











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






构建 GPT 内存层:通过函数调用实现
2023年07月18日 由 Alex 发表
924309
0
现在可以轻松使用新的GPT函数调用特性与向量存储(如Chroma)一起构建内存存储。
OpenAI GPT 3.5 / 4 ' 0613 '(6月13日)模型更新提供了一个非常强大的新特性,称为函数调用,它使与应用程序的集成变得更加容易,并且更具可扩展性。
首先,新模型经过了进一步的微调,能够决定何时调用外部函数、传递参数以及如何使用返回的结果。
函数调用特性允许你将描述应用程序函数签名的参数传递给LLM,然后LLM将决定何时以及如何使用你的函数。
在应用程序与LLM交互的整个过程中,你可以修改LLM可以在不同时间调用的函数。
一个非常基本的例子是在Python中定义一个函数,它根据位置参数简单地返回当前日期和时间。然后,你可以配置GPT来决定何时调用该函数(如果它需要当前时间)。调用该函数的一个实例可能是,如果你要求GPT设置任务到期日期,而它需要今天的日期来计算它。
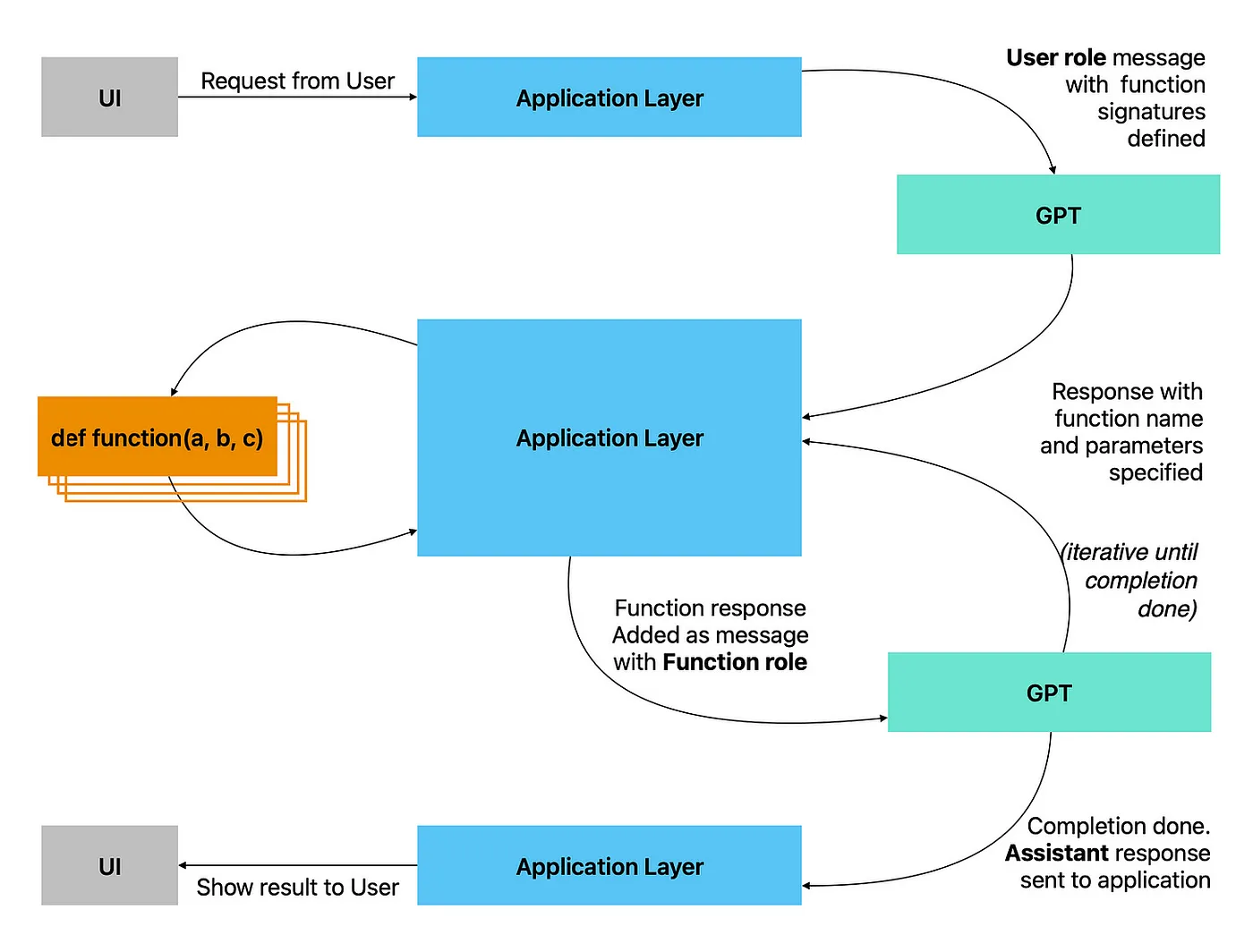
上图显示了如何使用函数调用构建的流程:
1. 该消息会向LLM发送完成提示。
2. 该消息还将包括一个函数参数,列出可用的函数及其用法。
3. 该消息还将指示是否必须调用特定函数,或者模型是否可以自动决定是否调用函数(设置为自动)。
4. 模型将使用一个finish_reason为stop或function_call的completion来响应。
5. Stop:补全完成,模型不需要调用函数;
6. Function_call:要调用的函数名(连同参数)将在响应中提供。
7. 应用层使用函数名和参数来调用函数并获得返回对象。
8. 它将返回对象序列化为JSON并将其添加到具有函数角色的新消息中。然后再次将其发送到模型进行完成。。
9. 重复步骤2、3和4,直到从模型接收到停止完成。
10. 最后的完成由应用层处理并发回给用户。
在本文中,我将给出一个非常基本的示例,说明如何提供可以跨用户会话的GPT 3.5或GPT 4内存。这个例子将使用Chroma作为这些记忆和函数调用的向量存储,以允许GPT“决定”何时存储或检索记忆。我们还将允许基于语义余弦相似性来检索记忆。
通过使用向量数据库和余弦相似度,我们可以检索到在GPT提示“我饿了”时提到食物的记忆。短语“我饿了”的向量嵌入将接近包含单词“苹果”或“午餐”的短语。
基本设置
1. 用于存储向量集合的Chroma数据库
2. OpenAI Ada模型获取字符串的向量嵌入
3. 打开AI GPT 3.5 turbo / GPT 4 0613模型版本的函数调用
在上面的代码块中,我们简单地设置了Chroma客户端并创建了样板代码来获取或创建向量集合。我们还指定在磁盘上存储数据的位置。唯一需要注意的是,我们指定余弦相似度作为检索相似向量的度量。
在这个代码块中,我们仅使用OpenAI创建嵌入库和ada v2嵌入模型(现在OpenAI推荐用于搜索和相似用例,而不是过时的v1模型)。
该函数仅接受一个字符串并返回表示该字符串的向量嵌入。重要的是,该函数用于所有内存嵌入以及搜索查询。
