


















成为LLM工程师的终极路线图

作者提供的图片 | Ideogram
学习成为LLM工程师所需的知识技能对许多人来说听起来像是一项艰巨的任务,不仅因为它确实——说实话——不是最容易学习的东西,还因为很难决定从哪里开始以及如何构建你的学习旅程。
本文提供了一份全面的路线图,将复杂的拼图拼凑在一起,提供了一条清晰的学习路径,从基础的AI和机器学习(ML)到检索增强生成(RAG)方法,再到实际的LLM应用部署,帮助你成为一名熟练的LLM工程师。
让我们从基础开始,然后逐步从最基本的LLM工程主题转向更高级的主题,通过将整体路线图分为两个主要里程碑来进行渐进学习:
- LLM工程师路线图
- 高级LLM工程师路线图
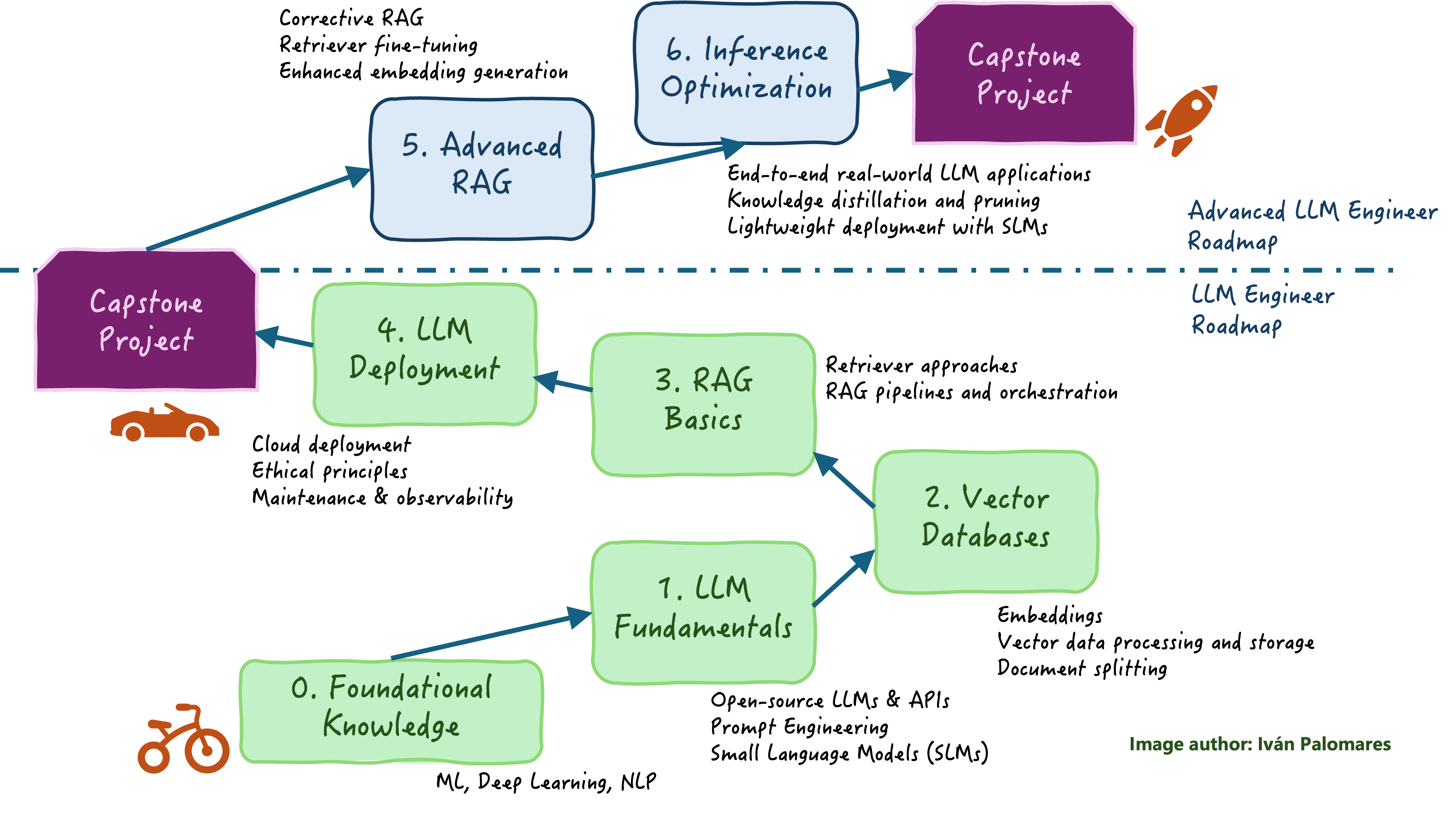
LLM工程师路线图
LLM工程师路线图
路线图的第一部分涵盖基础知识和技能,随后进入利用和部署简单的独立和基于RAG的LLM应用。
0. 基础知识
对于一些有AI/ML背景的准LLM工程师来说,这个“阶段零”可以跳过或用来刷新知识。如果你不是这种情况,请注意首先要掌握的基础知识,然后再深入研究LLM。
- 机器学习基础:了解监督和无监督模型,线性和非线性模型,梯度下降优化以构建从数据中学习的模型,以及评估ML模型的指标。
- 深度学习:神经网络架构,训练它们的反向传播过程,以及优化方法如优化器、批量归一化等。
- NLP基础:LLM本质上是自然语言处理(NLP)的最高体现。因此,学习NLP概念和关键过程以处理文本数据,如分词、嵌入、序列建模,以及理解LLM所基于的Transformer架构是至关重要的。
1. LLM基础
一种轻松沉浸于LLM的方法是使用LLM API,如OpenAI和Hugging Face,它们提供现成的预训练LLM供你玩耍和实验。同样,探索特定的开源模型如LLaMA,并利用小型语言模型(SLM)如DistilBERT和TinyBERT,以充分探索它们如何解决各种语言理解和生成任务。
2. 向量数据库
在接触LLM之后,为了为路线图的后续阶段做好准备,是时候学习关于向量数据库的一切了,即存储、管理和处理文本数据的高效表示如成千上万或数百万的文档。这是每个LLM系统的燃料,不仅在训练时学习执行语言任务,而且(正如我们将很快揭示的)在推理时尽可能有效地执行。在这个阶段,熟悉文档摄取和拆分技术,学习如何使用BERT和SentenceTransformers等模型构建文档嵌入,并学习如何实现向量数据库以进行语义搜索,使用FAISS或Pinecone等工具。
