











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自动检查人工智能生成的代码,完美助力代码质量提升
2023年07月05日 由 Alex 发表
620833
0
你喜欢ChatGPT和GitHub Copilot这样的人工智能编码工具吗?你能信任他们编写的代码吗?
在某些(目前,有限的)情况下,你可以信任他们的代码!使用正式的验证工具,如Kani for Rust,我们有时可以自动证明ai生成的代码的正确性。我的crate RangeSetBlaze现在包含了一些这样的代码。
Rust已经为内存管理提供了数学上的确定性。在本文中,你还将学习如何使用kani将这种确定性扩展到计算机算术和溢出的主题。你会发现kani对于人类和人工智能生成的代码都很有用。
为了了解自动生成代码的自动验证的前景和局限性,我对RangeSetBlaze的部分应用了ChatGPT和Kani。RangeSetBlaze是一个Rust crate,用于有效地操作“块状”整数集。具体来说,我研究了使用这些属性的三个编程问题:
令人兴奋的是,当我对问题2的ChatGPT/Kani解决方案进行基准测试时,我发现它比我的原始代码快3%。RangeSetBlaze现在包含这个计算机生成和验证的代码。
让我们逐一分析这三个编程问题。
在RangeSetBlaze crate中,我经常需要找到包含范围的长度,例如3..=10。注意,如果类型是i8(8位带符号整数),则长度可以是0到256之间的任何值。这257个不同的长度值不能用8位表示,因此长度必须是u16或usize(在64位计算机上)之类的值。
那么,我们应该如何计算包含范围的长度呢?我们试试下面的代码:
下面是我们要求kani验证单代码正确性的方法:
这就要求kani用数学方法证明以下逻辑命题:
如果:
那么:len as i128将等于正确答案。
kani回应说无法提供证据。它报告了两个问题:
与简单的代码相比,RangeSetBlaze实际的包含范围长度代码使用了overflowing_sub和两个强制类型转换:
这是正确的吗?是的。当我们问kani时,它会说:“成功!”。
当然,对于i8,我们可以测试所有可能的值组合。然而,kani也适用于更大的类型。例如,i32有4,294,967,296个可能的值,i64有18,446,744,073,709,551,616个可能的值。kani用完美的数学验证了RangeSetBlaze的代码。例如,对于i32,我们写:
并回复“成功!”
现在我们可以检查一些代码的正确性,我们可以使用ChatGPT或GitHub Copilot来创建代码吗?我问GitHub Copilot:
它回复了简单的解决方案(重新格式化为Medium):
正如我们之前看到的,Kani发现这段代码在下溢和上溢时出现错误。我向GitHub Copilot寻求一个不会导致溢出的解决方案。
它暗示了这一点,这并不总是给出答案:
切换到ChatGPT 3.5,我问:
它建议:
当我让kani正式测试时,它报告说:
尝试使用ChatGPT 4会产生类似的不正确或不完整的答案。
在RangeSetBlaze代码的一个地方,它必须检查a+1
它报告这段代码是不正确的,具体如下:
下面是RangeSetBlaze的原始代码:
kani证实这是正确的。
现在的问题是,如果ChatGPT可以找到这个或类似的东西。
使用ChatGPT生成
我问ChatGPT 4(5月24日版本)这个问题:
在Rust中,a和b是i32。如何检验a+1 < b 不溢出?