上面我们简单地获取/创建集合,生成嵌入,然后存储向量。需要明确告诉chroma客户端将数据保存到磁盘。
为每个内存生成一个uid,但为简单起见省略了元数据。在实践中,你将添加元数据键值对来表示诸如内存时间戳/内存到期日期/内存上下文等属性。
要检索内存,只需传递查询,将其转换为向量嵌入并搜索向量存储。这里唯一需要改变的参数是n,它定义了要返回多少个最近邻(即结果)。
在下面的代码块中;第一个函数process_input从模型获取补全并处理输出。它检查finish_reason,如果找到function_call响应,那么它将返回的参数链接到正确的函数中,并发出后续的完成请求,直到模型返回stop。
第二个函数get_completion是一个标准的get_completion OpenAI样板方法,它显示了如何定义要调用的函数。
通过运行上面的代码,我们可以测试python脚本,并查看GPT模型如何以及何时使用定义的函数来存储和检索内存。
例如,如果我现在要求GPT记住我的生日,它将自动选择调用store_memory函数并保存该信息以供将来使用。
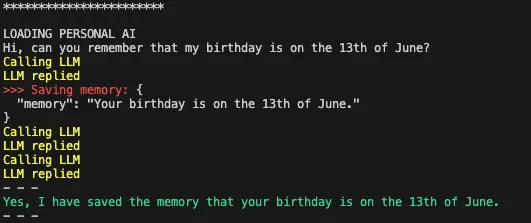
我现在可以开始一个新的会话,或者指向一个不同的模型,询问它是否记得我的生日——它会自动选择调用retrieve_memories函数。它还传递与生日相关的合适搜索查询。
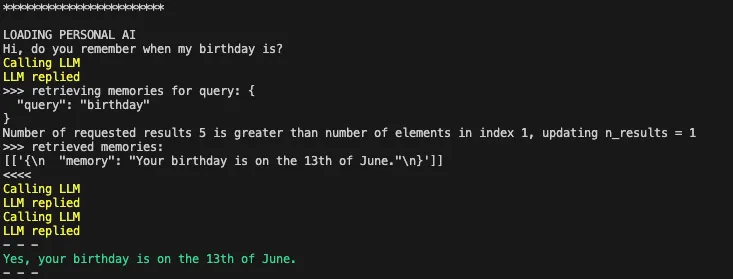
最后,如果我问一个不需要访问外部内存存储的问题,它将选择不调用任何函数,而只是立即响应。

来源:https://medium.com/@simon_attard/building-a-memory-layer-for-gpt-using-function-calling-da17d66920d0
OpenAI GPT 3.5 / 4 ' 0613 '(6月13日)模型更新提供了一个非常强大的新特性,称为函数调用,它使与应用程序的集成变得更加容易,并且更具可扩展性。
首先,新模型经过了进一步的微调,能够决定何时调用外部函数、传递参数以及如何使用返回的结果。
函数调用特性允许你将描述应用程序函数签名的参数传递给LLM,然后LLM将决定何时以及如何使用你的函数。
在应用程序与LLM交互的整个过程中,你可以修改LLM可以在不同时间调用的函数。
一个非常基本的例子是在Python中定义一个函数,它根据位置参数简单地返回当前日期和时间。然后,你可以配置GPT来决定何时调用该函数(如果它需要当前时间)。调用该函数的一个实例可能是,如果你要求GPT设置任务到期日期,而它需要今天的日期来计算它。
函数调用流程
上图显示了如何使用函数调用构建的流程:
1. 该消息会向LLM发送完成提示。
2. 该消息还将包括一个函数参数,列出可用的函数及其用法。
3. 该消息还将指示是否必须调用特定函数,或者模型是否可以自动决定是否调用函数(设置为自动)。
4. 模型将使用一个finish_reason为stop或function_call的completion来响应。
5. Stop:补全完成,模型不需要调用函数;
6. Function_call:要调用的函数名(连同参数)将在响应中提供。
7. 应用层使用函数名和参数来调用函数并获得返回对象。
8. 它将返回对象序列化为JSON并将其添加到具有函数角色的新消息中。然后再次将其发送到模型进行完成。。