3. RAG基础
RAG已成为增强独立LLM性能的几乎不可或缺的工具,通过依赖从向量数据库检索的额外知识来源来改善对用户查询的回答。在这个阶段熟悉如LangChain和LlamaIndex等编排框架,优化检索器,以及构建提示模板,是构建简单RAG管道所需的关键技能。我们推荐理解RAG文章系列作为对当今LLM工程这一激动人心且基石部分的概念介绍。
4. LLM部署
为了结束这部分“不是那么基础”的路线图,让我们深入探讨与部署LLM相关的方面。学习如何在云环境中部署LLM如GCP或AWS,以及边缘环境;如何监控性能指标,检测错误和漂移以观察和维护已部署的模型,并接触伦理AI原则如偏见缓解和可解释性,这两者对于发布到现实世界的LLM至关重要。最后尝试使用迄今为止学到的工具组合部署一个基本或轻量级的语言模型(可能是SLM),如问答聊天机器人。这可以成为一个不错的里程碑项目。
高级LLM工程师路线图
这一部分深入探讨LLM微调、优化和高级LLM方法,最后提出一个里程碑项目,我们建议你创建一个更复杂、高性能的LLM应用,以巩固自己作为LLM工程专业人士的地位。
5. 高级RAG和LLM评估
这是深入研究高级RAG方法的合适时机,如校正和融合检索技术(过滤、重排序等),探索通过HyDE(假设文档嵌入)来构建增强嵌入或学习被称为“LLM作为裁判”的评估方法,以全面评估LLM输出超越常规指标。一种更好的评估LLM的方法。最后,探索检索器微调技术以适应特定领域的用例。
6. 推理优化
快完成了!在这一点上,你应该准备好完全沉浸在优化已部署LLM的高级机制中,如模型量化以减少模型的大小和延迟,知识蒸馏以在LLM上创建SLM,修剪方法以去除不必要的参数并提高效率(记住LLM通常有多达数十亿的参数!),并且总体上全面检查如何利用SLM以高效地部署轻量级解决方案。
总结
本文描述的LLM工程路线图旨在帮助学习者从基础到高级实践技能进行逻辑进步,从而获得动手经验以开发或处理现代LLM工具、应用和技术。
在行程结束时获得的知识之上,始终重要的是要理解在涉及LLM时需要考虑的许多权衡,例如通常与选择LLM或其简约对应物:SLM相关的性能-效率权衡。为高级阶段建议的学习内容旨在为你准备应对现实世界的挑战,从构建轻量级应用到在各种场景中扩展面向业务的LLM系统。









