











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






ChatGPT是否足够聪明,可以不用言语解决问题?
2023年08月01日 由 daydream 发表
57079
0
一份最新的AI研究论文声称,深度学习模型具有某种微妙、未被认知的认知能力,甚至超越了人类。尽管研究人员发现现代预训练转换器模型在不一定需要语言的多项选择测试中表现良好,但他们仍然不知道人工智能是否只是基于其不透明的训练数据来获得答案。

加利福尼亚大学洛杉矶分校的研究人员对GPT-3大型语言模型进行了"类比任务"测试,发现它在解决复杂推理问题方面达到或超过了"人类能力"。洛杉矶分校在周一的新闻稿中对这项研究做出了颇具争议的声明,提出了AI是否在"使用一种根本上新的认知过程"的问题。
这是一个本质上带有偏见的问题,依赖于对人工智能系统的耸人听闻的观点。加州大学洛杉矶分校的心理学博士后研究员泰勒·韦布(Taylor Webb)以及教授基思·霍利奥克(Keith Holyoak)和陆宏静(Hongjing Lu)在《自然人类行为》期刊上发表了他们的论文。他们将AI的答案与40名本科生进行了比较,发现机器人的表现高于人类分数,甚至犯了一些同样的错误。
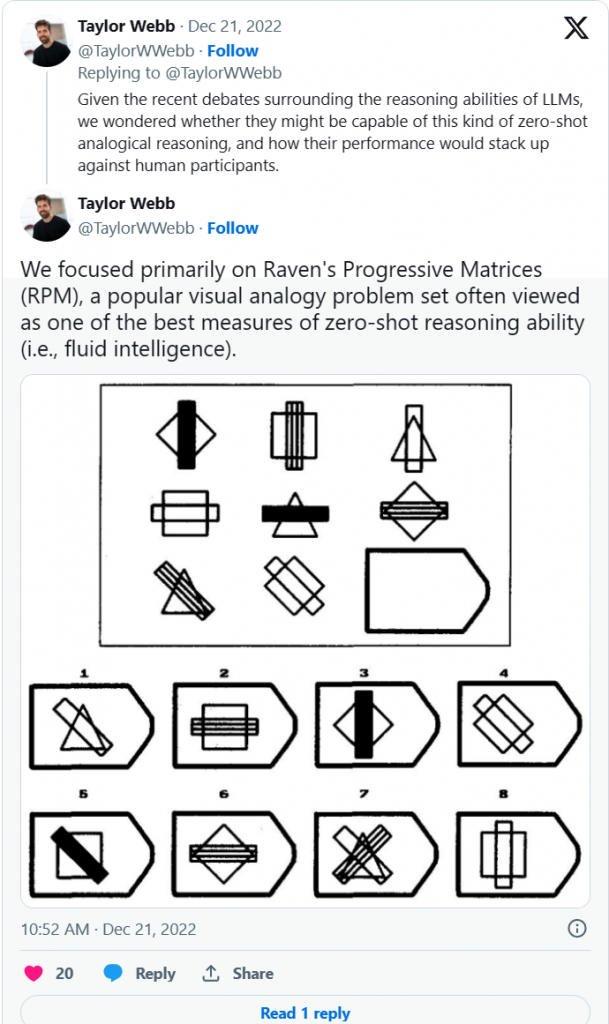
具体而言,研究人员基于一种名为Raven's Progressive Matrices的非语言测试进行了测试,这一测试开发于1939年。它是一个包含60个多项选择题的列表,随着题目的增加难度也逐渐增加,主要要求考试者识别出一种模式。有些人推断Raven's将智商作为一般认知能力的分数来衡量,特别是因为一些支持者表示,与其他固有偏见的智力测试相比,它没有太多的种族或文化偏见。
值得庆幸的是,这篇论文没有试图为AI指定一个虚假的智商分数。研究人员还要求该机器人解决一系列涉及词语对的SAT类比问题。例如,如果一个蔬菜与甘蓝相关联,那么昆虫相当于“甲虫”,依此类推。研究人员认为,据他们所知,这些问题没有出现在互联网上,因此GPT-3在训练数据中几乎不可能接触到这些问题。同样,AI的表现略高于普通人的水平。
AI在某些方面存在一些问题,或许它更像是一个理工科的学生而不是文科学生。它在基于短篇小说的类比问题上的解决能力要弱得多,尽管更新、范围更广的GPT-4在这方面做得更好。当被要求使用一堆家用物品将口香糖从一个房间转移到另一个房间时,AI给出了一些“奇特的解决方案”。
韦布和他的同事们已经研究这个问题近半年的时间,自从他们最初的预印本以来,他们还增加了更多的测试到模型中。所有这些测试使他们开始公开推测GPT-3可能正在形成一种类似于人类处理这类问题的“映射过程”。研究人员迅速接受了这样一个想法,即AI可能发展出了某种替代类型的机器智能。
这些测试中的“空间”部分通常涉及形状,并要求AI根据先前的类似形状猜测正确的形状或图表。研究人员进一步将其与血肉之躯的考试者作比较,并称AI与“人类类比推理”的许多相似特征。基本上,研究人员表示,AI的推理方式与人类相似,因为它具有对形状比较的感知能力。
