











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






怎样在Python的深度学习库Keras中使用度量
2017年09月04日 由 yuxiangyu 发表
26882
0
Keras库提供了一种在训练深度学习模型时计算并报告一套标准度量的方法。
除了提供分类和回归问题的标准度量外,Keras还允许在训练深度学习模型时,定义和报告你自定义的度量。如果你想要跟踪在训练过程中更好地捕捉模型技能的性能度量,这一点尤其有用。
在本教程中,你将学到在Keras训练深度学习模型时,如何使用内置度量以及如何定义和使用自己的度量。
完成本教程后,你将知道:
- Keras度量的工作原理,以及如何在训练模型时使用它们。
- 如何在Keras中使用回归和分类度量,并提供实例。
- 如何在Keras中定义和使用你自定义的度量标准,并提供实例。
让我们开始吧。

教程概述
本教程分为4部分,分别是:
- Keras的度量
- Keras回归度量
- Keras分类度量
- Keras自定义度量
Keras的度量
Keras允许你列出在你的模型训练期间监控的度量。
你可以通过在模型上指定“ metrics ”参数并提供函数名称列表给compile()函数实现这一点。
例如:
model.compile(..., metrics=['mse'])
你列出的特定带的度量可以是Keras函数的名称(如mean_squared_error)或这些函数得字符串别名(如“ mse ”)。
度量的值在训练数据集上每个周期结束时记录。如果还提供验证数据集,那么也为验证数据集计算度量记录。
所有度量都以详细输出和从调用fit()函数返回的历史对象中报告。在这两种情况下,度量函数的名称都用作度量值的密匙。在这种情况下对于验证数据集来说度量将“ val_ ”前缀添加到密钥。
损失函数和明确定义的Keras度量都可以用作训练度量。
Keras回归度量
以下是你可以在Keras中使用回归问题的度量列表。
- 均方误差:mean_squared_error,MSE或mse
- 平均绝对误差:mean_absolute_error,MAE,mae
- 平均绝对百分比误差:mean_absolute_percentage_error,MAPE,mape
- 余弦距离: cosine_proximity, cosine
下面的示例在简单的回归问题上演示了这些4个内置的回归度量。
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# prepare sequence
X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
# create model
model = Sequential()
model.add(Dense(2, input_dim=1))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam', metrics=['mse', 'mae', 'mape', 'cosine'])
# train model
history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2)
# plot metrics
pyplot.plot(history.history['mean_squared_error'])
pyplot.plot(history.history['mean_absolute_error'])
pyplot.plot(history.history['mean_absolute_percentage_error'])
pyplot.plot(history.history['cosine_proximity'])
pyplot.show()
运行实力打印每个周期结束的度量值
...
Epoch 96/100
0s - loss: 1.0596e-04 - mean_squared_error: 1.0596e-04 - mean_absolute_error: 0.0088 - mean_absolute_percentage_error: 3.5611 - cosine_proximity: -1.0000e+00
Epoch 97/100
0s - loss: 1.0354e-04 - mean_squared_error: 1.0354e-04 - mean_absolute_error: 0.0087 - mean_absolute_percentage_error: 3.5178 - cosine_proximity: -1.0000e+00
Epoch 98/100
