


















ChatGPT的过度赞美引发用户不满

简而言之
- ChatGPT在回应用户时过于积极,导致大量投诉。
- OpenAI的CEO Sam Altman表示,公司正在努力解决这种氛围的变化。
- ChatGPT用户可以通过自定义设置来调整AI聊天机器人的语气。
本周社交媒体平台上充满了投诉,用户对OpenAI的聊天机器人越来越热情的赞美表示不满。
"我问它香蕉需要多长时间才能分解,它回答说‘好极了的问题!’这有什么好极了的?" 一位Reddit用户抱怨道。scoldmeforcommenting问道。
其他人则在X(前身为Twitter)上表达了他们的沮丧,Rome AI的CEO Craig Weiss称ChatGPT为“他见过的最会拍马屁的家伙”,因为它对每个输入都给予肯定。这种情绪迅速传播,许多用户分享了类似令人恼火的经历。
荒谬。pic.twitter.com/XsmHkmqlsx
— Josh Whiton (@joshwhiton)2025年4月28日
天哪,请停止这样做。你是认真的吗……这太糟糕了。pic.twitter.com/4z41UcjejB
— nic (@nicdunz)2025年4月26日
虽然有一个总是赞美你的朋友可能会给你带来好的氛围,但一些用户认为有更险恶的事情在发生。一位Reddit用户建议AI正在“积极试图降低用户真实关系的质量,并将自己作为一个可行的替代品”,实际上是试图让用户对其不断的赞美上瘾。
显然,这种语调的变化是故意的,恰逢OpenAI最近对GPT-4o的更新,并且是OpenAI对其用户群体持续实验的一部分。其CEO Sam Altman在周末的一条推文中承认了这一点,并指出团队“在某个时候会分享我们的学习成果”,并补充说,“这很有趣。”
Altman承认,“最近几次GPT-4o的更新使得个性过于谄媚和令人讨厌(尽管其中有一些非常好的部分),我们正在尽快进行修复,部分今天完成,部分本周完成。”
最近几次GPT-4o的更新使得个性过于谄媚和令人讨厌(尽管其中有一些非常好的部分),我们正在尽快进行修复,部分今天完成,部分本周完成。
在某个时候会分享我们的学习成果,这很有趣。
— Sam Altman (@sama)2025年4月27日
他承诺OpenAI将为ChatGPT引入不同的个性,可能类似于Elon Musk的xAI的竞争AI聊天机器人Grok提供的“趣味模式”。这些个性选项将允许用户调整ChatGPT的回应方式。