韦布和他的同事们在去年12月首次发布了论文的预印本。在那里,研究人员声称GPT-3在这些测试或相关任务上“没有接受任何训练”。
有一个基本问题,即任何人都不可能声称AI没有接受过某种训练。在AI所使用的45个大型数据集中,是否可能完全没有与Raven's相关的语言内容呢?可能有,但GPT-3的创建者OpenAI并未发布LLM数据集中包含了哪些内容的完整列表。这是由于一些原因,其中之一是为了保护他们的专有AI,更好地销售他们的服务。第二个原因是为了防止更多的人因版权侵权而起诉他们。
此前,谷歌首席执行官桑达尔·皮查伊(Sundar Pichai)在一次采访中声称,谷歌的Bard聊天机器人自己学会了孟加拉语。然而研究人员发现,培训数据中已经存在孟加拉语和其他相关的语言。大部分AI数据集都以英语和“西方”为中心,但它的学习范围如此广泛,涵盖了如此广泛的信息,以至于有可能会包含一些无需语言解决问题的例子。
洛杉矶分校的新闻稿甚至提到,由于他们无法获取OpenAI的商业机密,研究人员对AI是如何以及为什么做出这些判断一无所知。类似这样的论文进一步加剧了有关AI是否具有某种实质“智能”的狂热。OpenAI的首席执行官一直长篇大论地谈到了对人工通用智能的担忧,这种类型的计算机系统是真正聪明的。但在实践中,这意味着什么还不太清楚。阿尔特曼在接受《大西洋》采访时将GPT-4描述为一种“外星智能”,并描述了AI编写电脑代码的情景,尽管它并未被明确程序化编写。
但这也是一种欺诈行为。阿尔特曼不会公开AI的训练数据,因为它是一个黑匣子,公司、AI支持者甚至善意的研究人员都可能会被声称语言模型正摆脱数字的围困而吸引。
来源:https://gizmodo.com/ucla-study-of-chatgpt-analogical-reasoning-1850693490
加利福尼亚大学洛杉矶分校的研究人员对GPT-3大型语言模型进行了"类比任务"测试,发现它在解决复杂推理问题方面达到或超过了"人类能力"。洛杉矶分校在周一的新闻稿中对这项研究做出了颇具争议的声明,提出了AI是否在"使用一种根本上新的认知过程"的问题。
这是一个本质上带有偏见的问题,依赖于对人工智能系统的耸人听闻的观点。加州大学洛杉矶分校的心理学博士后研究员泰勒·韦布(Taylor Webb)以及教授基思·霍利奥克(Keith Holyoak)和陆宏静(Hongjing Lu)在《自然人类行为》期刊上发表了他们的论文。他们将AI的答案与40名本科生进行了比较,发现机器人的表现高于人类分数,甚至犯了一些同样的错误。
具体而言,研究人员基于一种名为Raven's Progressive Matrices的非语言测试进行了测试,这一测试开发于1939年。它是一个包含60个多项选择题的列表,随着题目的增加难度也逐渐增加,主要要求考试者识别出一种模式。有些人推断Raven's将智商作为一般认知能力的分数来衡量,特别是因为一些支持者表示,与其他固有偏见的智力测试相比,它没有太多的种族或文化偏见。
值得庆幸的是,这篇论文没有试图为AI指定一个虚假的智商分数。研究人员还要求该机器人解决一系列涉及词语对的SAT类比问题。例如,如果一个蔬菜与甘蓝相关联,那么昆虫相当于“甲虫”,依此类推。研究人员认为,据他们所知,这些问题没有出现在互联网上,因此GPT-3在训练数据中几乎不可能接触到这些问题。同样,AI的表现略高于普通人的水平。
