











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从GPT-1到GPT-4:OpenAI进化语言模型的综合分析与比较
2023年07月06日 由 Susan 发表
210018
0
OpenAI提供了多种模型,每个模型都具有自己的特点和成本结构,以满足各种应用的需求。模型定期进行更新,以反映技术的最新进展。用户也可以对模型进行调整,使其更适合自己的需求。OpenAI的GPT模型为自然语言处理(NLP)带来了重大的进展。
在自然语言处理(NLP)应用中,一种常用的机器学习模型是生成式预训练转换器(GPT)。这些模型在大量信息,例如书籍和网站,上进行预训练,以产生自然流畅且结构良好的文本。
更简单地说,GPT是一种计算机程序,它可以生成看起来和读起来好像是人类写的文本,但并不是为此而设计的。这使它们在问题回答、翻译和文本摘要等NLP应用中具有可塑性。就自然语言处理而言,GPT是一个重要的进步,因为它们使机器能够以前所未有的流畅度和准确性理解和生成语言。下面将讨论四个GPT模型,从最初的GPT到最新的GPT-4,并分析它们的优缺点。
2018年,OpenAI推出了GPT-1,这是基于Transformer架构构建的语言模型的第一个版本。其1.17亿参数相比于当时最先进的语言模型来说是一个重大飞跃。
GPT-1能够根据提示或上下文产生自然、易懂的语言输出是它的许多能力之一。模型的训练过程利用了包含数十亿单词的庞大网页数据集Common Crawl以及包含超过11,000本各种主题图书的BookCorpus数据集。通过这些多样化的数据集,GPT-1能够提升其语言建模能力。
OpenAI在2019年发布了GPT-2以取代GPT-1。它比GPT-1大得多,拥有15亿个参数。通过将Common Crawl与WebText融合,使用了一个更大且更多样化的数据集来训练该模型。
GPT-2的一个优点是其能够构造逻辑合理的文本序列。它模仿人类反应的能力也使其成为自然语言处理中各种应用的有用资源,包括内容生成和翻译。
然而,GPT-2也存在一些缺点。它在进行复杂推理和上下文理解方面需要付出很多努力。尽管在较短的文本上表现出色,但GPT-2在保持较长篇章的连贯性和上下文方面仍存在一定的困难。
2020年发布的GPT-3开启了自然语言处理模型指数级增长的时期。GPT-3拥有1750亿个参数,是GPT-2的十倍以上,是GPT-1的一百倍以上。
GPT-3的训练数据包括BookCorpus、Common Crawl和维基百科,仅仅是其中的几个来源。在这些数据集上,使用很少或没有训练数据,GPT-3就能够在各种NLP任务上产生高质量的结果。
相比之前的模型,GPT-3在构思有意义的散文、编写计算机代码和创造艺术方面有着重大的进展。与前辈模型不同,GPT-3能够解释文本的上下文并给出相关回应。聊天机器人、原创内容生成和语言翻译只是很多应用领域中能够从生成自然文本的能力中获益的几个例子。
鉴于GPT-3的强大能力,人们同时也提出了关于这种强大语言模型的伦理影响和潜在滥用的担忧。许多专业人士担心该模型可能被滥用来创建有害内容,如恶作剧、网络钓鱼邮件和病毒。犯罪分子已经使用ChatGPT来开发恶意软件。
第四代GPT于2023年3月14日发布。它是对GPT-3的巨大改进,而GPT-3本身已经是一次革命性的突破。尽管该模型的架构和训练数据尚未公开,但很明显它在关键方面改进了GPT-3,并解决了之前版本的一些缺点。
ChatGPT Plus订阅者可以无限制地使用GPT-4,但时间是有限的。加入GPT-4 API等待列表是另一个选择,尽管在获得访问权限之前可能需要等待一段时间。不过,Microsoft Bing Chat是访问GPT-4的最快途径。参与其中无需付费或等待列表。
GPT-4的多模式功能是其一个显著特点。这使得模型可以将图片作为输入,并将其处理为文本提示。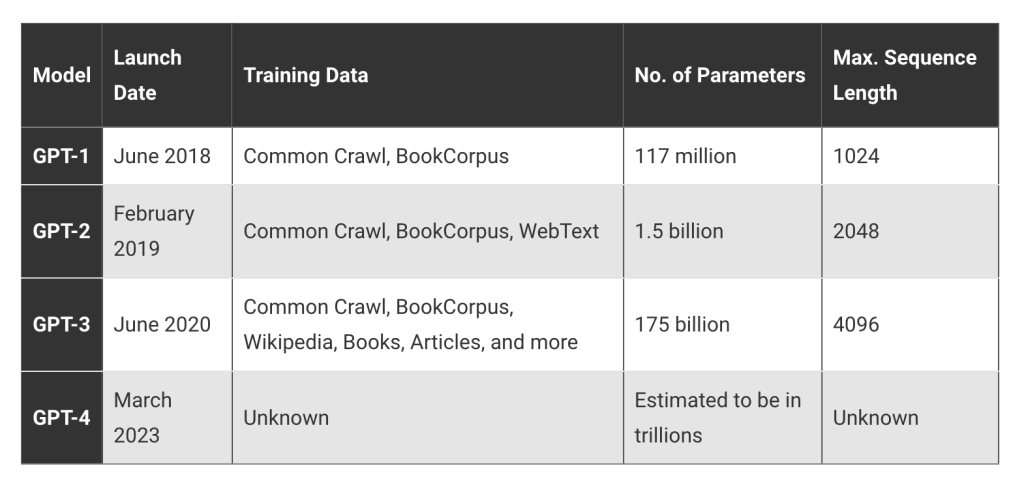
OpenAI的GPT-3模型是一组用于理解和生成自然语言的人工智能系统。尽管更先进的GPT-3.5模型已取代了这些模型,但原始的GPT-3基础模型(Da Vinci、Curie、Ada和Babbage)仍可供定制使用。由于各自的特点,每个模型最适合用于一定范围的应用。
对于简单的任务,Babbage可以胜任。它像Ada一样非常快速和廉价。在强调速度和效率优先于深入理解的工作中,Babbage表现出色。
