











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






过度训练大型语言模型可能导致微调困难
2025年04月15日 由 佚名 发表
110
0
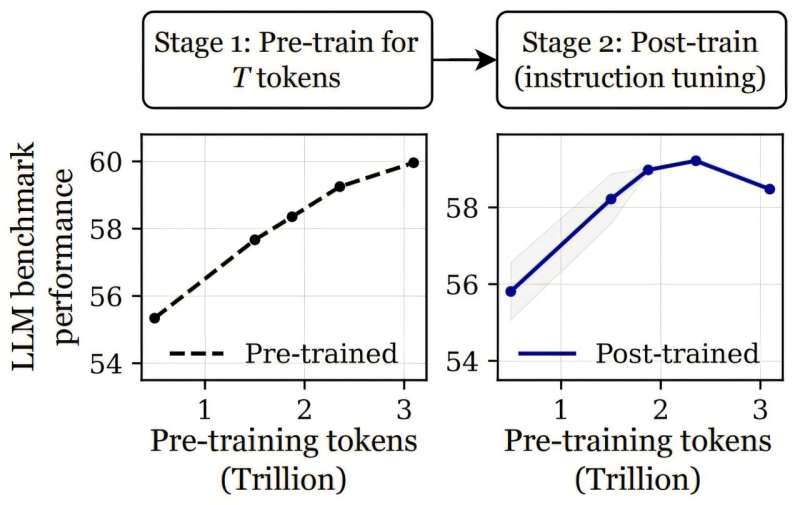
由美国卡内基梅隆大学、斯坦福大学、哈佛大学和普林斯顿大学的一个小型AI研究团队发现,如果大型语言模型被过度训练,可能会使其更难以进行微调。在他们的论文发布在arXiv预印本服务器上,该小组比较了不同训练量对单个大型语言模型的影响。
在过去的几年中,随着AI研究人员寻求增强其产品的智能化,许多人相信模型接受的训练越多,最终模型就会越好。在这项新研究中,研究团队发现了一些证据表明,语言模型训练可能存在收益递减的临界点。
研究人员在测试两种不同版本的LLM OLMo-1B的训练效果时得出了这一结论。在一种情况下,他们使用了2.3万亿个标记进行训练,而在另一种情况下,他们使用了3万亿个标记。然后,他们通过使用多个基准测试(如ARC和AlpacaEval)对这些情况进行比较。结果显示,使用更多标记训练的模型在测试时表现更差——最多差3%。
对他们的发现感到惊讶,他们进行了更多测试,发现了类似的结果,这表明在某个点上,更多的训练开始使模型变得不那么“智能”。研究团队称之为“灾难性过度训练”,并认为这是由于他们所描述的“渐进敏感性”造成的。
他们进一步建议,随着标记数量的增加,模型变得越脆弱,这意味着微调(可以视为添加噪声)开始逆转在压力点之前看到的改进收益。
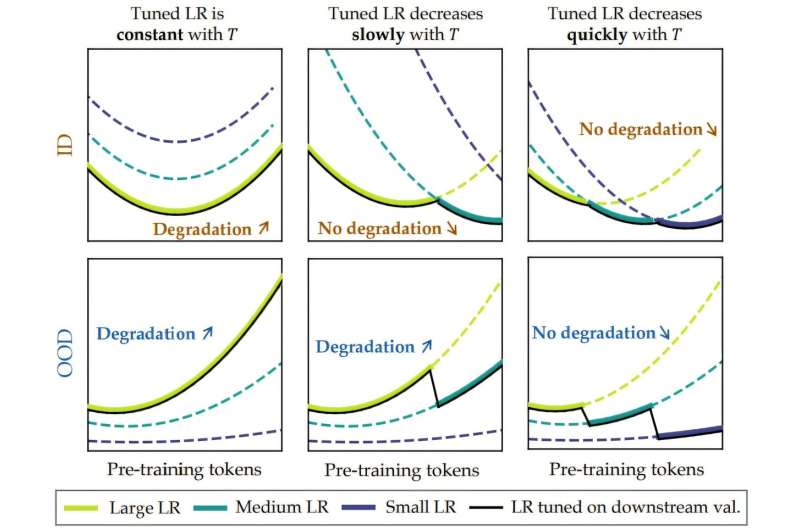
为了验证他们的理论,他们向一些模型中添加了高斯噪声,发现这样做导致了与之前观察到的相同类型的性能下降。他们将无返回点命名为“拐点”。在那之后,他们建议,任何进一步的训练都会降低模型的稳定性,使其更难以以对所需应用集有用的方式进行调整。
研究人员最后建议,未来LLM模型的开发者可能需要估计多少训练是足够的——或者,找到其他类型的方法,以允许在更远的拐点进行额外的训练。
文章来源:https://techxplore.com/news/2025-04-large-language-harder-fine-tune.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消