中。还生成了一个图,显示了每个epoch中准确性的变化。
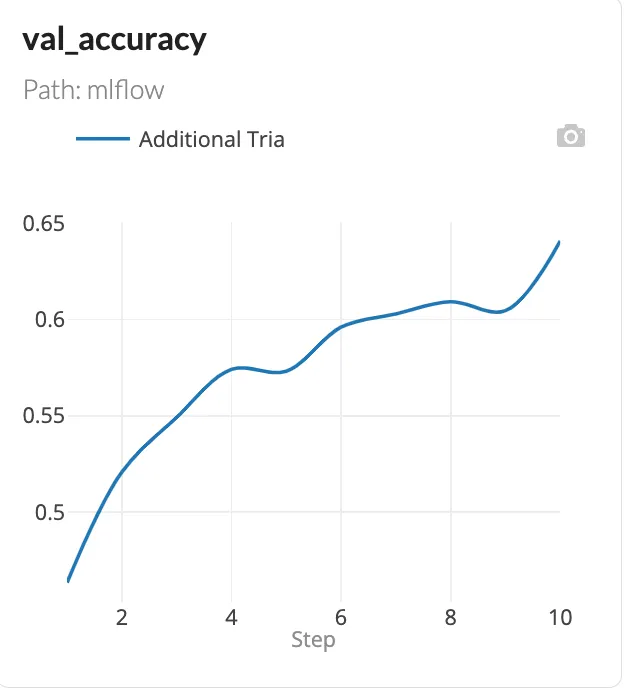
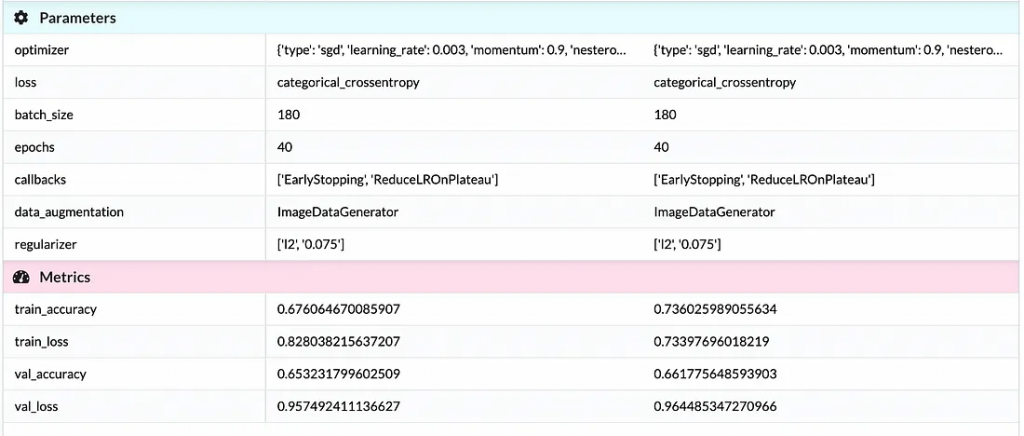
我发现SGD优化器与较低的学习率、较大的批量大小和30到40个epoch范围相结合效果最好。以下是为这组参数找到的最佳结果的实验。
之所以添加额外的层和应用正则化是为了验证更高的学习率和epoch数量是否有效。这样做的缺点是它可能会导致过拟合,在一些实验中确实发生了过拟合。然而,增加额外的密集层以及L2正则化可以缓解过拟合问题。
这个模型似乎对额外的层没有很好的响应,并且在训练过程中准确性趋于平稳。
实验跟踪
一旦找到一组表现良好的参数,就不再需要使用Keras调参器。我们可以再次训练模型,并使用MLflow记录参数。设置tracking uri并开始run之后,我们将像之前一样构建和训练模型。现在,我们可以定义所有参数并在运行结束时记录结果。
模型评估
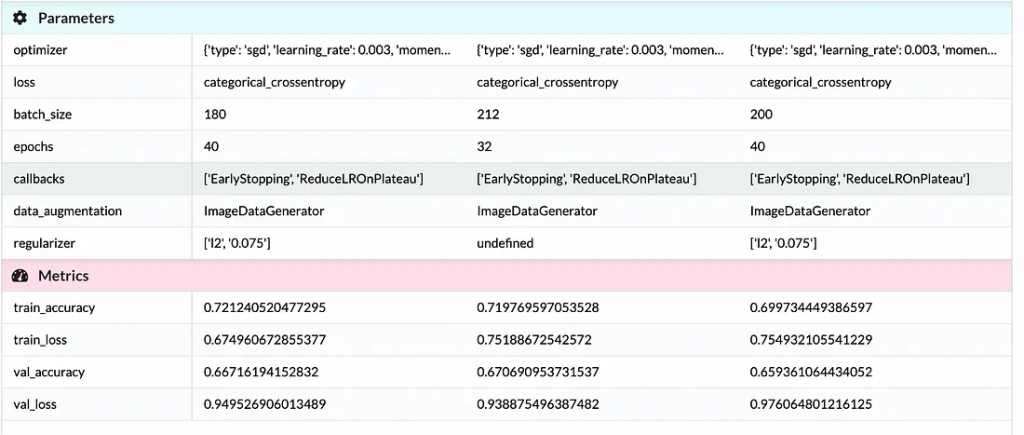
经过多次实验后,我比较了准确率最高的前三个模型。我想选择一个最大化验证准确率并最小化损失的模型。我还比较了训练准确率和损失,以确保模型没有过拟合得太严重。第二个模型的表现最好。我将这个模型保存在我的仓库中。
模型流程的最后一步是评估模型的性能。我们利用papermill在单独的评估脚本中执行评估notebook,以便DVC流水线能够处理它。
让我们来看看模型在验证数据集上的表现。
总结
考虑到我们使用的是一个不平衡的数据集,由于测试样本的缺失,模型在准确预测厌恶、恐惧和悲伤标签方面困难较大。在许多多类别分类器中,特定类别标签的缺乏训练样本是一个主要问题。此外,即使添加了回调函数和正则化,模型仍然出现了过拟合。这可能是因为我们使用VGG模型中的每个可训练参数来调整数据集,而不是冻结一些层。由于模型的复杂性和参数数量,它可能难以泛化到新数据。
在不同的数据集上训练这个模型可能会有用,以提高它对新数据的泛化能力,减少对某些类标签的偏差,并提高模型的整体性能。
我们可以通过将不同的数据集托管在自己的仓库中,并利用DagsHub客户端从多个数据集中高效地流式传输数据和训练模型,使用一种称为迁移学习的概念。
来源:https://medium.com/mlearning-ai/train-an-emotion-recognition-model-using-multiple-datasets-part-1-f0d8fd49d41f
本文带你进入构建情感识别模型的旅程,使用著名的VGG模型和全面的FER数据集。我们深入探讨情感识别的基本原理,探索VGG背后的原理,并深入FER数据集。然后,我们将涵盖所有项目组成部分和流程,从数据准备、模型训练和实验跟踪到模型评估,使你具备构建自己情感识别模型的技能。
项目概述
在这个项目中,我们将利用在ImageNet上预训练的VGG19模型。VGG模型在ImageNet基准测试中取得了强大的性能,表明它们在不同的视觉识别任务中具有很好的泛化能力。它在图像识别方面非常准确,并且具有深层网络和小的3x3卷积滤波器。虽然像ResNet这样的其他模型允许更复杂的网络并且推理速度更快,但VGG模型的泛化能力更好,这在面部识别任务中非常重要。
在深入研究代码之前,让我们花点时间分析一下项目架构。
FER数据集是什么?
FER(Facial Expression Recognition)是一个于2013年发布的开源数据集。该数据集在一篇名为“Challenges in Representation Learning: A Report on Three Machine Learning Contests”的论文中由Pierre-Luc Carrier和Aaron Courville介绍。它包含了尺寸为48x48像素的剪裁人脸图像,以一个2304个像素的平坦数组表示。
每张图像都有一个代表性的情感标签进行标注,使用以下映射:{0:'愤怒',1:'厌恶',2:'恐惧',3:'快乐',4:'悲伤',5:'惊讶',6:'中性'}
数据处理过程概述
本项目管道由DVC管理,分为三个阶段:
1. 数据处理:提取图像特征,编码标签,分割数据集进行训练、测试,并保存到文件中。
2. 模型:利用训练数据训练模型并调优超参数。
3. 分析:使用验证数据评估模型的性能。
数据处理
预处理脚本涵盖了为训练准备数据的所有必要步骤。它有五个主要步骤:
1. 将字符串像素转换为(48,48,3)图像数组。
2. 对标签进行编码
3. 使用分层分割将数据分成训练和验证