这些模型是通过2019年10月的数据进行训练的,它们的最大令牌容量为2,049个。任务的复杂性、期望的输出质量以及可用的计算资源都在决定使用哪个模型时起着作用。
提供多种模型可以满足不同客户和情景的需求。使用比必要的更高性能的模型可能会增加不必要的计算成本,而并非所有的活动都需要最高容量级别。OpenAI为其客户提供多种模型,每个模型都有其自身的优点和缺点,以及对应的价格标签。
数据隐私对于OpenAI非常重要。除非用户选择加入,从2023年3月1日起,OpenAI API将不再使用用户数据进行模型的训练或改进。除非法律规定要求其保留,API数据最晚将在30天后被删除。零数据保留可能是高信任的消费者在使用特别敏感的应用程序时的选项。
OpenAI的模型是多样化的,每个模型都是为特定目的而构建的。以下简要描述了其中一些模型。
OpenAI承诺定期更新其模型。近期一些模型如gpt-3.5-turbo已经得到不断的更新。一旦发布了模型的新版本,之前的版本会继续得到支持至少三个月,以满足需要稳定性的开发者的需求。OpenAI通过其广泛的模型库、定期更新和对数据保护的重视,成为一个多功能的平台。OpenAI提供的模型可以检测敏感信息、将音频转换为文本以及生成自然语言。
来源:https://www.marktechpost.com/2023/07/05/from-gpt-1-to-gpt-4-a-comprehensive-analysis-and-comparison-of-openais-evolving-language-models/
简而言之,什么是 GPT?
在自然语言处理(NLP)应用中,一种常用的机器学习模型是生成式预训练转换器(GPT)。这些模型在大量信息,例如书籍和网站,上进行预训练,以产生自然流畅且结构良好的文本。
更简单地说,GPT是一种计算机程序,它可以生成看起来和读起来好像是人类写的文本,但并不是为此而设计的。这使它们在问题回答、翻译和文本摘要等NLP应用中具有可塑性。就自然语言处理而言,GPT是一个重要的进步,因为它们使机器能够以前所未有的流畅度和准确性理解和生成语言。下面将讨论四个GPT模型,从最初的GPT到最新的GPT-4,并分析它们的优缺点。
GPT-1
2018年,OpenAI推出了GPT-1,这是基于Transformer架构构建的语言模型的第一个版本。其1.17亿参数相比于当时最先进的语言模型来说是一个重大飞跃。
GPT-1能够根据提示或上下文产生自然、易懂的语言输出是它的许多能力之一。模型的训练过程利用了包含数十亿单词的庞大网页数据集Common Crawl以及包含超过11,000本各种主题图书的BookCorpus数据集。通过这些多样化的数据集,GPT-1能够提升其语言建模能力。
GPT-2
OpenAI在2019年发布了GPT-2以取代GPT-1。它比GPT-1大得多,拥有15亿个参数。通过将Common Crawl与WebText融合,使用了一个更大且更多样化的数据集来训练该模型。
GPT-2的一个优点是其能够构造逻辑合理的文本序列。它模仿人类反应的能力也使其成为自然语言处理中各种应用的有用资源,包括内容生成和翻译。
然而,GPT-2也存在一些缺点。它在进行复杂推理和上下文理解方面需要付出很多努力。尽管在较短的文本上表现出色,但GPT-2在保持较长篇章的连贯性和上下文方面仍存在一定的困难。
GPT-3
2020年发布的GPT-3开启了自然语言处理模型指数级增长的时期。GPT-3拥有1750亿个参数,是GPT-2的十倍以上,是GPT-1的一百倍以上。
GPT-3的训练数据包括BookCorpus、Common Crawl和维基百科,仅仅是其中的几个来源。在这些数据集上,使用很少或没有训练数据,GPT-3就能够在各种NLP任务上产生高质量的结果。
相比之前的模型,GPT-3在构思有意义的散文、编写计算机代码和创造艺术方面有着重大的进展。与前辈模型不同,GPT-3能够解释文本的上下文并给出相关回应。聊天机器人、原创内容生成和语言翻译只是很多应用领域中能够从生成自然文本的能力中获益的几个例子。
鉴于GPT-3的强大能力,人们同时也提出了关于这种强大语言模型的伦理影响和潜在滥用的担忧。许多专业人士担心该模型可能被滥用来创建有害内容,如恶作剧、网络钓鱼邮件和病毒。犯罪分子已经使用ChatGPT来开发恶意软件。
GPT-4
第四代GPT于2023年3月14日发布。它是对GPT-3的巨大改进,而GPT-3本身已经是一次革命性的突破。尽管该模型的架构和训练数据尚未公开,但很明显它在关键方面改进了GPT-3,并解决了之前版本的一些缺点。