AI在某些方面存在一些问题,或许它更像是一个理工科的学生而不是文科学生。它在基于短篇小说的类比问题上的解决能力要弱得多,尽管更新、范围更广的GPT-4在这方面做得更好。当被要求使用一堆家用物品将口香糖从一个房间转移到另一个房间时,AI给出了一些“奇特的解决方案”。
韦布和他的同事们已经研究这个问题近半年的时间,自从他们最初的预印本以来,他们还增加了更多的测试到模型中。所有这些测试使他们开始公开推测GPT-3可能正在形成一种类似于人类处理这类问题的“映射过程”。研究人员迅速接受了这样一个想法,即AI可能发展出了某种替代类型的机器智能。
这些测试中的“空间”部分通常涉及形状,并要求AI根据先前的类似形状猜测正确的形状或图表。研究人员进一步将其与血肉之躯的考试者作比较,并称AI与“人类类比推理”的许多相似特征。基本上,研究人员表示,AI的推理方式与人类相似,因为它具有对形状比较的感知能力。
韦布和他的同事们在去年12月首次发布了论文的预印本。在那里,研究人员声称GPT-3在这些测试或相关任务上“没有接受任何训练”。
有一个基本问题,即任何人都不可能声称AI没有接受过某种训练。在AI所使用的45个大型数据集中,是否可能完全没有与Raven's相关的语言内容呢?可能有,但GPT-3的创建者OpenAI并未发布LLM数据集中包含了哪些内容的完整列表。这是由于一些原因,其中之一是为了保护他们的专有AI,更好地销售他们的服务。第二个原因是为了防止更多的人因版权侵权而起诉他们。
此前,谷歌首席执行官桑达尔·皮查伊(Sundar Pichai)在一次采访中声称,谷歌的Bard聊天机器人自己学会了孟加拉语。然而研究人员发现,培训数据中已经存在孟加拉语和其他相关的语言。大部分AI数据集都以英语和“西方”为中心,但它的学习范围如此广泛,涵盖了如此广泛的信息,以至于有可能会包含一些无需语言解决问题的例子。
洛杉矶分校的新闻稿甚至提到,由于他们无法获取OpenAI的商业机密,研究人员对AI是如何以及为什么做出这些判断一无所知。类似这样的论文进一步加剧了有关AI是否具有某种实质“智能”的狂热。OpenAI的首席执行官一直长篇大论地谈到了对人工通用智能的担忧,这种类型的计算机系统是真正聪明的。但在实践中,这意味着什么还不太清楚。阿尔特曼在接受《大西洋》采访时将GPT-4描述为一种“外星智能”,并描述了AI编写电脑代码的情景,尽管它并未被明确程序化编写。
但这也是一种欺诈行为。阿尔特曼不会公开AI的训练数据,因为它是一个黑匣子,公司、AI支持者甚至善意的研究人员都可能会被声称语言模型正摆脱数字的围困而吸引。
来源:https://gizmodo.com/ucla-study-of-chatgpt-analogical-reasoning-1850693490

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
GPT-3 ace 类比推理测试
下一篇
加快托管LLM推理速度的7种方法








广告


写评论取消
回复取消