4. 将训练/验证保存为numpy数据文件
5. 将数据文件推送到我们的远程DagsHub存储库
首先,将数据重塑为48x48的numpy的2D数组,以使其与VGG模型兼容。然后,迭代地将数组从灰度转换为RGB。通过将灰度图像转换为RGB,我们使其与预训练的VGG模型兼容,并有效地在所有三个通道上复制灰度强度值,使模型能够在训练过程中从基于颜色的特征中获益。然后,使用以下代码对相应的标签进行编码:
from keras.utils import to_categorical
labels = df['emotion'].values
encoded_labels = to_categorical(labels, num_classes=7)
最后,使用分层分割将数据分为训练集和验证集。
模型开发
现在,我们有了训练集和验证集的数据,可以开始构建模型、训练并运行实验以提高性能。下面的图片显示了一个标准的VGG19模型以及重组了模型最后一个块之后的模型。
为了在训练之前保留模型在新数据集上的权重,我们将最后一个卷积块用FER数据集的输出层替换,用GlobalAveragePooling2D替换MaxPooling2D,并添加最后一个密集层用于模型的输出。
base_model = tf.keras.applications.VGG19(weights='imagenet', include_top=False, input_shape=(48, 48, 3))
# Add dense layers
x = base_model.layers[-2].output
x = GlobalAveragePooling2D()(x)
# Add final classification layer
output_layer = Dense(num_classes, activation='softmax')(x)
# Create model
model = Model(inputs=base_model.input, outputs=output_layer)
使用GlobalAveragePooling2D层可以通过计算每个特征图的平均值来减少计算时间,这迫使网络学习与任务相关的全局特征,从而得到一个具有更少数值的一维向量。虽然这是模型的一般架构,但还不适合部署。
数据增强
关于数据增强,我在先前的阶段存储了数据集中各类别标签的计数。正如你所看到的,这是一个不平衡的数据集;与厌恶和惊讶相比,快乐、中性和悲伤的数据点要多得多。
{"3": 8989, "6": 6198, "4": 6077, "2": 5121, "0": 4953, "5": 4002, "1": 547}emotion labels → {0:'anger', 1:'disgust', 2:'fear', 3:'happiness', 4: 'sadness', 5: 'surprise', 6: 'neutral'}我们处理不平衡数据集的方法有两种。第一种方法是使用ImageDataGenerator生成更多的数据。这在深度学习任务中常用于通过随机旋转、平移、剪切、缩放、翻转和其他图像修改器生成更多的训练样本。应用这种技术将帮助模型更好地泛化,并改善测试集上的准确性,因为该模型对特定标签具有偏向性。下面是实现的方式。将数据生成器拟合到训练集并在模型训练过程中使用它。
train_datagen = ImageDataGenerator(rotation_range=20,
width_shift_range=0.20,
height_shift_range=0.20,
shear_range=0.15,
zoom_range=0.15,py
horizontal_flip=True,
fill_mode='nearest')
train_datagen.fit(X_train)
处理不平衡数据集的第二种方法是在模型训练过程中传入类别权重。生成的权重可用于在训练过程中平衡损失函数。类别权重会自动根据输入数据的频率进行调整,计算公式为:n_samples / (n_classes * np.bincount(y))
class_weights = compute_class_weight(
class_weight = "balanced",
classes = np.unique(y_train.argmax(axis=1)),
y = y_train.argmax(axis=1)
)
class_weights_dict = dict(enumerate(class_weights))
