











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Hugging Face上最好的基于Transformer的LLM(下)
2023年07月24日 由 Camellia 发表
710422
0
在2018年6月,OpenAI发布了GPT,这是第一个预训练的Transformer模型,用于在各种自然语言处理任务上进行微调并获得了最先进的结果。
在上一部分中,我们讨论了Transformer是自然语言处理的核心。现在让我们来看一看自回归模型和序列到序列模型。
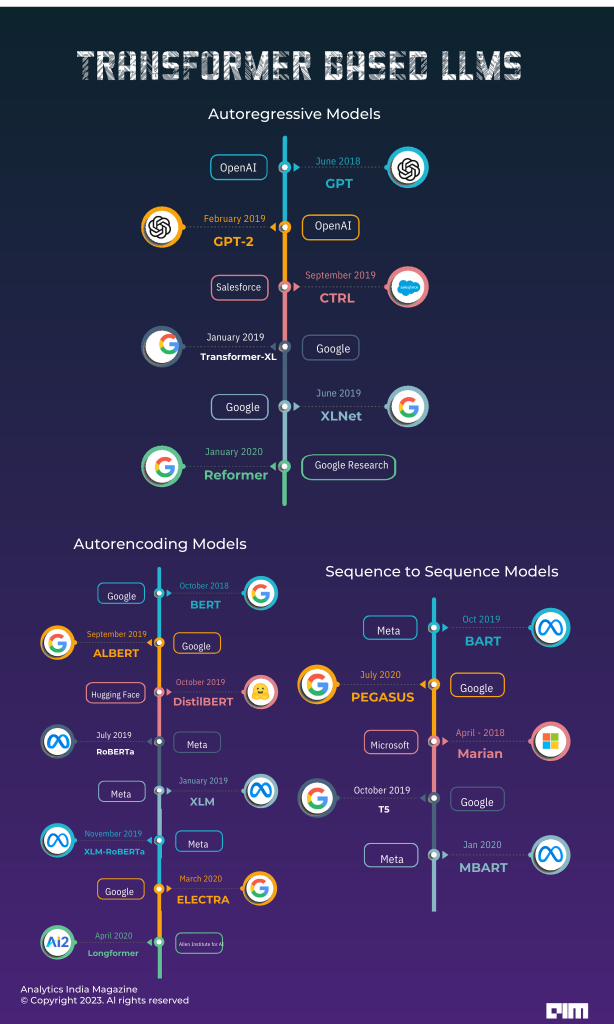
自回归模型是在语言建模任务上进行训练的,根据上下文预测下一个单词。它们是原始Transformer模型的解码器部分,使用掩码仅在注意力机制中考虑前面的单词。虽然这些模型可以用于各种任务的微调,但它们的主要用途是文本生成。让我们来看一些这样的模型。
GPT:通过生成预训练来改进语言理解
在2018年6月,OpenAI发布了GPT,这是第一个预训练的Transformer模型,用于在各种自然语言处理任务上进行微调,并取得了最先进的结果。通过在多样化的未标记文本上训练语言模型,并在微调过程中使用针对任务的输入转换,在各种任务中实现了显著改进。超越了任务特定模型,这种方法展示了显著的提高,如常识推理提高了8.9%、问答提高了5.7%、文本蕴涵提高了1.5%。它展示了无监督(预)训练在提升辨别性任务性能方面的潜力,并提供了包含长程相关性数据的Transformer的有效性的见解。
GPT-2:语言模型是无监督的多任务学习者
作为GPT的升级版本,OpenAI推出了GPT-2,它是在称为WebText的大型数据集上进行预训练的。通过为模型提供文档和问题,它在CoQA数据集上的表现非常好,而无需大量的训练样例。使语言模型更大可以提高其在各种任务上的性能。GPT-2在几个语言建模数据集上优于其他模型,并生成更连贯的文本样本。
CTRL:用于可控生成的条件Transformer语言模型
2019年,Salesforce推出了CTRL,一种强大的16.3亿参数语言模型。CTRL使用控制代码来规定样式、内容和任务特定行为。这些代码源自自然文本结构,使得能够进行精确的文本生成同时保留无监督学习的优势。CTRL还可以预测序列的训练数据最可能的部分,提供了一种通过基于模型的源属性分析大量数据的方法。
Transformer-XL:超越固定长度的注意力语言模型
卡内基梅隆大学和谷歌携手开发了Transformer-XL,用于学习长距离依赖关系,而不破坏时间连贯性。它包含分段级别的循环和一种新颖的位置编码方案,使其能够捕捉比RNN长80%的依赖关系和比传统Transformer长450%的依赖关系。这导致了在短序列和长序列上的性能改进,并在评估过程中实现了显著的加速,速度比传统Transformer快1800多倍。
Reformer:高效Transformer
谷歌研究公司再次提出,基于Transformer的Reformer采用了新的方法来减少内存使用和计算时间。这些技巧包括使用轴向位置编码来处理长序列,而无需庞大的位置编码矩阵。与传统的注意力不同,它使用LSH(局部敏感散列)注意力来节省注意力层期间的计算。每一层都不会存储中间结果,而是在反向传递过程中使用可逆Transformer层获得或根据需要重新计算,从而节省内存。此外,前馈计算是以更小的块而不是整个批量进行。结果是,与传统的自回归Transformer相比,该模型可以处理更长的句子。
XLNet:用于语言理解的广义自回归预训练
谷歌的XLNet对句子的token进行重新排列,然后使用前面的token来预测下一个token。这通过掩码方法实现,其中隐藏了句子的特定排列,允许模型理解正确的顺序。此外,XLNet使用了Transformer-XL的循环机制,用于建立远距离token之间的连接,以实现长期依赖性。该库包括适用于语言建模、token分类、句子分类、多项选择分类和问答任务的各种模型版本。
序列到序列模型结合了Transformer的编码器和解码器,用于处理各种任务,包括翻译、总结和问答。它们可以适应不同的任务,但最常用于翻译、总结和问答。
BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练
