











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






实现浏览器中的AI梦想——Transformers.js提供零成本和极致隐私
2023年07月19日 由 Alex 发表
170107
0
Transformers.js可在你的 Web 浏览器中实现最先进的机器学习,无需服务器。它提供了预训练模型和熟悉的API,支持自然语言处理、计算机视觉、音频和多模态领域的任务。使用Transformers.js,开发人员可以在浏览器中直接地运行文本分类、图像分类、语音识别等任务,使其成为ML从业者和研究人员的强大工具。
将现有代码转换为Transformers.js是一个简单的过程。就像python库一样,Transformer.js支持管道API,它将预训练模型与输入预处理和输出后处理相结合。这让使用库运行模型非常容易。
下面是一个使用Transformers.js将Python代码转换为JavaScript的例子:
Python(原始):
JavaScript (Transformers.js):
你还可以利用 CDN 或静态托管在普通 JavaScript 中使用 Transformers.js,而无需捆绑程序。要做到这一点,你可以使用ES模块导入库,如下所示:
pipeline()函数提供了一种快速简便的方法来利用预训练模型进行推理任务。
我创建了一个基本的HTML文件,其中包含一个HTML表单来捕获用户输入。情绪结果显示在输出div中,指示输入是积极的、中性的还是消极的。
现在我们将添加Transform .js库的CDN链接,因为我们没有指定要使用哪个模型,它将使用默认模型,即Xenova/distilbert-base- uncassed -finetune -sst-2-english
当你运行代码时,默认模型将被下载并存储在缓存中。这加快了模型加载和应用程序未来执行的推理速度。
要验证默认模型是否已成功加载到缓存中,你可以检查可用的缓存空间。这将允许你确定模型是否已被缓存,以及是否有足够的空间。
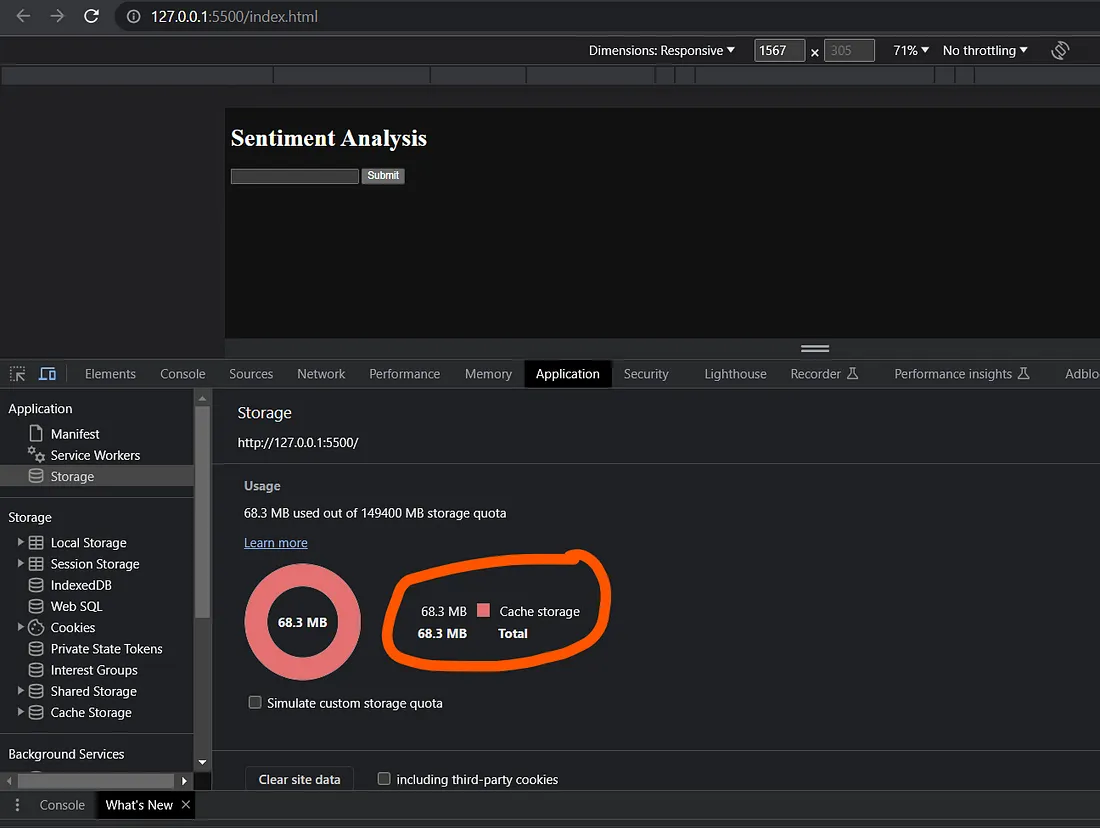
你可以通过检查浏览器DevTools的“Application”选项卡中的缓存值来验证模型是否已成功加载。如果缓存值与你从hug Face模型部分获得的模型的大小匹配,则表明该模型已成功加载并存储在缓存中。
现在,让我们将代码用于情感分析。这个过程类似于Python,我们接受用户输入并将其传递给分类器。单击按钮后,输入被发送到分类器,分类器返回一个消极或积极的情感标签。
让我们仔细看看更新后的脚本标签代码:
这里有两行很重要:
pipeline()函数定义我们想要执行的任务,而分类器从HTML表单获取输入值并将其传递给缓存的转换器模型。这个过程使我们能够利用预训练模型的力量进行情感分析。
下面是完整的代码:
让我们运行我们的webapp:
来源:https://medium.com/@fareedkhandev/transformers-js-ai-in-the-browser-zero-server-costs-maximum-privacy-2cd8d28798b7
将现有代码转换为Transformers.js是一个简单的过程。就像python库一样,Transformer.js支持管道API,它将预训练模型与输入预处理和输出后处理相结合。这让使用库运行模型非常容易。
下面是一个使用Transformers.js将Python代码转换为JavaScript的例子:
Python(原始):