## Now train the model
history = model.fit(train_datagen.flow(X_train,
y_train,
batch_size = batch_size),
validation_data = (X_valid, y_valid),
steps_per_epoch = steps_per_epoch,
epochs = epochs,
callbacks = callbacks,
use_multiprocessing = True,
class_weight=class_weights_dict)
在训练过程中,将class_weights_dict与train_datagen一起传入,以生成随机的数据批次并平衡损失函数。
回调函数(callbacks),即早停和学习率调度器,在训练过程中通过减小学习率(如果损失在几个epochs中没有降低)或完全停止训练来处理过拟合问题。
lr_scheduler = ReduceLROnPlateau(monitor = 'val_accuracy',
factor = 0.25,
patience = 8,
min_lr = 1e-6,
verbose = 1)
early_stopping = EarlyStopping(monitor = 'val_accuracy',
min_delta = 0.00005,
patience = 12,
verbose = 1,
restore_best_weights = True)
patience参数表示连续性能下降的epochs数量,该回调函数将应用于训练过程。
我们可以比较两个参数相匹配的实验。模型之间唯一的变化是在训练过程中纳入了类权重。正如你所看到的,添加了这个功能后,模型的性能稍微好一些。train_loss显著降低,验证精度也略有提高。
超参数搜索
调整模型的下一步是找到最佳的超参数组合。一种方法是使用Keras调参器。Keras调参器是一个内置的模块,通过搜索提供的一组特定的超参数来应用于Keras模型。
我创建了两个不同的实验。第一个实验专注于测试不同的优化器、学习率、批量大小和epochs的组合。我们将使用tune_model.ipynb运行这些实验。
超参数以hp对象的形式传递。它们被赋予最小值、最大值和步长,以提供可测试的值的范围。在搜索的第一次迭代中,我们想要测试不同的批量大小、epochs和学习率的组合。
from kerastuner.engine.hyperparameters import HyperParameters
from kerastuner.tuners import RandomSearch
hp = HyperParameters()
batch_size = hp.Int('batch_size', min_value=16, max_value=256, step=16)
epochs = hp.Int('epochs', min_value=10, max_value=50, step=10)
hp对象被传递到构建模型函数中,每次试验时都会测试不同的值组合。试验的数量由max trials设置。根据超参数的数量、步长和整体范围,可能需要增加或减少试验的数量,以便调参器能够有效搜索这些参数的足够组合。目标是最大化验证准确性,如下所示。
tuner = RandomSearch(build_model, objective='val_accuracy',max_trials=10,hyperparameters=hp)
tuner.search(train_datagen.flow(X_train, y_train, batch_size=batch_size),validation_data=(X_valid, y_valid),epochs=epochs,callbacks=[early_stopping, lr_scheduler, mlflow_callback],use_multiprocessing=True)
MLFlow回调函数
还没有讨论的一个回调函数是mlflow_callback。该回调函数在每个epoch结束时跟踪模型准确度的变化,并将其记录为一个实验中的指标。为了将其纳入Keras调参器中,我创建了一个MLflow类,在每次试验的每个epoch结束时跟踪验证准确度的变化。
class MlflowCallback(Callback):
def __init__(self, run_name):
self.run_name = run_name
def on_train_begin(self, logs=None):
mlflow.set_tracking_uri("地址")
