











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用 Python 进行数据扩展
2023年07月05日 由 Susan 发表
999700
0
在机器学习过程中,数据缩放属于数据预处理或特征工程的范畴。在用于模型构建之前对数据进行缩放可以实现以下目标:
有几种方法可用于缩放数据。两个最重要的缩放技术是规范化和标准化。
当使用规范化缩放数据时,可以使用此公式计算转换后的数据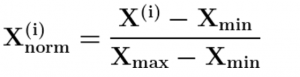 方程
方程
在哪里Xmax和Xmin分别是数据的最大值和最小值。获得的缩放数据在[0,1] 范围内
规范化的 Python 实现
使用规范化的扩展可以在 Python 中使用以下代码实现:
理想情况下,在数据服从正态或高斯分布时,应使用标准化。标准化后的数据可以按如下方式计算:
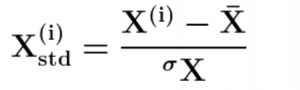 方程
方程
这里,×是数据的平均值,并且 Ó×是标准差。标准化值通常应位于[-2,2] 范围内,表示 95% 置信区间。小于-2 或大于 2 的标准化值可被视为异常值。因此,标准化可用于异常值检测。
可以使用以下代码在 Python 中实现标准化的扩展:
总之,我们讨论了两种最流行的特征扩展方法,即:标准化和规范化。规范化数据位于 [0, 1] 范围内,而标准化数据通常位于 [-2, 2] 范围内。标准化的优点是可用于异常值检测。
来源:https://www.kdnuggets.com/2023/07/data-scaling-python.html
- 缩放确保特征具有相同的数值范围。
- 缩放确保用于模型构建的特征是无量纲的。
- 缩放可用于检测异常值。
有几种方法可用于缩放数据。两个最重要的缩放技术是规范化和标准化。
使用规范化进行数据缩放
当使用规范化缩放数据时,可以使用此公式计算转换后的数据
方程在哪里Xmax和Xmin分别是数据的最大值和最小值。获得的缩放数据在[0,1] 范围内
规范化的 Python 实现
使用规范化的扩展可以在 Python 中使用以下代码实现:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)
设 X 为给定数据Xmax=17.7和 Xmax = 71.4。数据X如下图所示
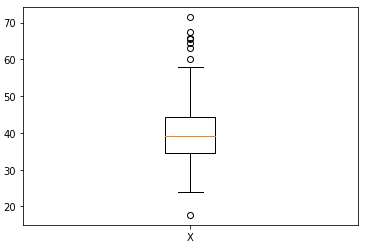
图1.数据 X 的箱线图,值介于 17.7 和 71.4 之间。
归一化的 X 如下图所示:
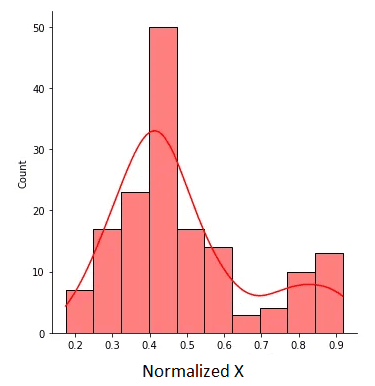
图2.值介于 0 和 1 之间的规范化 X。
使用标准化进行数据扩展
理想情况下,在数据服从正态或高斯分布时,应使用标准化。标准化后的数据可以按如下方式计算:
方程这里,×是数据的平均值,并且 Ó×是标准差。标准化值通常应位于[-2,2] 范围内,表示 95% 置信区间。小于-2 或大于 2 的标准化值可被视为异常值。因此,标准化可用于异常值检测。
Python标准化的实现
可以使用以下代码在 Python 中实现标准化的扩展:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)
使用上述数据,标准化数据如下所示:
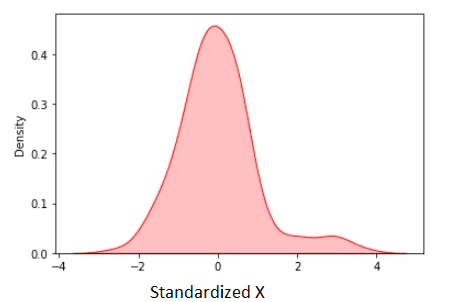
图3.标准化 X. 作者图片
标准化均值为零。从上图中我们观察到,除了少数异常值外,大多数标准化数据都在 [-2, 2] 范围内。
结论
总之,我们讨论了两种最流行的特征扩展方法,即:标准化和规范化。规范化数据位于 [0, 1] 范围内,而标准化数据通常位于 [-2, 2] 范围内。标准化的优点是可用于异常值检测。
来源:https://www.kdnuggets.com/2023/07/data-scaling-python.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消