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
pipe = pipeline('sentiment-analysis')
out = pipe('I love transformers!')
# [{'label': 'POSITIVE', 'score': 0.999806941}]
JavaScript (Transformers.js):
import { pipeline } from '@xenova/transformers';
// Allocate a pipeline for sentiment-analysis
let pipe = await pipeline('sentiment-analysis');
let out = await pipe('I love transformers!');
// [{'label': 'POSITIVE', 'score': 0.999817686}]你还可以利用 CDN 或静态托管在普通 JavaScript 中使用 Transformers.js,而无需捆绑程序。要做到这一点,你可以使用ES模块导入库,如下所示:
pipeline()函数提供了一种快速简便的方法来利用预训练模型进行推理任务。
初学者指南
我创建了一个基本的HTML文件,其中包含一个HTML表单来捕获用户输入。情绪结果显示在输出div中,指示输入是积极的、中性的还是消极的。
Sentiment Analysis
现在我们将添加Transform .js库的CDN链接,因为我们没有指定要使用哪个模型,它将使用默认模型,即Xenova/distilbert-base- uncassed -finetune -sst-2-english
Sentiment Analysis
当你运行代码时,默认模型将被下载并存储在缓存中。这加快了模型加载和应用程序未来执行的推理速度。
要验证默认模型是否已成功加载到缓存中,你可以检查可用的缓存空间。这将允许你确定模型是否已被缓存,以及是否有足够的空间。
你可以通过检查浏览器DevTools的“Application”选项卡中的缓存值来验证模型是否已成功加载。如果缓存值与你从hug Face模型部分获得的模型的大小匹配,则表明该模型已成功加载并存储在缓存中。
现在,让我们将代码用于情感分析。这个过程类似于Python,我们接受用户输入并将其传递给分类器。单击按钮后,输入被发送到分类器,分类器返回一个消极或积极的情感标签。
让我们仔细看看更新后的脚本标签代码:
...
这里有两行很重要:
// Specifying classifier
let classifier = await pipeline('sentiment-analysis');
// classifying the input text
let result = await classifier(inputText.value);
pipeline()函数定义我们想要执行的任务,而分类器从HTML表单获取输入值并将其传递给缓存的转换器模型。这个过程使我们能够利用预训练模型的力量进行情感分析。
下面是完整的代码:
Sentiment Analysis
让我们运行我们的webapp:
来源:https://medium.com/@fareedkhandev/transformers-js-ai-in-the-browser-zero-server-costs-maximum-privacy-2cd8d28798b7

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消