mlflow.start_run(run_name=self.run_name)
def on_trial_end(self, trial, logs={}):
hp = trial.hyperparameters.values
for key, value in hp.items():
mlflow.log_param(key, value)
mlflow.log_param('epochs', 32)
mlflow.log_param('batch_size', 212)
mlflow.log_param('learning_rate', 0.003)
mlflow.log_metric("val_accuracy", logs["val_accuracy"])
mlflow.log_metric("train_accuracy", logs["train_accuracy"])
mlflow.log_metric("val_loss", logs["val_loss"])
mlflow.log_metric("train_loss", logs["val_loss"])
def on_train_end(self, logs=None):
mlflow.end_run()
mlflow_callback = MlflowCallback('layers add')
在开始Keras调参器的搜索时,mlflow回调函数设置了跟踪uri。你需要配置你自己的mlflow凭据。你必须在设置跟踪uri之前,在项目shell中将跟踪用户名和密码导出为环境变量,如下所示。
export MLFLOW_TRACKING_USERNAME=
export MLFLOW_TRACKING_PASSWORD=
当完成试验时,将记录的度量指标和超参数存储在DagsHub仓库的实验选项卡中。还生成了一个图,显示了每个epoch中准确性的变化。
我发现SGD优化器与较低的学习率、较大的批量大小和30到40个epoch范围相结合效果最好。以下是为这组参数找到的最佳结果的实验。
# Define the hyperparameter search space
# Now I want to test if adding additional layers and adding regularization will help improve overfitting or improve accuracy
hp = HyperParameters()
num_dense_layers = hp.Int('num_dense_layers', min_value=1, max_value=3)
num_units = hp.Int('num_units', min_value=64, max_value=512, step=32)
reg_strength = hp.Float('reg_strength', min_value=0.001, max_value= 0.1, step=0.004)
tuner.search(train_datagen.flow(X_train, y_train, batch_size=212),
validation_data=(X_valid, y_valid),
epochs = 32,
steps_per_epoch = len(X_train) / 212,
callbacks=[early_stopping, lr_scheduler, mlflow_callback],
use_multiprocessing=True)
best_hp = tuner.get_best_hyperparameters()[0]
mlflow.log(best_hp.values)
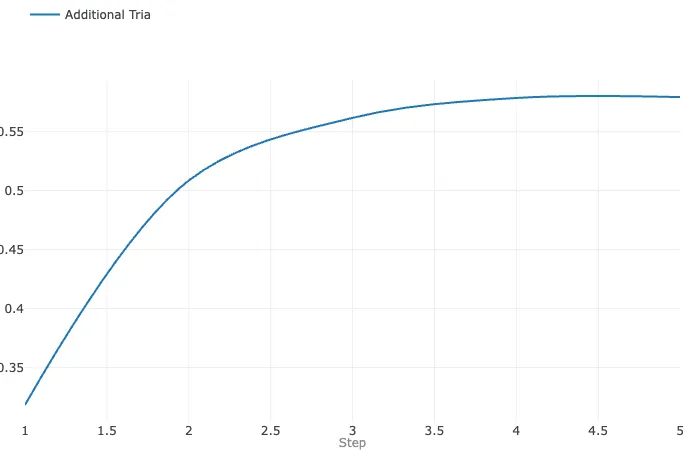
之所以添加额外的层和应用正则化是为了验证更高的学习率和epoch数量是否有效。这样做的缺点是它可能会导致过拟合,在一些实验中确实发生了过拟合。然而,增加额外的密集层以及L2正则化可以缓解过拟合问题。
这个模型似乎对额外的层没有很好的响应,并且在训练过程中准确性趋于平稳。
实验跟踪
一旦找到一组表现良好的参数,就不再需要使用Keras调参器。我们可以再次训练模型,并使用MLflow记录参数。设置tracking uri并开始run之后,我们将像之前一样构建和训练模型。现在,我们可以定义所有参数并在运行结束时记录结果。
mlflow.set_tracking_uri("地址")
with mlflow.start_run():