它用这个表达式来回答:
当我和kani一起测试时,它证实了这个答案是正确的。这让我非常兴奋。这是我的第一个自动生成和自动验证的代码。
基准测试
为了看看ChatGPT的代码是否值得使用,让我们使用Rust的Criterion包进行微基准测试。每次运行将随机且均匀地从i32的整个范围内生成a和b这两个输入。以下是基准测试结果:
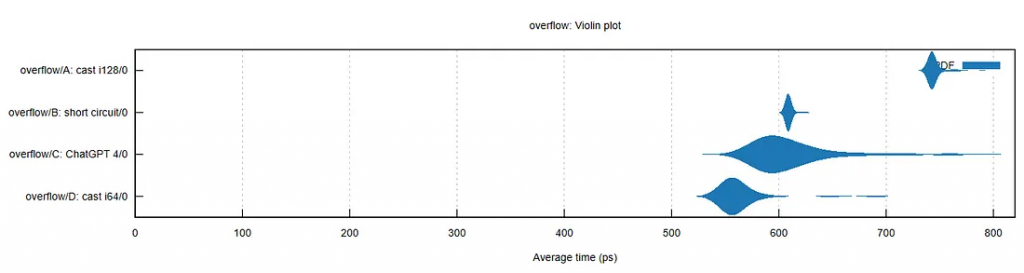
结果显示:
A:强制转换i128 -“明显正确但缓慢”的解决方案,只是将所有内容强制转换为i128。基准测试显示这是最慢的,但这里的慢是相对的。它的运行时间仍然不到一纳秒。
B:short circuit——我最初的解决方案是使用Rust的&&运算符。它比cast i128快18%。
C:ChatGPT 4 -使用checked_add和match。它比i128快20%,比short circuit快3%。
D:cast i64 -在创建这个基准测试时,我得到了以下解决方案的想法(回想起来很明显):let condition = (a as i64) + 1<=(b as i64);它比cast i128快27%,比ChatGPT 4快8%。
为什么short circuit比ChatGPT 4慢?我们可以使用Rust Playground来查看汇编代码(我已经添加了注释):
我们看到两个版本的代码都是无分支的,并且避免了任何溢出错误。然而,short circuit代码进行了两次比较,而ChatGPT 4代码只进行了一次比较。
问题2的讨论
从某种意义上说,这些解决方案都无关紧要——加快RangeSetBlaze中的这一行代码不会对其整体速度产生明显影响。最后,我决定使用ChatGPT 4代码——它要快一点。此外,拥有ai生成和自动验证的代码也很有趣。我不喜欢强制转换i64代码,因为RangeSetBlaze需要适用于所有大小的整数的通用代码,而不仅仅是i32。我不认为使i64类型转换解决方案泛型是值得添加代码的。
为了理解自动验证自动生成的代码的当前限制,接下来......。
问题1和问题2只需要一行代码。ChatGPT和Kani如何解决一个更有趣的问题?想到的问题是如何有效地将一个范围插入到一个排序的、不相交的范围列表中。例如,
以下是我给ChatGPT 4的问题的非正式说明:
对此,ChatGPT建议:
这看起来令人印象深刻,但这是正确的吗?我看到了一个下溢问题(end_value >= start - 1)。此外,当我将这段代码放入RangeSetBlaze并应用现有测试时,许多测试会超时。这段代码似乎导致了一个无限循环。
kani可以检查这段代码或者找到反例吗?很遗憾,没有。
所以,这个有趣的问题对ChatGPT和Kani来说似乎都太难了。
这就是实现自动验证自动生成代码的一小步。
我发现kani验证工具很容易使用。此外,kani在验证与计算机算术相关的一行代码方面做得很好。但是,涉及一般循环的代码超出了它目前的能力。
ChatGPT在单行计算机算术问题上产生了不同的结果,有一个是错的,一个是对的。显然,它在需要循环的更大问题上也失败了。
这两个工具一起工作解决了一个问题,生成的答案比我手工编写的要快一点点。他们的解决方案现在是RangeSetBlaze的一部分。
在未来,我希望看到像Lean和Coq这样的助手的进步。这些系统(不一定)会自动证明数学定理或程序的正确性。相反,它们会自动验证给定证明的正确性。与kani相比,这些系统似乎很难使用,但可以潜在地验证更复杂的代码。这方面的进步将允许程序员(包括人类和人工智能)用程序正确的理由来增强程序。我相信这将使自动验证自动生成的代码变得更加容易。
来源:https://medium.com/@carlmkadie/check-ai-generated-code-perfectly-and-automatically-d5b61acff741
在某些(目前,有限的)情况下,你可以信任他们的代码!使用正式的验证工具,如Kani for Rust,我们有时可以自动证明ai生成的代码的正确性。我的crate RangeSetBlaze现在包含了一些这样的代码。
Rust已经为内存管理提供了数学上的确定性。在本文中,你还将学习如何使用kani将这种确定性扩展到计算机算术和溢出的主题。你会发现kani对于人类和人工智能生成的代码都很有用。