Meta的BART是用于写作、翻译和理解等语言任务的序列到序列模型。它包括一个编码器和一个解码器。编码器处理损坏的token,而解码器则处理原始token,屏蔽未来的单词。在预训练期间,编码器应用各种转换,如屏蔽随机token、删除token、使用单个掩码token掩蔽token跨度、置换句子和旋转文档以从特定的token开始。
PEGASUS:用提取的间隔句进行抽象总结的预训练
PEGASUS与BART具有相同的编码器-解码器模型架构,采用两个自监督目标进行预训练:掩码语言建模(MLM)和用于总结的间隔句生成(GSG)。在MLM中,随机token被掩蔽并由编码器预测,类似于BERT。 在GSG中,整个编码器输入句子被掩蔽并馈送到解码器,解码器具有因果掩码来预测未来的单词。 与BART不同,Pegasus的预训练任务非常类似于总结,其中重要的句子被掩蔽并作为剩余句子的一个输出序列一起生成,类似于提取摘要。
Marian:C++中的快速神经机器翻译
微软开发的Marian是一个强大且独立的神经机器翻译系统。它包括一个基于动态计算图的集成自动微分引擎。Marian完全使用C++编写。该系统的编码器-解码器框架旨在实现高训练效率和快速翻译速度,使其成为有助于研究的工具包。
T5:通过统一的文本到文本Transformer探索迁移学习的极限
谷歌的T5通过在每一层学习位置嵌入,对传统的Transformer模型进行了修改。它通过使用特定前缀将各种自然语言处理任务转化为文本到文本的挑战,如“总结”、“问题”、“将英语翻译为德语”等来处理这些任务。预训练包括监督和自我监督训练。监督训练使用GLUE和SuperGLUE基准作为下游任务,转换为文本到文本的格式。自我监督训练涉及破坏输入句子中的token,随机删除其中的15%,并用单个标记token替换。编码器使用损坏的句子,解码器使用原始句子,目标包括被删除token和其标记token界定的序列。
MBart:用于神经机器翻译的多语言去噪预训练
Meta的MBart与BART具有相似的结构和训练目标,但其训练在25种不同的语言上。它的主要目的是在受监督和无监督的机器翻译任务中表现出色。MBart通过在完整文本上使用去噪技术,在多种语言上预训练整个序列到序列模型的新方法。
来源:https://analyticsindiamag.com/best-transformer-based-llms-on-hugging-face-part-2/
在上一部分中,我们讨论了Transformer是自然语言处理的核心。现在让我们来看一看自回归模型和序列到序列模型。
自回归模型
自回归模型是在语言建模任务上进行训练的,根据上下文预测下一个单词。它们是原始Transformer模型的解码器部分,使用掩码仅在注意力机制中考虑前面的单词。虽然这些模型可以用于各种任务的微调,但它们的主要用途是文本生成。让我们来看一些这样的模型。
GPT:通过生成预训练来改进语言理解
在2018年6月,OpenAI发布了GPT,这是第一个预训练的Transformer模型,用于在各种自然语言处理任务上进行微调,并取得了最先进的结果。通过在多样化的未标记文本上训练语言模型,并在微调过程中使用针对任务的输入转换,在各种任务中实现了显著改进。超越了任务特定模型,这种方法展示了显著的提高,如常识推理提高了8.9%、问答提高了5.7%、文本蕴涵提高了1.5%。它展示了无监督(预)训练在提升辨别性任务性能方面的潜力,并提供了包含长程相关性数据的Transformer的有效性的见解。
GPT-2:语言模型是无监督的多任务学习者
作为GPT的升级版本,OpenAI推出了GPT-2,它是在称为WebText的大型数据集上进行预训练的。通过为模型提供文档和问题,它在CoQA数据集上的表现非常好,而无需大量的训练样例。使语言模型更大可以提高其在各种任务上的性能。GPT-2在几个语言建模数据集上优于其他模型,并生成更连贯的文本样本。
CTRL:用于可控生成的条件Transformer语言模型
2019年,Salesforce推出了CTRL,一种强大的16.3亿参数语言模型。CTRL使用控制代码来规定样式、内容和任务特定行为。这些代码源自自然文本结构,使得能够进行精确的文本生成同时保留无监督学习的优势。CTRL还可以预测序列的训练数据最可能的部分,提供了一种通过基于模型的源属性分析大量数据的方法。
Transformer-XL:超越固定长度的注意力语言模型
