


















Snowflake声称突破性技术可将AI推理时间缩短超过50%
Snowflake公司今天表示,它正在将技术集成到其托管的大型语言模型中,据称可以显著降低人工智能推理所需的成本和时间,即使用训练好的模型根据新输入数据进行预测或生成输出。

这种技术被称为SwiftKV,是一种由Snowflake AI研究团队开发的大型语言模型优化技术,并开源发布,通过基本上回收来自LLM早期层的称为隐藏状态的信息来提高推理过程的效率,以避免对后续层的键值缓存进行重复计算。
键值缓存就像语言模型的记忆捷径。它们存储关于输入文本的重要信息,因此模型在生成或处理更多文本时不必每次都重新计算。这使得模型更快更高效。
Snowflake表示,该技术可以将LLM推理吞吐量提高50%,并将开源Llama 3.3 70B和Llama 3.1 405B模型的推理成本降低多达75%,与不使用SwiftKV的运行相比。
公司最初将该技术与虚拟大型语言模型集成——这是一种涵盖端到端推理的独立但类似的技术——并在这两个Llama模型中提供。相同的优化将被添加到Snowflake Cortex AI中可用的其他模型系列中,这是Snowflake数据云平台中的一个功能,使企业能够直接在Snowflake中构建、部署和扩展AI和机器学习模型。然而,Snowflake没有具体说明支持其他模型的时间框架。
减少开销
通过避免冗余计算,SwiftKV减少了内存使用和计算开销,使解码更快更高效,特别是在实时AI应用中的自回归任务中。这些任务涉及一次生成一个标记——一个词或一个词的一部分——每个词都是基于先前生成的词进行预测的。该过程通常用于聊天机器人、实时翻译和文本生成等应用中,其中速度至关重要。
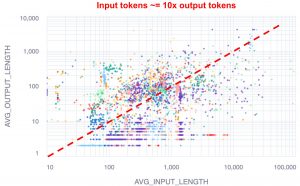 公司表示,SwiftKV的性能提升是基于大多数计算资源在输入或提示阶段被消耗的假设。许多业务任务使用长问题并生成短答案,这意味着大部分计算能力用于解释提示。Snowflake在其工程博客(右)上发布了一张分布图,显示典型的Snowflake客户工作负载包含的输入标记是输出标记的10倍。
公司表示,SwiftKV的性能提升是基于大多数计算资源在输入或提示阶段被消耗的假设。许多业务任务使用长问题并生成短答案,这意味着大部分计算能力用于解释提示。Snowflake在其工程博客(右)上发布了一张分布图,显示典型的Snowflake客户工作负载包含的输入标记是输出标记的10倍。
“SwiftKV不区分输入和输出,”Snowflake的AI研究团队负责人兼杰出软件工程师Yuxiong He说。“当我们启用SwiftKV时,模型的重新布线发生在输入处理和输出生成上。我们仅在输入处理上实现计算减少,也称为预填充计算。”
SwiftKV通过重用已完成的工作而不是重复相同的计算来节省时间,将额外步骤减少一半,同时准确性损失最小。它还使用一种称为“自蒸馏”的技巧来确保记住所有需要的内容,因此答案质量不会改变。在基准测试中,Snowflake表示看到准确性下降不到一个百分点。
“两者之间的质量差距非常小,”He说,“但如果客户特别关注这一领域,他们可以选择在Cortex AI中使用基础Llama模型。”
Snowflake表示,该技术在一系列用例中实现了性能优化。它提高了非结构化文本处理任务的吞吐量,如摘要、翻译和情感分析。在对延迟敏感的场景中,如聊天机器人或AI助手,SwiftKV将首次生成标记的时间——即模型生成并返回第一段输出所需的时间——减少多达50%。