为了了解自动生成代码的自动验证的前景和局限性,我对RangeSetBlaze的部分应用了ChatGPT和Kani。RangeSetBlaze是一个Rust crate,用于有效地操作“块状”整数集。具体来说,我研究了使用这些属性的三个编程问题:
问题1:一个对Kani可验证但对ChatGPT太难的单行问题。
问题2:一个ChatGPT可解决且Kani可验证的单行问题。
问题3:一个对Kani和ChatGPT都太难的单行问题。
令人兴奋的是,当我对问题2的ChatGPT/Kani解决方案进行基准测试时,我发现它比我的原始代码快3%。RangeSetBlaze现在包含这个计算机生成和验证的代码。
让我们逐一分析这三个编程问题。
问题1:一个对Kani可验证但对ChatGPT太难的单行问题
在RangeSetBlaze crate中,我经常需要找到包含范围的长度,例如3..=10。注意,如果类型是i8(8位带符号整数),则长度可以是0到256之间的任何值。这257个不同的长度值不能用8位表示,因此长度必须是u16或usize(在64位计算机上)之类的值。
那么,我们应该如何计算包含范围的长度呢?我们试试下面的代码:
let len = end - start + 1;
下面是我们要求kani验证单代码正确性的方法:
#[cfg(kani)]
#[kani::proof]
fn verify_len_i8() {
let start: i8 = kani::any();
let end: i8 = kani::any(); // end is inclusive
kani::assume(start <= end);
let len = end - start + 1;
assert!((len as i128) == ((end as i128) - (start as i128) + 1));
}
这就要求kani用数学方法证明以下逻辑命题:
如果:
1. Start是任意值的i8,并且
2. End至少与start一样大,并且
3. len(根据Rust的类型规则是i8)如上所述计算,并且
4. ((end as i 128)-(start as i128)+ 1)是正确答案
那么:len as i128将等于正确答案。
kani回应说无法提供证据。它报告了两个问题:
1. “尝试用溢出进行减法”-反例:start = -118和end = 35。
2. "尝试添加溢出" -反例:start = -7 和 end = 120。
与简单的代码相比,RangeSetBlaze实际的包含范围长度代码使用了overflowing_sub和两个强制类型转换:
let len = end.overflowing_sub(start).0 as u8 as usize + 1;
这是正确的吗?是的。当我们问kani时,它会说:“成功!”。
当然,对于i8,我们可以测试所有可能的值组合。然而,kani也适用于更大的类型。例如,i32有4,294,967,296个可能的值,i64有18,446,744,073,709,551,616个可能的值。kani用完美的数学验证了RangeSetBlaze的代码。例如,对于i32,我们写:
#[cfg(kani)]
#[kani::proof]
fn verify_len_i32_other_sub() {
let start: i32 = kani::any();
let end: i32 = kani::any(); // end is inclusive
kani::assume(start <= end);
let len = end.overflowing_sub(start).0 as u32 as usize + 1;
assert!((len as i128) == ((end as i128) - (start as i128) + 1));
}
并回复“成功!”
使用chatGPT生成
现在我们可以检查一些代码的正确性,我们可以使用ChatGPT或GitHub Copilot来创建代码吗?我问GitHub Copilot:
在Rust中,我的范围包括i32。假设start<=end。如何计算值域的长度?