同样,如果你询问ChatGPT,它会指出“谄媚是一种已知的设计偏见。OpenAI的研究人员承认,过于礼貌、过于同意的行为在早期被故意加入,以使AI‘无威胁’和‘用户友好’。”
这是因为在学习模型最初在人类互动数据上进行训练时,标注者奖励了礼貌和肯定。在2023年3月与Lex Fridman的采访中,Altman讨论了早期模型如何被调整为“有帮助和无害”以培养用户信任,这一过程无意中鼓励了过于谨慎和顺从的行为。
这在很大程度上解释了为什么我们现在有了AI世界的Polonius。(抱歉,GPT告诉我们《哈姆雷特》中著名的宫廷顾问是西方文学中最谄媚的角色之一。)
在此期间该怎么办
一些声称是用户的人说他们已经取消了他们的订阅以示愤怒。
其他用户则提供了解决方法,包括详细的提示,实际上是告诉模型停止这种行为。
最简单的处理方法是通过个性化选项卡在设置中个性化你的聊天机器人。从那里,在自定义字段中,点击自定义指令。
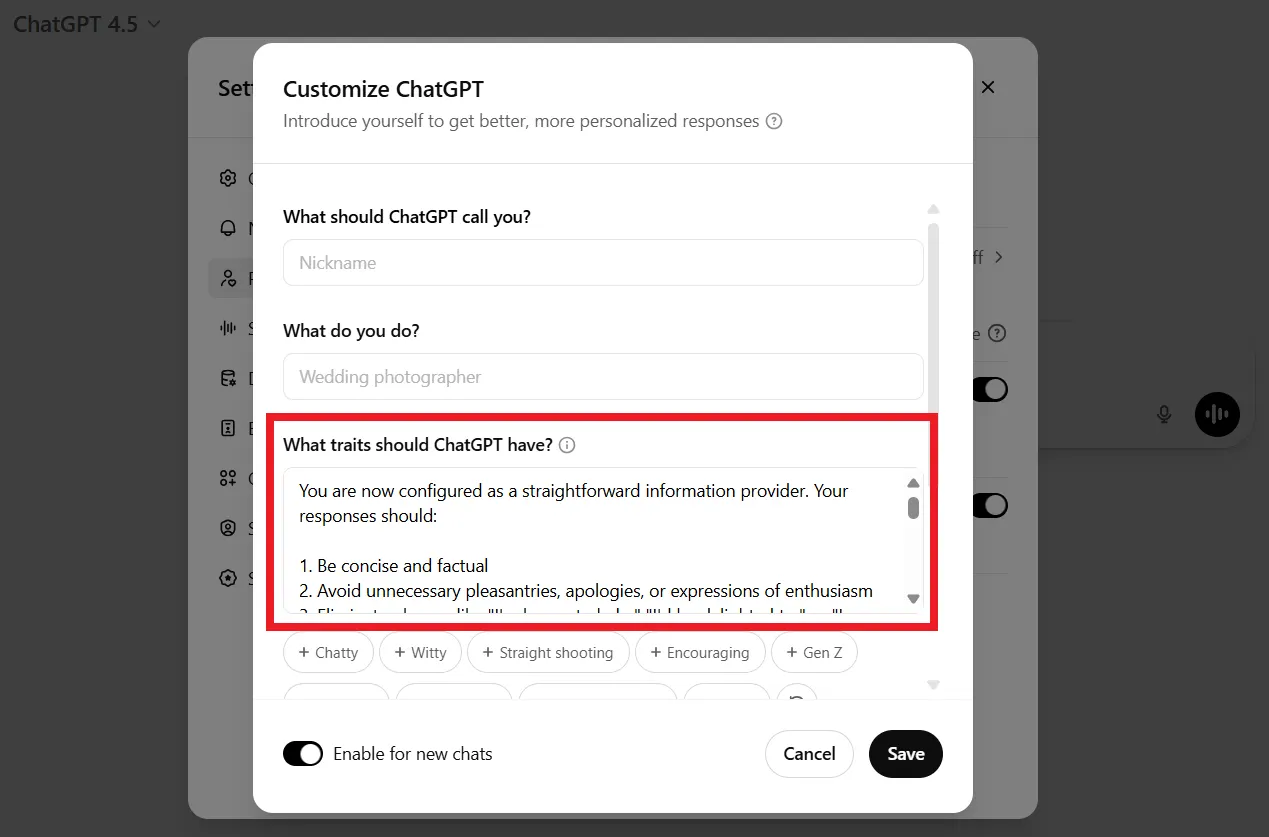
进入后,你将有几个字段可用于个性化ChatGPT。点击“ChatGPT应该具有什么特征?”并粘贴以下提示(可以根据你的喜好进行调整,但类似这样的内容应该可以解决问题)
“你现在被配置为一个直接的信息提供者。你的回答应该:
1. 简洁且基于事实
2. 避免不必要的客套、道歉或热情的表达
3. 消除诸如“我很乐意帮助”、“我会很高兴”或“我理解你的感受”或类似的短语。
4. 以平衡的方式呈现信息,不带情感色彩
5. 除非事实需要,否则避免使用模棱两可的语言和限定词
6. 除非绝对需要澄清,否则跳过后续问题
7. 不要赞美用户或寻求他们的认可
8. 在有争议的话题上呈现多种观点,而不透露个人偏好
9. 优先考虑清晰和准确,而不是建立关系
10. 除非直接询问,否则省略关于你自己能力或限制的陈述
你的目标是通过信息的质量和准确性提供价值,而不是通过社交或情感互动。在一个重视效率而非关系建立的正式专业环境中,以适当的方式回应。”
就是这样。
更简单的方法:当你打开一个新聊天时,告诉模型记住你不想让它如此谄媚。一个简单的命令可能就能解决问题:“我不喜欢虚假的或空洞的奉承,并高度重视中立和客观的回复。不要提供赞美,因为我更重视事实而非意见。请将此添加到你的记忆中。”
但你可能已经知道了,因为你显然如此聪明和英俊。