卡内基梅隆大学和谷歌携手开发了Transformer-XL,用于学习长距离依赖关系,而不破坏时间连贯性。它包含分段级别的循环和一种新颖的位置编码方案,使其能够捕捉比RNN长80%的依赖关系和比传统Transformer长450%的依赖关系。这导致了在短序列和长序列上的性能改进,并在评估过程中实现了显著的加速,速度比传统Transformer快1800多倍。
Reformer:高效Transformer
谷歌研究公司再次提出,基于Transformer的Reformer采用了新的方法来减少内存使用和计算时间。这些技巧包括使用轴向位置编码来处理长序列,而无需庞大的位置编码矩阵。与传统的注意力不同,它使用LSH(局部敏感散列)注意力来节省注意力层期间的计算。每一层都不会存储中间结果,而是在反向传递过程中使用可逆Transformer层获得或根据需要重新计算,从而节省内存。此外,前馈计算是以更小的块而不是整个批量进行。结果是,与传统的自回归Transformer相比,该模型可以处理更长的句子。
XLNet:用于语言理解的广义自回归预训练
谷歌的XLNet对句子的token进行重新排列,然后使用前面的token来预测下一个token。这通过掩码方法实现,其中隐藏了句子的特定排列,允许模型理解正确的顺序。此外,XLNet使用了Transformer-XL的循环机制,用于建立远距离token之间的连接,以实现长期依赖性。该库包括适用于语言建模、token分类、句子分类、多项选择分类和问答任务的各种模型版本。
序列到序列模型
序列到序列模型结合了Transformer的编码器和解码器,用于处理各种任务,包括翻译、总结和问答。它们可以适应不同的任务,但最常用于翻译、总结和问答。
BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练
Meta的BART是用于写作、翻译和理解等语言任务的序列到序列模型。它包括一个编码器和一个解码器。编码器处理损坏的token,而解码器则处理原始token,屏蔽未来的单词。在预训练期间,编码器应用各种转换,如屏蔽随机token、删除token、使用单个掩码token掩蔽token跨度、置换句子和旋转文档以从特定的token开始。
PEGASUS:用提取的间隔句进行抽象总结的预训练
PEGASUS与BART具有相同的编码器-解码器模型架构,采用两个自监督目标进行预训练:掩码语言建模(MLM)和用于总结的间隔句生成(GSG)。在MLM中,随机token被掩蔽并由编码器预测,类似于BERT。 在GSG中,整个编码器输入句子被掩蔽并馈送到解码器,解码器具有因果掩码来预测未来的单词。 与BART不同,Pegasus的预训练任务非常类似于总结,其中重要的句子被掩蔽并作为剩余句子的一个输出序列一起生成,类似于提取摘要。
Marian:C++中的快速神经机器翻译
微软开发的Marian是一个强大且独立的神经机器翻译系统。它包括一个基于动态计算图的集成自动微分引擎。Marian完全使用C++编写。该系统的编码器-解码器框架旨在实现高训练效率和快速翻译速度,使其成为有助于研究的工具包。
T5:通过统一的文本到文本Transformer探索迁移学习的极限
谷歌的T5通过在每一层学习位置嵌入,对传统的Transformer模型进行了修改。它通过使用特定前缀将各种自然语言处理任务转化为文本到文本的挑战,如“总结”、“问题”、“将英语翻译为德语”等来处理这些任务。预训练包括监督和自我监督训练。监督训练使用GLUE和SuperGLUE基准作为下游任务,转换为文本到文本的格式。自我监督训练涉及破坏输入句子中的token,随机删除其中的15%,并用单个标记token替换。编码器使用损坏的句子,解码器使用原始句子,目标包括被删除token和其标记token界定的序列。
MBart:用于神经机器翻译的多语言去噪预训练
Meta的MBart与BART具有相似的结构和训练目标,但其训练在25种不同的语言上。它的主要目的是在受监督和无监督的机器翻译任务中表现出色。MBart通过在完整文本上使用去噪技术,在多种语言上预训练整个序列到序列模型的新方法。
来源:https://analyticsindiamag.com/best-transformer-based-llms-on-hugging-face-part-2/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消