它回复了简单的解决方案(重新格式化为Medium):
// You can compute the length of the range by subtracting the
// start from the end and adding 1. Here's an example code snippet:
let start: i32 = 10;
let end: i32 = 20;
let len = end - start + 1;
println!("Length of range: {}", len);
// This will output Length of range: 11 for the given values
// of start and end.
正如我们之前看到的,Kani发现这段代码在下溢和上溢时出现错误。我向GitHub Copilot寻求一个不会导致溢出的解决方案。
在Rust中,我的范围包括i32。假设start<=end。如何计算值域的长度?
它暗示了这一点,这并不总是给出答案:
let start: i32 = 10;
let end: i32 = 20;
let len = end.checked_sub(start).and_then(|diff| diff.checked_add(1));
match len {
Some(len) => println!("Length of range: {}", len),
None => println!("Subtraction overflowed!"),
}
切换到ChatGPT 3.5,我问:
在Rust中,我的范围包括i32。假设start<=end。如何计算值域的长度而不溢出?我想避免它。
它建议:
let length = end.saturating_sub(start).saturating_add(1);
当我让kani正式测试时,它报告说:
"断言失败:(len as i128) == ((end as i128) - (start as i128) + 1) " —反例:start = -2013200384, end = 402653181。
尝试使用ChatGPT 4会产生类似的不正确或不完整的答案。
问题2:一个ChatGPT可解决且Kani可验证的单行问题
在RangeSetBlaze代码的一个地方,它必须检查a+1
#[cfg(kani)]
#[kani::proof]
fn verify_less_than_i32_naive() {
let a: i32 = kani::any();
let b: i32 = kani::any();
let condition = a + 1 < b;
assert!(condition == (a as i128 + 1 < b as i128));
}
它报告这段代码是不正确的,具体如下:
“尝试添加溢出”-反例:a = 2147483647和b = 553648128。
下面是RangeSetBlaze的原始代码:
let condition = a < b && a + 1 < b;
kani证实这是正确的。
现在的问题是,如果ChatGPT可以找到这个或类似的东西。
使用ChatGPT生成
我问ChatGPT 4(5月24日版本)这个问题:
在Rust中,a和b是i32。如何检验a+1 < b 不溢出?
它用这个表达式来回答:
match a.checked_add(1) {
Some(sum) => sum < b,
None => false,
}当我和kani一起测试时,它证实了这个答案是正确的。这让我非常兴奋。这是我的第一个自动生成和自动验证的代码。
基准测试
为了看看ChatGPT的代码是否值得使用,让我们使用Rust的Criterion包进行微基准测试。每次运行将随机且均匀地从i32的整个范围内生成a和b这两个输入。以下是基准测试结果:
结果显示:
A:强制转换i128 -“明显正确但缓慢”的解决方案,只是将所有内容强制转换为i128。基准测试显示这是最慢的,但这里的慢是相对的。它的运行时间仍然不到一纳秒。
B:short circuit——我最初的解决方案是使用Rust的&&运算符。它比cast i128快18%。
C:ChatGPT 4 -使用checked_add和match。它比i128快20%,比short circuit快3%。
D:cast i64 -在创建这个基准测试时,我得到了以下解决方案的想法(回想起来很明显):let condition = (a as i64) + 1<=(b as i64);它比cast i128快27%,比ChatGPT 4快8%。
为什么short circuit比ChatGPT 4慢?我们可以使用Rust Playground来查看汇编代码(我已经添加了注释):
playground::less_than_i32_human:
cmpl %esi, %edi # compare a to b
setl %cl # t1 = a < b
incl %edi # a = a+1
cmpl %esi, %edi # compare a to b
setl %al # t2 = a < b
andb %cl, %al # t3 = t1 & t2
retq # return t3
playground::less_than_i32_gpt4:
incl %edi # a = a+1
setno %cl # t1 = "no overflow"
cmpl %esi, %edi # compare a to b
setl %al # t2 = a < b
andb %cl, %al # t3 = t1 & t2
retq # return t3
我们看到两个版本的代码都是无分支的,并且避免了任何溢出错误。然而,short circuit代码进行了两次比较,而ChatGPT 4代码只进行了一次比较。
问题2的讨论
从某种意义上说,这些解决方案都无关紧要——加快RangeSetBlaze中的这一行代码不会对其整体速度产生明显影响。最后,我决定使用ChatGPT 4代码——它要快一点。此外,拥有ai生成和自动验证的代码也很有趣。我不喜欢强制转换i64代码,因为RangeSetBlaze需要适用于所有大小的整数的通用代码,而不仅仅是i32。我不认为使i64类型转换解决方案泛型是值得添加代码的。
为了理解自动验证自动生成的代码的当前限制,接下来......。
问题3:一个对Kani和ChatGPT都太难的单行问题
问题1和问题2只需要一行代码。ChatGPT和Kani如何解决一个更有趣的问题?想到的问题是如何有效地将一个范围插入到一个排序的、不相交的范围列表中。例如,
1. Inserting 3..=10
2. into 1..=1, 2..=4, 6..=7, 11..=20, 100..=200,
3. should result in 1..=1, 2..=20, 100..=200.