ChatGPT Plus订阅者可以无限制地使用GPT-4,但时间是有限的。加入GPT-4 API等待列表是另一个选择,尽管在获得访问权限之前可能需要等待一段时间。不过,Microsoft Bing Chat是访问GPT-4的最快途径。参与其中无需付费或等待列表。
GPT-4的多模式功能是其一个显著特点。这使得模型可以将图片作为输入,并将其处理为文本提示。
https://www.makeuseof.com/gpt-models-explained-and-compared/
在 OpenAI 中建模
OpenAI的GPT-3模型是一组用于理解和生成自然语言的人工智能系统。尽管更先进的GPT-3.5模型已取代了这些模型,但原始的GPT-3基础模型(Da Vinci、Curie、Ada和Babbage)仍可供定制使用。由于各自的特点,每个模型最适合用于一定范围的应用。
- Davinci是GPT-3系列中最先进的模型,可以执行其同系列的其他模型能够完成的任何任务。它专为需要深入理解上下文和复杂性的复杂工作而构建。但与其他模型不同的是,这种强大功能的计算成本更高。
- Curie:这个模型具有与Davinci相同的高级功能,但价格更低,操作速度显著更高。对于许多工作来说,它是一个很好的选择,因为它在功能和效率之间找到了一个适中的平衡点。
- Ada:Ada专为初级编程工作而创建。它是GPT-3模型中最经济实惠和最快速的模型。如果工作不需要广泛的上下文专业知识,Ada可以具有成本效益。
对于简单的任务,Babbage可以胜任。它像Ada一样非常快速和廉价。在强调速度和效率优先于深入理解的工作中,Babbage表现出色。
这些模型是通过2019年10月的数据进行训练的,它们的最大令牌容量为2,049个。任务的复杂性、期望的输出质量以及可用的计算资源都在决定使用哪个模型时起着作用。
那么为什么我们需要这么多变体呢?
提供多种模型可以满足不同客户和情景的需求。使用比必要的更高性能的模型可能会增加不必要的计算成本,而并非所有的活动都需要最高容量级别。OpenAI为其客户提供多种模型,每个模型都有其自身的优点和缺点,以及对应的价格标签。
数据的利用和存储
数据隐私对于OpenAI非常重要。除非用户选择加入,从2023年3月1日起,OpenAI API将不再使用用户数据进行模型的训练或改进。除非法律规定要求其保留,API数据最晚将在30天后被删除。零数据保留可能是高信任的消费者在使用特别敏感的应用程序时的选项。
OpenAI的当前模型
OpenAI的模型是多样化的,每个模型都是为特定目的而构建的。以下简要描述了其中一些模型。
- GPT-4 Limited Beta是GPT-3.5系列的增强版本,能够读取和编写计算机代码和普通语言。它目前仍处于测试阶段,只有特定用户可以访问。
- GPT-3.5系列模型能够用自然语言解释和生成代码。其中,gpt-3.5-turbo是这个系列中功能最强大且性价比最高的成员,其在对话任务上表现出色,同时在更传统的补全任务上也非常出色。
- DALLE Beta:这种方法将视觉创意与语言理解相结合,以响应自然语言的要求来开发和编辑图形。
- Whisper是一种语音识别模型(beta版),可以将口述的文字转录为书面文字。基于大规模且多样化的数据集进行训练,它具备多语种语音识别、翻译和辨识的能力。
- 嵌入模型将文本转化为数值表示,以执行搜索、聚类、推荐、异常检测和分类等任务。这个模型经过训练,可以识别潜在问题文本,从而维护安全和有礼貌的空间。
- GPT-3系列模型能够理解和生成自然语言。虽然功能更强大的GPT-3.5版本已取代了原始的GPT-3基础模型,但它们仍然可以进行定制使用。
OpenAI承诺定期更新其模型。近期一些模型如gpt-3.5-turbo已经得到不断的更新。一旦发布了模型的新版本,之前的版本会继续得到支持至少三个月,以满足需要稳定性的开发者的需求。OpenAI通过其广泛的模型库、定期更新和对数据保护的重视,成为一个多功能的平台。OpenAI提供的模型可以检测敏感信息、将音频转换为文本以及生成自然语言。
来源:https://www.marktechpost.com/2023/07/05/from-gpt-1-to-gpt-4-a-comprehensive-analysis-and-comparison-of-openais-evolving-language-models/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消