# batch size of 32 performs the best.
model = build_model(num_classes)
history = train(model, X_train, y_train, X_valid, y_valid)
metrics = {"train_accuracy": history.history['accuracy'][-1], "val_accuracy": history.history['val_accuracy'][-1],
"train_loss": history.history['loss'][-1], "val_loss": history.history['val_loss'][-1]}
params = {"optimizer": {'type': 'sgd', 'learning_rate': 0.0092, 'momentum': 0.90, 'nesterov': True}, "loss": 'categorical_crossentropy', 'batch_size': 96,
'epochs': 24, 'callbacks': ['EarlyStopping', 'ReduceLROnPlateau'], 'data_augmentation': 'ImageDataGenerator'}
mlflow.log_metrics(metrics)
mlflow.log_params(params)模型评估
经过多次实验后,我比较了准确率最高的前三个模型。我想选择一个最大化验证准确率并最小化损失的模型。我还比较了训练准确率和损失,以确保模型没有过拟合得太严重。第二个模型的表现最好。我将这个模型保存在我的仓库中。
模型流程的最后一步是评估模型的性能。我们利用papermill在单独的评估脚本中执行评估notebook,以便DVC流水线能够处理它。
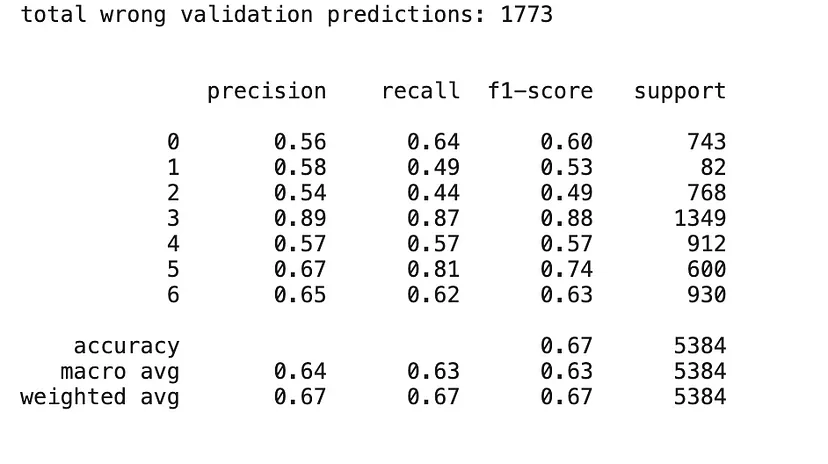
让我们来看看模型在验证数据集上的表现。
总结
考虑到我们使用的是一个不平衡的数据集,由于测试样本的缺失,模型在准确预测厌恶、恐惧和悲伤标签方面困难较大。在许多多类别分类器中,特定类别标签的缺乏训练样本是一个主要问题。此外,即使添加了回调函数和正则化,模型仍然出现了过拟合。这可能是因为我们使用VGG模型中的每个可训练参数来调整数据集,而不是冻结一些层。由于模型的复杂性和参数数量,它可能难以泛化到新数据。
在不同的数据集上训练这个模型可能会有用,以提高它对新数据的泛化能力,减少对某些类标签的偏差,并提高模型的整体性能。
我们可以通过将不同的数据集托管在自己的仓库中,并利用DagsHub客户端从多个数据集中高效地流式传输数据和训练模型,使用一种称为迁移学习的概念。
来源:https://medium.com/mlearning-ai/train-an-emotion-recognition-model-using-multiple-datasets-part-1-f0d8fd49d41f

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消