0s - loss: 1.0116e-04 - mean_squared_error: 1.0116e-04 - mean_absolute_error: 0.0086 - mean_absolute_percentage_error: 3.4738 - cosine_proximity: -1.0000e+00
Epoch 99/100
0s - loss: 9.8820e-05 - mean_squared_error: 9.8820e-05 - mean_absolute_error: 0.0085 - mean_absolute_percentage_error: 3.4294 - cosine_proximity: -1.0000e+00
Epoch 100/100
0s - loss: 9.6515e-05 - mean_squared_error: 9.6515e-05 - mean_absolute_error: 0.0084 - mean_absolute_percentage_error: 3.3847 - cosine_proximity: -1.0000e+00
接着,创建4个度量在训练周期的折线图。
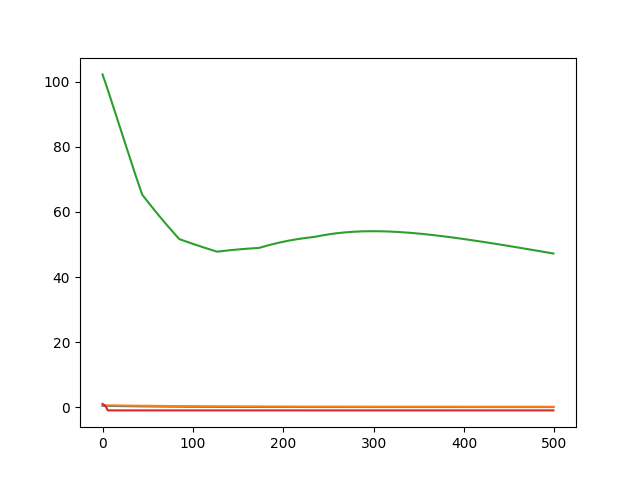
请注意,度量使用字符串别名值[‘mse’,‘mae','‘mape',‘cos']指定,并使用扩展函数名称将其作为历史对象的键值引用。
我们还可以使用扩展名指定度量,如下所示:
model.compile(loss='mse', optimizer='adam', metrics=['mean_squared_error', 'mean_absolute_error', 'mean_absolute_percentage_error', 'cosine_proximity'])
或者你也可以使用损失函数作为度量
例如,您可以使用均方对数误差(mean_squared_logarithmic_error,MSLE或msle)损失函数作为度量,如下所示:
model.compile(loss='mse', optimizer='adam', metrics=['msle'])
Keras分类度量
以下是可以在Keras中使用的关于分类问题的度量列表。
- 二进制精度:binary_accuracy,
- 分类准确度:categorical_accuracy, acc
- 稀疏分类精度:sparse_categorical_accuracy
- top k分类精度:top_k_categorical_accuracy(需要指定一个k参数)
- 稀疏Top k分类精度:sparse_top_k_categorical_accuracy(需要指定一个k参数)
精度是指定好的。
无论你的问题是二进制还是多分类问题,都可以指定“ acc ”度量来报告精度。
下面是一个内置的精度度量演示的二进制分类问题的示例。
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# prepare sequence
X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
y = array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
# create model
model = Sequential()
model.add(Dense(2, input_dim=1))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# train model
history = model.fit(X, y, epochs=400, batch_size=len(X), verbose=2)
# plot metrics
pyplot.plot(history.history['acc'])
pyplot.show()
运行这个示例,在每个周期结束时记录精度
...
Epoch 396/400
0s - loss: 0.5934 - acc: 0.9000
Epoch 397/400
0s - loss: 0.5932 - acc: 0.9000
Epoch 398/400
0s - loss: 0.5930 - acc: 0.9000
Epoch 399/400
0s - loss: 0.5927 - acc: 0.9000
Epoch 400/400
0s - loss: 0.5925 - acc: 0.9000
创建一个精度的折线图。
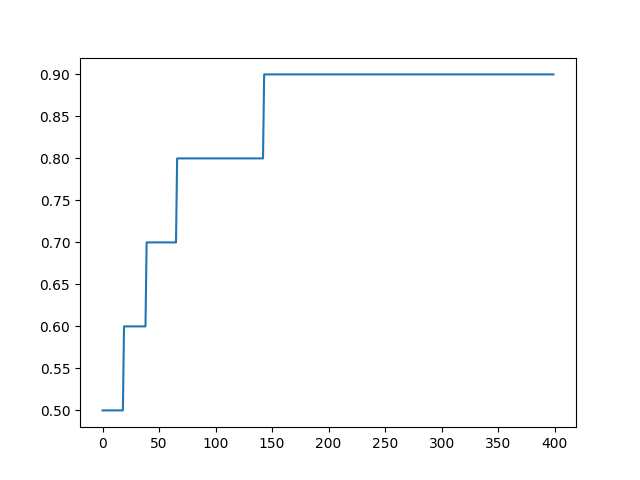
自定义Keras的度量
你还可以定义自己的度量并且在为“metrics”参数调用compile()函数时在函数列表中指定函数名。
