











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Hugging Face上最好的基于Transformer的LLM(上)
2023年07月24日 由 Samoyed 发表
563832
0
2017年推出的Transformer架构改进了自然语言处理。很快,GPT、BERT、GPT-2、DistilBERT、BART、T5和GPT-3以及现在的GPT-4等模型相继问世,每个模型都具有独特的功能,并进行了各种改进。这些模型可以根据其设计分为三类:自动编码模型、自回归模型和序列到序列模型。

通过改变输入的token然后重建初始句子进行训练,自动编码模型遵循与原始Transformer模型的编码器类似的模式,可以在没有任何掩码的情况下访问完整的输入。这些模型创建出整个双向表示的句子,并可进一步完善,从而在文本生成等任务中发挥出色的性能。
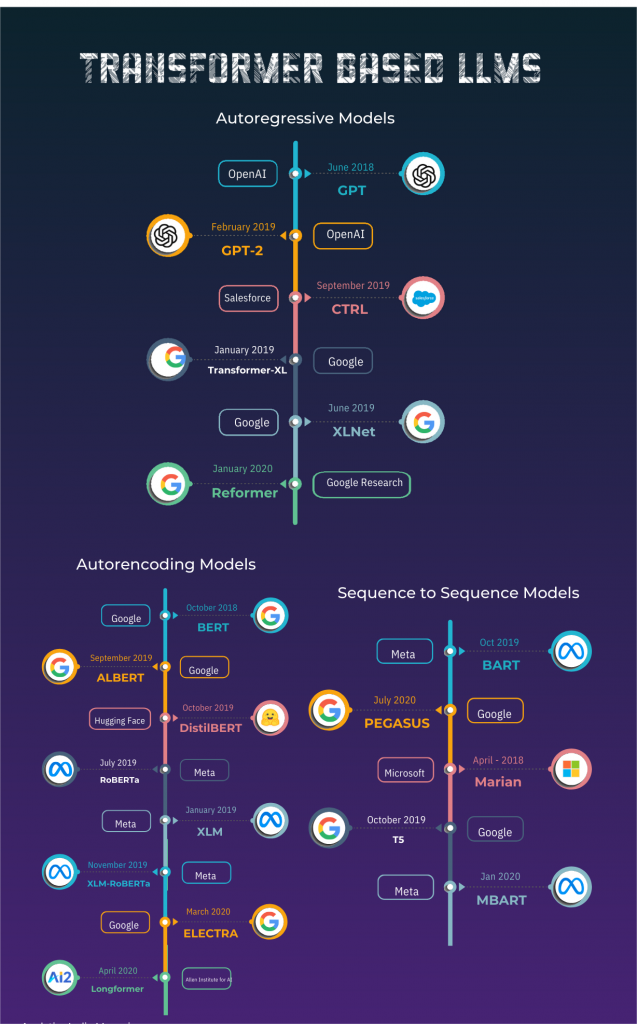
不过,它们最适合用于句子或 token分类。下面是一些对它的应用。
BERT:用于语言理解的深度双向Transformer预训练
2018年,谷歌推出了BERT,在预训练阶段将随机性引入输入数据。通常情况下,15%的token会使用三种不同的概率进行屏蔽:使用特殊的掩码token的概率为0.8,使用非掩码token的随机token的概率为0.1,使用相同的token的概率为0.1。
该模型的主要任务是从被屏蔽的输入中预测原始句子。模型会得到两个句子A和B,中间有一个分隔token。这些句子在语料库中有50%的可能性是连续的,有50%的可能性是不相关的。该模型的第二个目标是预测句子是否连续。
ALBERT:用于语言表征自我监督学习的简易 BERT
Google Research和Toyota technology Institute的ALBERT类似于BERT,但做了一些修改,比如嵌入大小(E)不同于隐藏大小(H),因为嵌入是与语境无关的,而隐藏状态是与语境相关的,使得H >> E更符合逻辑。当E < H时,庞大的嵌入矩阵(V × E)导致参数较多。
此外,为节省内存,各层采用共享参数分组。ALBERT 采用了句子排序预测,而不是下一句预测,也就是给出两个连续的句子A和B作为输入,模型预测它们是否被交换过。
DistilBERT:精简版的BERT
Hugging Face通过简化创造了这个小版本的BERT,它可以像大的版本一样学习预测概率。它的目标是实现与参考模型相同的概率,正确预测掩码token,并保持与参考模型隐藏状态之间的相似性。
RoBERTa:鲁棒优化的BERT预训练方法
与BERT类似,RoBERTa引入了增强的预训练技术。一个值得注意的改进是动态掩蔽,其中token在每个训练时期被不同地掩蔽,而不像BERT的固定掩蔽。由Paul G Allen计算机科学与工程学院和华盛顿大学建立的模型消除了NSP损失,而是将连续文本块组合成512个token,可能跨越多个文档。
此外,在训练过程中使用更大的批量,提高了效率。最后,还使用了以字节为子单位的BPE来更有效地处理unicode字符。
XLM:跨语言的语言模型预训练
XLM由Meta构建,是另一种基于Transformer的多语言训练模型,有三种类型的训练:因果语言建模(CLM),掩码语言建模(MLM),以及MLM和翻译语言建模(TLM)。CLM和MLM涉及为每个训练样本选择一种语言,并处理可能跨越该语言多个文档的 256 个token的句子。
TLM将两种不同语言的句子与随机屏蔽结合起来,允许模型使用两种语境来预测被屏蔽的token。模型的检查点根据使用的预训练方法(CLM、MLM 或 MLM-TLM)命名,并将语言嵌入与位置嵌入结合起来,以判断训练期间所使用的语言。
XLM-RoBERTa:大规模的无监督跨语言表示学习
XLM-RoBERTa结合了RoBERTa技术和XLM,但不包括翻译语言建模。相反,它专注于单一语言句子中的屏蔽语言建模。该模型由Meta制作,在大量语言(100种)上进行训练,并具有识别输入语言的能力,而无需依赖语言嵌入。
ELECTRA:作为鉴别器而不是生成器的预训练文本编码器
斯坦福大学和谷歌开发了ELECTRA,这是一种特殊的Transformer模型,它通过利用一个较小的屏蔽语言模型来学习。这个较小的模型通过随机屏蔽某些部分来破坏输入文本,ELECTRA的任务是找出哪些token是原始的,哪些是替换的。
与GAN训练类似,较小的模型以原始文本为目标进行训练,而不是像传统GAN那样欺骗ELECTRA。之后,ELECTRA模型将在几个步骤中进行训练以提高其性能。
Longformer:长文档转换器
Allen人工智能研究所的Longformer是一个比传统模型更快的Transformer模型,因为它使用稀疏矩阵而不是密集矩阵。这允许它只使用其左右的两个token就可以分析每个token的附近语境。它和RoBERTa一样经过预训练。