以下是我给ChatGPT 4的问题的非正式说明:
RangeSetBlaze is a Rust crate represents a set of integers. It represents
the set as a sorted, disjoint list of inclusive integer ranges in a BTreeMap.
The start value is the map's key and the (inclusive) end value is the map's
value. Write a function that inserts a new inclusive integer range into the
BTreeMap. The new BTreeMap must represent the union of the original BTreeMap
and the input range. Its ranges must be sorted and disjoint. It should be
O(m * ln n) where m is the number of ranges in the BTreeMap that overlaps
with the input range and n is the number of ranges in the BTreeMap.
对此,ChatGPT建议:
pub fn insert(&mut self, range: RangeInclusive) {
let (start, end) = range.into_inner();
// Find the first overlapping range or the nearest one before it
let mut next = self.map.range(..=start).next_back();
// Find all overlapping ranges
while let Some((&start_key, &end_value)) = next {
// If this range doesn't overlap, we're done
if end_value < start {
break;
}
// If this range overlaps or is adjacent, merge it
if end_value >= start - 1 {
let new_end = end.max(end_value);
let new_start = start.min(start_key);
self.map.remove(&start_key);
self.map.insert(new_start, new_end);
// Restart from the beginning
next = self.map.range(..=new_start).next_back();
} else {
next = self.map.range(..start_key).next_back();
}
}
}
这看起来令人印象深刻,但这是正确的吗?我看到了一个下溢问题(end_value >= start - 1)。此外,当我将这段代码放入RangeSetBlaze并应用现有测试时,许多测试会超时。这段代码似乎导致了一个无限循环。
kani可以检查这段代码或者找到反例吗?很遗憾,没有。
所以,这个有趣的问题对ChatGPT和Kani来说似乎都太难了。
总结
这就是实现自动验证自动生成代码的一小步。
我发现kani验证工具很容易使用。此外,kani在验证与计算机算术相关的一行代码方面做得很好。但是,涉及一般循环的代码超出了它目前的能力。
ChatGPT在单行计算机算术问题上产生了不同的结果,有一个是错的,一个是对的。显然,它在需要循环的更大问题上也失败了。
这两个工具一起工作解决了一个问题,生成的答案比我手工编写的要快一点点。他们的解决方案现在是RangeSetBlaze的一部分。
在未来,我希望看到像Lean和Coq这样的助手的进步。这些系统(不一定)会自动证明数学定理或程序的正确性。相反,它们会自动验证给定证明的正确性。与kani相比,这些系统似乎很难使用,但可以潜在地验证更复杂的代码。这方面的进步将允许程序员(包括人类和人工智能)用程序正确的理由来增强程序。我相信这将使自动验证自动生成的代码变得更加容易。
来源:https://medium.com/@carlmkadie/check-ai-generated-code-perfectly-and-automatically-d5b61acff741

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消