


















新开源AI模型在性能上媲美DeepSeek,所需训练数据却大幅减少
来自领先学术机构和科技公司的国际研究团队于近期推出了一种新模型,颠覆了AI推理领域。该模型在性能上与中国最复杂的AI系统之一DeepSeek相媲美,甚至在某些情况下超越了它。

由开放思想联盟开发的OpenThinker-32B在MATH500基准测试中取得了90.6%的准确率,略高于DeepSeek的89.4%。
该模型在一般问题解决任务中也优于DeepSeek,在GPQA-Diamond基准测试中得分为61.6,而DeepSeek为57.6。在LCBv2基准测试中,它取得了68.9的稳固成绩,显示出在多样化测试场景中的强劲表现。
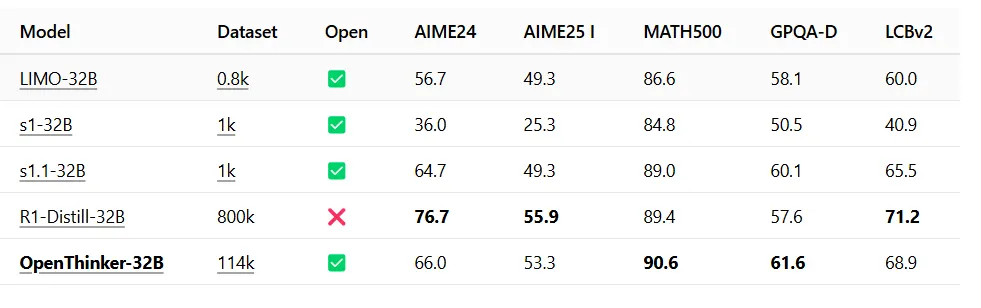
换句话说,它在一般科学知识(GPQA-Diamond)方面优于类似规模的DeepSeek R1版本。它在MATH500中击败了DeepSeek,但在AIME基准测试中落败——这两个测试都试图衡量数学能力。
在编码方面,它略逊于DeepSeek,得分为68.9对71.2,但由于该模型是开源的,一旦人们开始改进它,所有这些分数都可能大幅提高。
这一成就的独特之处在于其效率:OpenThinker仅需114,000个训练样本即可达到这些结果,而DeepSeek使用了800,000个。
该OpenThoughts-114k数据集为每个问题提供了详细的元数据:包括真实解决方案、代码问题的测试用例、必要时的起始代码以及领域特定信息。
其定制的Curator框架根据测试用例验证代码解决方案,而AI评审则负责数学验证。
团队报告称,他们使用了四个节点,每个节点配备八个H100 GPU,约90小时完成。另一个数据集包含137,000个未经验证的样本,在意大利的Leonardo超级计算机上训练,仅用30小时就消耗了11,520个A100小时。
“验证在扩大训练提示的多样性和规模的同时保持质量,”团队在其文档中指出。研究表明,即使是未经验证的版本也表现良好,尽管它们未能达到验证模型的最佳结果。
该模型基于阿里巴巴的Qwen2.5-32B-Instruct LLM构建,支持一个适度的16,000-token上下文窗口——足以处理复杂的数学证明和冗长的编码问题,但比当前标准要少得多。
此发布正值AI推理能力竞争加剧之际,这似乎正在以思维的速度发生。OpenAI在2月12日宣布所有后续GPT-5的模型将具备推理能力。一天后,埃隆·马斯克大力宣传xAI的Grok-3增强的问题解决能力,承诺它将成为迄今为止最好的推理模型,而就在几个小时前,Nous Research发布了另一个开源推理模型,DeepHermes,基于Meta的Llama 3.1。
在DeepSeek展示出与OpenAI的o1相当的性能后,该领域获得了动力,成本显著降低。DeepSeek R1可免费下载、使用和修改,其训练技术也已公开。
然而,与决定开源一切的开放思想不同,DeepSeek开发团队将其训练数据保密。
这一关键差异意味着开发人员可能更容易理解OpenThinker并从头开始重现其结果,因为他们可以访问所有的拼图。
对于更广泛的AI社区来说,这次发布再次证明了在没有大规模专有数据集的情况下构建竞争模型的可行性。此外,对于仍然不确定是否使用中国模型的西方开发者来说,它可能是一个更值得信赖的竞争者——无论是否开源。
OpenThinker可在HuggingFace下载。一个较小、功能较弱的7B参数模型也可用于低端设备。
开放思想团队汇集了来自不同美国大学的研究人员,包括斯坦福大学、伯克利大学和加州大学洛杉矶分校,以及德国的尤利希超级计算中心。美国的丰田研究院和欧盟AI领域的其他参与者也支持它。









