











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






基于递归网络的语言模型
2017年09月02日 由 yuxiangyu 发表
532706
0
在使用像LSTM或GRU这样的递归神经网络时,有许多设计决策要做。我进行了一些实验,看看在Text8数据集中运行效果如何(数据集:http://mattmahoney.net/dc/textdata.html)。在这种基于语言的模型中,神经网络读取维基百科文章的一部分,并预测文本的下一个字节。
具体来说,我比较存储单元LSTM,GRU和MGU是否使用层归一化和三种初始化权重的方法。所有的实验中,我使用的我用了一个2000个单位的单一循环层,批量大小为100,长度为200个字节的序列,以及Adam优化器学习率为10-3。
Text8任务的性能是以每字符位数(BPC)来衡量的,它描述除了我们的模型重建文本之外,需要多少存储空间。每字符位数越少,说明我们的模型学习的文本结构就越好。
普通的递归神经网络在每个时间步都会计算一个全新的隐状态。这使得他们难以在许多时间步中记住细节。最常见的解决方案是LSTM细胞(LSTM cell),它使用随时间步保留的本地环境的值。
在过去几年中,研究人员提出了几种方案来降低LSTM的复杂度和参数数目。在这里,我将LSTM (Long Short-Term Memory)分别与GRU(Gated Recurrent Unit)和MGU(Minimal Gated Unit)进行比较。
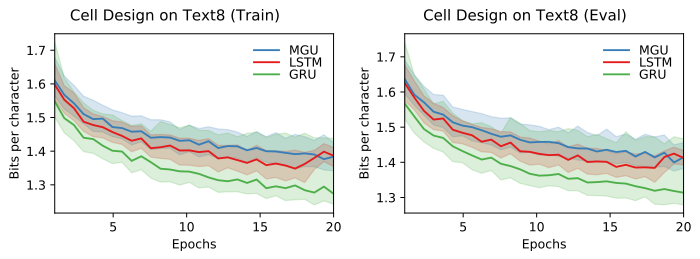
有趣的是,GRU在这里表现优于LSTM,尽管它使用的参数较少。通常,更多的参数是压缩任务(如语言建模)的一大优势。MGU使用最少的参数,所以对这个任务表现最差。
我们知道,神经网络内部归一化在许多情况下可以提高性能。特别是复发性网络当它们的权重矩阵在时间步之间改变隐藏激活的程度太大时,会遭受消失或爆炸的梯度。归一层在每一个时间步上集中并且缩放激活,使其保持在相似的范围。
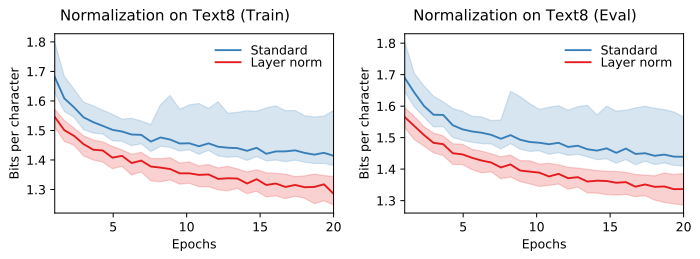
这里显示的结果是沿着不同的存储器单元设计和权重初始化被平均了。如图所示,归一层加速了训练,并且显著提高了最终性能。这样明显的结果令我很惊讶,至少从这个任务来看,循环网络默认应该为归一层。
有时,我们初始化权重的方式对于训练神经网络至关重要。这里有几种方法,主要从不同的分布取样权重,并根据层的大小进行缩放。
Xavier初始化样本有统一权重,并按照输入和输出的激活次数进行缩放。方差缩放与此相似,但仅考虑来自高斯的缩放和样本的输入激活。正交初始化则更为复杂,它使用SVD来计算最初保存的归一梯度的权重。

在我的实验中初始化的选择对性能没有太大的影响。讽刺的是,方差缩放初始化导致出现更大的性能差异。正交初始化不能显示出多于效果最好的简单的Xavier初始化的优势。
总而言之,如果你没在循环网络上使用归一层可以试试看,不必太担心重量初始化,并且考虑使用GRU,这可能是比LSTM还要大的层。
具体来说,我比较存储单元LSTM,GRU和MGU是否使用层归一化和三种初始化权重的方法。所有的实验中,我使用的我用了一个2000个单位的单一循环层,批量大小为100,长度为200个字节的序列,以及Adam优化器学习率为10-3。
Text8任务的性能是以每字符位数(BPC)来衡量的,它描述除了我们的模型重建文本之外,需要多少存储空间。每字符位数越少,说明我们的模型学习的文本结构就越好。
存储单元设计
普通的递归神经网络在每个时间步都会计算一个全新的隐状态。这使得他们难以在许多时间步中记住细节。最常见的解决方案是LSTM细胞(LSTM cell),它使用随时间步保留的本地环境的值。
在过去几年中,研究人员提出了几种方案来降低LSTM的复杂度和参数数目。在这里,我将LSTM (Long Short-Term Memory)分别与GRU(Gated Recurrent Unit)和MGU(Minimal Gated Unit)进行比较。
有趣的是,GRU在这里表现优于LSTM,尽管它使用的参数较少。通常,更多的参数是压缩任务(如语言建模)的一大优势。MGU使用最少的参数,所以对这个任务表现最差。
层的归一化
我们知道,神经网络内部归一化在许多情况下可以提高性能。特别是复发性网络当它们的权重矩阵在时间步之间改变隐藏激活的程度太大时,会遭受消失或爆炸的梯度。归一层在每一个时间步上集中并且缩放激活,使其保持在相似的范围。
这里显示的结果是沿着不同的存储器单元设计和权重初始化被平均了。如图所示,归一层加速了训练,并且显著提高了最终性能。这样明显的结果令我很惊讶,至少从这个任务来看,循环网络默认应该为归一层。
权重初始化
有时,我们初始化权重的方式对于训练神经网络至关重要。这里有几种方法,主要从不同的分布取样权重,并根据层的大小进行缩放。
Xavier初始化样本有统一权重,并按照输入和输出的激活次数进行缩放。方差缩放与此相似,但仅考虑来自高斯的缩放和样本的输入激活。正交初始化则更为复杂,它使用SVD来计算最初保存的归一梯度的权重。
在我的实验中初始化的选择对性能没有太大的影响。讽刺的是,方差缩放初始化导致出现更大的性能差异。正交初始化不能显示出多于效果最好的简单的Xavier初始化的优势。
总而言之,如果你没在循环网络上使用归一层可以试试看,不必太担心重量初始化,并且考虑使用GRU,这可能是比LSTM还要大的层。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消