9. 重复步骤2、3和4,直到从模型接收到停止完成。
10. 最后的完成由应用层处理并发回给用户。
构建内存层
在本文中,我将给出一个非常基本的示例,说明如何提供可以跨用户会话的GPT 3.5或GPT 4内存。这个例子将使用Chroma作为这些记忆和函数调用的向量存储,以允许GPT“决定”何时存储或检索记忆。我们还将允许基于语义余弦相似性来检索记忆。
通过使用向量数据库和余弦相似度,我们可以检索到在GPT提示“我饿了”时提到食物的记忆。短语“我饿了”的向量嵌入将接近包含单词“苹果”或“午餐”的短语。
#We will be using the cosine similarity implementation provided by Chroma.
#The code below demonstrates how the cosine similarity can be computed
#for vectors A and B. (This is not the Chroma implementation)
import numpy as np
from numpy.linalg import norm
def cosine_similarity(A, B):
cosine = np.dot(A, B) / (norm(A) * norm(B))
return cosine基本设置
1. 用于存储向量集合的Chroma数据库
2. OpenAI Ada模型获取字符串的向量嵌入
3. 打开AI GPT 3.5 turbo / GPT 4 0613模型版本的函数调用
第1步-设置Chroma并创建向量集合
import uuid
import chromadb
from chromadb.config import Settings
chroma_client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="/store/mem_store"
))
def get_or_create_collection(collection_name):
collection = chroma_client.get_or_create_collection(name=collection_name, metadata{"hnsw:space": "cosine"})
return collection在上面的代码块中,我们简单地设置了Chroma客户端并创建了样板代码来获取或创建向量集合。我们还指定在磁盘上存储数据的位置。唯一需要注意的是,我们指定余弦相似度作为检索相似向量的度量。
第2步-定义一个函数来生成嵌入
import openai
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def get_embedding(text, model="text-embedding-ada-002"):
tokens = tokenizer.encode(text)
#we can use tiktoken tokenizer to count tokens and ensure token limit is not exceeded. In this case we will simply pass text to ada v2 model.