来源:https://analyticsindiamag.com/best-transformer-based-llms-on-huggingface-part-1/
自动编码模型
通过改变输入的token然后重建初始句子进行训练,自动编码模型遵循与原始Transformer模型的编码器类似的模式,可以在没有任何掩码的情况下访问完整的输入。这些模型创建出整个双向表示的句子,并可进一步完善,从而在文本生成等任务中发挥出色的性能。
不过,它们最适合用于句子或 token分类。下面是一些对它的应用。
BERT:用于语言理解的深度双向Transformer预训练
2018年,谷歌推出了BERT,在预训练阶段将随机性引入输入数据。通常情况下,15%的token会使用三种不同的概率进行屏蔽:使用特殊的掩码token的概率为0.8,使用非掩码token的随机token的概率为0.1,使用相同的token的概率为0.1。
该模型的主要任务是从被屏蔽的输入中预测原始句子。模型会得到两个句子A和B,中间有一个分隔token。这些句子在语料库中有50%的可能性是连续的,有50%的可能性是不相关的。该模型的第二个目标是预测句子是否连续。
ALBERT:用于语言表征自我监督学习的简易 BERT
Google Research和Toyota technology Institute的ALBERT类似于BERT,但做了一些修改,比如嵌入大小(E)不同于隐藏大小(H),因为嵌入是与语境无关的,而隐藏状态是与语境相关的,使得H >> E更符合逻辑。当E < H时,庞大的嵌入矩阵(V × E)导致参数较多。
此外,为节省内存,各层采用共享参数分组。ALBERT 采用了句子排序预测,而不是下一句预测,也就是给出两个连续的句子A和B作为输入,模型预测它们是否被交换过。
DistilBERT:精简版的BERT
Hugging Face通过简化创造了这个小版本的BERT,它可以像大的版本一样学习预测概率。它的目标是实现与参考模型相同的概率,正确预测掩码token,并保持与参考模型隐藏状态之间的相似性。
RoBERTa:鲁棒优化的BERT预训练方法
与BERT类似,RoBERTa引入了增强的预训练技术。一个值得注意的改进是动态掩蔽,其中token在每个训练时期被不同地掩蔽,而不像BERT的固定掩蔽。由Paul G Allen计算机科学与工程学院和华盛顿大学建立的模型消除了NSP损失,而是将连续文本块组合成512个token,可能跨越多个文档。
此外,在训练过程中使用更大的批量,提高了效率。最后,还使用了以字节为子单位的BPE来更有效地处理unicode字符。
XLM:跨语言的语言模型预训练
XLM由Meta构建,是另一种基于Transformer的多语言训练模型,有三种类型的训练:因果语言建模(CLM),掩码语言建模(MLM),以及MLM和翻译语言建模(TLM)。CLM和MLM涉及为每个训练样本选择一种语言,并处理可能跨越该语言多个文档的 256 个token的句子。
TLM将两种不同语言的句子与随机屏蔽结合起来,允许模型使用两种语境来预测被屏蔽的token。模型的检查点根据使用的预训练方法(CLM、MLM 或 MLM-TLM)命名,并将语言嵌入与位置嵌入结合起来,以判断训练期间所使用的语言。
XLM-RoBERTa:大规模的无监督跨语言表示学习
XLM-RoBERTa结合了RoBERTa技术和XLM,但不包括翻译语言建模。相反,它专注于单一语言句子中的屏蔽语言建模。该模型由Meta制作,在大量语言(100种)上进行训练,并具有识别输入语言的能力,而无需依赖语言嵌入。
ELECTRA:作为鉴别器而不是生成器的预训练文本编码器
斯坦福大学和谷歌开发了ELECTRA,这是一种特殊的Transformer模型,它通过利用一个较小的屏蔽语言模型来学习。这个较小的模型通过随机屏蔽某些部分来破坏输入文本,ELECTRA的任务是找出哪些token是原始的,哪些是替换的。
与GAN训练类似,较小的模型以原始文本为目标进行训练,而不是像传统GAN那样欺骗ELECTRA。之后,ELECTRA模型将在几个步骤中进行训练以提高其性能。
Longformer:长文档转换器
Allen人工智能研究所的Longformer是一个比传统模型更快的Transformer模型,因为它使用稀疏矩阵而不是密集矩阵。这允许它只使用其左右的两个token就可以分析每个token的附近语境。它和RoBERTa一样经过预训练。
来源:https://analyticsindiamag.com/best-transformer-based-llms-on-huggingface-part-1/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消