我通常喜欢跟踪的度量是RMSE(均方根误差)。
你可以通过检查现有度量的代码来了解如何编写自定义的度量。
例如,下面是Keras中mean_squared_error损失函数和度量的代码。
def mean_squared_error(y_true, y_pred):
return K.mean(K.square(y_pred - y_true), axis=-1)
K是Keras使用的后端。
在该示例、其他的损失函数示例和度量中,这个方法是在后端使用标准数学函数来计算兴趣度量。
例如,我们可以编写一个自定义度量来计算RMSE,如下所示:
from keras import backend
def rmse(y_true, y_pred):
return backend.sqrt(backend.mean(backend.square(y_pred - y_true), axis=-1))
你可以看到函数与添加了sqrt()包含结果的代码MSE相同。
我们可以在我们的回归示例中进行如下测试。请注意,我们只是直接列出了函数名,而不是将其作为Keras的字符串或别名来解决。
from numpy import array
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
from keras import backend
def rmse(y_true, y_pred):
return backend.sqrt(backend.mean(backend.square(y_pred - y_true), axis=-1))
# prepare sequence
X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
# create model
model = Sequential()
model.add(Dense(2, input_dim=1, activation='relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam', metrics=[rmse])
# train model
history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2)
# plot metrics
pyplot.plot(history.history['rmse'])
pyplot.show()
运行示例记录每个训练周期结束时自定义的RMSE度量。
...
Epoch 496/500
0s - loss: 1.2992e-06 - rmse: 9.7909e-04
Epoch 497/500
0s - loss: 1.2681e-06 - rmse: 9.6731e-04
Epoch 498/500
0s - loss: 1.2377e-06 - rmse: 9.5562e-04
Epoch 499/500
0s - loss: 1.2079e-06 - rmse: 9.4403e-04
Epoch 500/500
0s - loss: 1.1788e-06 - rmse: 9.3261e-04
在运行结束时,创建自定义RMSE度量的折线图。
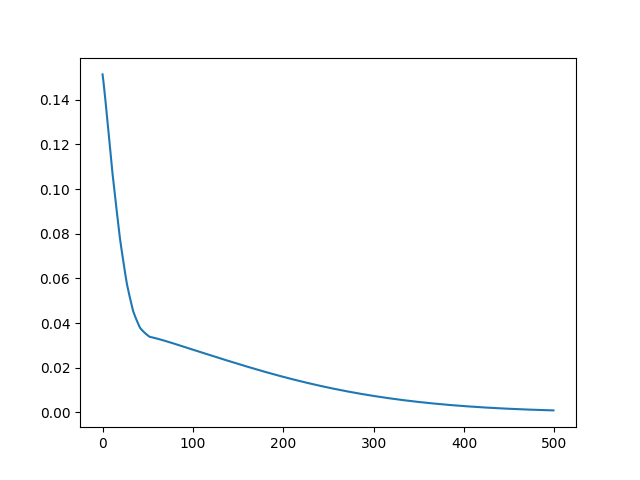
你自定义度量函数必须对Keras内部数据结构进行操作,这些内部数据结构可能会因使用的后端不同而有所差别(例如,在使用tensorflow时为tensorflow.python.framework.ops.Tensor),而不是直接使用原始yhat值和y值。
因此,我建议尽可能使用后端数学函数来保持一致性和执行速度。
拓展阅读
如果你想学的更多,可以访问以下的资源。
- Keras度量API文档:https://keras.io/metrics/
- Keras度量源代码:https://github.com/fchollet/keras/blob/master/keras/metrics.py
- Keras Loss API文档:https://keras.io/losses/
- Keras Loss 源代码:https://github.com/fchollet/keras/blob/master/keras/losses.py
总结
在本教程中,你已经学会如何在训练深度学习模型时使用Keras度量。
具体来说,你学到了:
- Keras度量如何原理,以及如何配置模型以在训练期间报告度量。
- 如何使用Keras内置的分类和回归度量。
- 如何有效地定义和报告自定义度量,同时训练的深度学习模型。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消