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
在这个代码块中,我们仅使用OpenAI创建嵌入库和ada v2嵌入模型(现在OpenAI推荐用于搜索和相似用例,而不是过时的v1模型)。
该函数仅接受一个字符串并返回表示该字符串的向量嵌入。重要的是,该函数用于所有内存嵌入以及搜索查询。
第3步-定义一个存储内存的函数
def add_vector(collection, text, metadata):
id = str(uuid.uuid4())
embedding = get_embedding(text)
collection.add(
embeddings = [embedding],
documents = [text],
metadatas = [metadata],
ids = [id]
)
def save_memory(memory):
collection = get_or_create_collection("memories")
add_vector(collection, memory, {})
chroma_client.persist()
上面我们简单地获取/创建集合,生成嵌入,然后存储向量。需要明确告诉chroma客户端将数据保存到磁盘。
为每个内存生成一个uid,但为简单起见省略了元数据。在实践中,你将添加元数据键值对来表示诸如内存时间戳/内存到期日期/内存上下文等属性。
第4步-定义一个函数来检索记忆
def query_vectors(collection, query, n):
query_embedding = get_embedding(query)
return collection.query(
query_embeddings = [query_embedding],
n_results = n
)
def retrieve_memories(query):
collection = get_or_create_collection("memories")
res = query_vectors(collection, query, 5)
print(">>> retrieved memories: ")
print(res["documents"])
return res["documents"]
要检索内存,只需传递查询,将其转换为向量嵌入并搜索向量存储。这里唯一需要改变的参数是n,它定义了要返回多少个最近邻(即结果)。
第5步-设置OpenAI完成和辅助方法
在下面的代码块中;第一个函数process_input从模型获取补全并处理输出。它检查finish_reason,如果找到function_call响应,那么它将返回的参数链接到正确的函数中,并发出后续的完成请求,直到模型返回stop。
第二个函数get_completion是一个标准的get_completion OpenAI样板方法,它显示了如何定义要调用的函数。
def process_input(user_input):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_input}
]
response = get_completion(messages)
if response.choices[0]["finish_reason"] == "stop":
reply_message = response.choices[0].message["content"].strip()
print(reply_message )
elif response. choices[0]["finish_reason"] == "function_call":
function_name = response.choices[0].message["function_call"].name
function_parameters = response.choices[0].message["function_call"].arguments
function_result = ""
if function_name == "save_memory":
function_result = save_memory(function_parameters)
elif function_name == "retrieve_memories":
function_result = retrieve_memories(function_parameters)
messages.append(
{
"role": "assistant",
"content": None,
"function_call": {"name": function_name, "arguments": function_parameters,},
}
)
messages.append(
{
"role": "function",
"name": function_name,
"content": f'{{"result": {str(function_result)}}}'
}
)
response = get_completion(messages)
return reply_message
def get_completion(messages):
functions = [
{
"name": "save_memory",
"description": """Use this function if I mention something which you think would be useful in the future and should be saved as a memory.
Saved memories will allow you to retrieve snippets of past conversations when needed.""",
"parameters": {
"type": "object",
"properties": {
"memory": {
"type": "string",
"description": "A short string describing the memory to be saved"
},
},
"required": ["memory"]
}
},
{
"name": "retrieve_memories",
"description": """Use this function to query and retrieve memories of important conversation snippets that we had in the past.
Use this function if the information you require is not in the current prompt or you need additional information to refresh your memory.""",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The query to be used to look up memories from a vector database"
},
},
"required": ["query"]
}
},
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
#model="gpt-4-0613",
messages=messages,
functions=functions,
max_tokens=200,
stop=None,
temperature=0.5,
function_call="auto"
)
return response
结论
通过运行上面的代码,我们可以测试python脚本,并查看GPT模型如何以及何时使用定义的函数来存储和检索内存。
例如,如果我现在要求GPT记住我的生日,它将自动选择调用store_memory函数并保存该信息以供将来使用。
我现在可以开始一个新的会话,或者指向一个不同的模型,询问它是否记得我的生日——它会自动选择调用retrieve_memories函数。它还传递与生日相关的合适搜索查询。
最后,如果我问一个不需要访问外部内存存储的问题,它将选择不调用任何函数,而只是立即响应。
来源:https://medium.com/@simon_attard/building-a-memory-layer-for-gpt-using-function-calling-da17d66920d0

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消