











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






利用深度学习改变位置感知计算
2017年09月04日 由 xiaoshan.xiang 发表
926189
0
位置感知位于定位服务(LBS)的核心位置。然而,准确地估计目标的位置并不那么简单。全球定位系统(GPS),可以直接输出地理空间坐标,但它的错误可能远远超出了某些应用的容许度。在GPS定位区域,可以通过惯性测量单元(imu)和照相机等传感器提供的原始数据间接推断出位置。通常,数据,无论是直接测量地理空间坐标还是推断位置,都必须经过相当费力的人工数据处理管道,才能被高水平的LBS所消耗。本文回顾了最近两项关于将深度学习模型引入位置感知计算的尝试,有效地减少了专家的参与。
https://arxiv.org/abs/1602.00991
https://www.youtube.com/watch?v=cdeWCpfUGWc&feature=youtu.be
这篇AAAI16论文提出了一种端到端对象跟踪方法,其中一端是模拟2D激光扫描仪收集的原始数据,另一端是整个环境状态,甚至包括遮挡的对象,如下图所示:
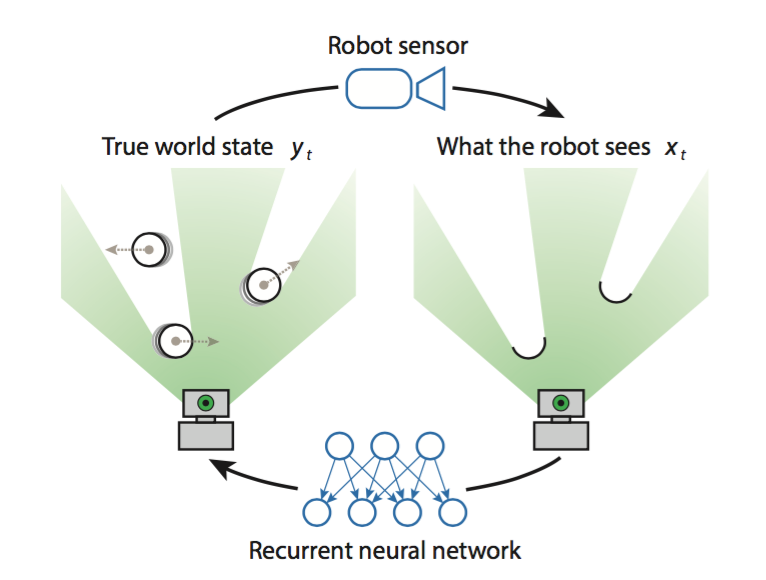
在这个跟踪问题背后,值得关注的是,由于遮挡,原始数据只能捕获环境的一部分。类似于局部可观察的随机过程的问题,传统上由贝叶斯滤波(如卡尔曼滤波)解决,反过来又涉及到许多手工设计的状态表示,并隐含着对模型分布的某些假设或抽样。这篇论文提出了第一个端到端可训练的解决方案,使机器人代理能够在无监督的情况下学习置信状态表示,以及相应的预测和更新操作,使其与传统方法相比更加有效省力。
跟踪问题被认为是一种生成模型,包括一个详细描述环境动态的隐马尔可夫过程h。与此同时,它的外观层y捕捉到单个物体的位置,并且可以通过第三层,即传感器测量x的层进行部分观察,如下图所显示的
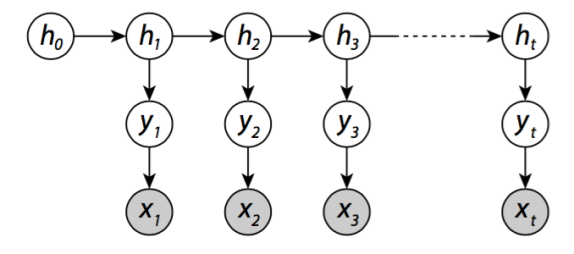
目标在给定x的历史输入序列中估计y的条件分布。注意y实际上不是马尔可夫过程,因此,隐藏马尔可夫模型等方法不能在这里应用。或者,这可以通过递归的贝叶斯估计来处理,在给定历史输入序列x(信念)的情况下,递归计算h的条件分布。目标可以估计为y的可信度的条件分布。这篇论文通过两个神经网络权重W_F 和W_P表达的最终目标,同时第一个网络指定了历史输入序列到可信度的模型,第二网络指定从可信度到位置(y at t)的模型。两个网络链接在一起,有效地使它们成为一个整体的前馈循环神经网络。该信任度的隐藏状态表示是从原始数据中学习的,并作为网络的内存从一个时间步骤传递到下一个。过滤过程如下图所示:
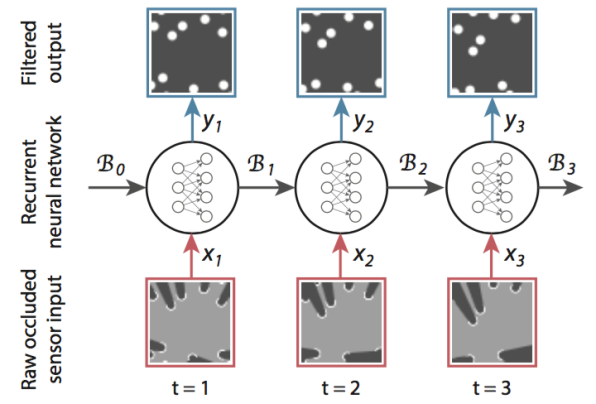
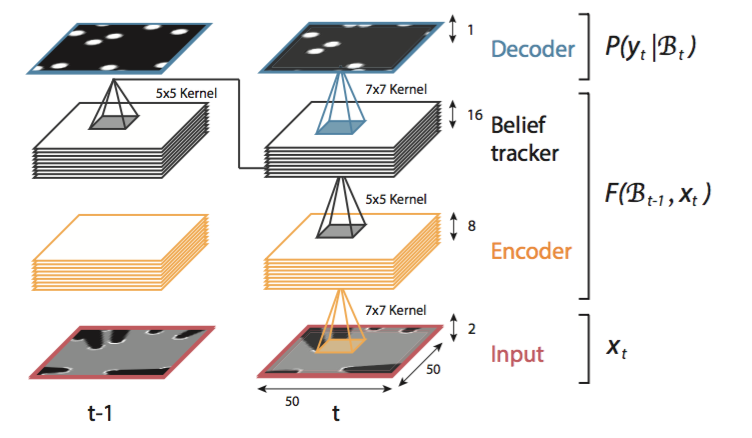
更具体地说,作者使用一个带有卷积运算的四层前馈循环网络,然后是每个层的sigmoid激活。网络的架构如下:
上述模型可以以常规方法训练,以尽量减少目标分布的负对数概度。然而,由于遮挡,y的地面实况数据可能无法访问。作者提出,通过删除当前时间步骤和当前n步骤(将其设置为0)之间的所有的观察,从而对网络进行训练,这样不仅可以预测下一个步骤,而且还可以预测未来进行更多的步骤(例如n步)。观察漏失必须在所有数据集中进行空间和时间上的执行,以避免过度拟合。这使得网络可以在没有地面实况数据的情况下进行训练,这是一种相对无监督的方式。
训练集的总数量为1万个序列,长度为2000时间步骤。随机梯度下降训练5万次。有两个重要的发现:首先,无监督的训练结果与监督式学习结果几乎相同,表明观察漏失是有效的。第二,可信度层的激活显示了不同对象移动模式的适应表现。训练的进度可以在下面看到,也可以通过原创论文的附加视频看到(视频链接地址https://www.youtube.com/watch?v=cdeWCpfUGWc&feature=youtu.be)。
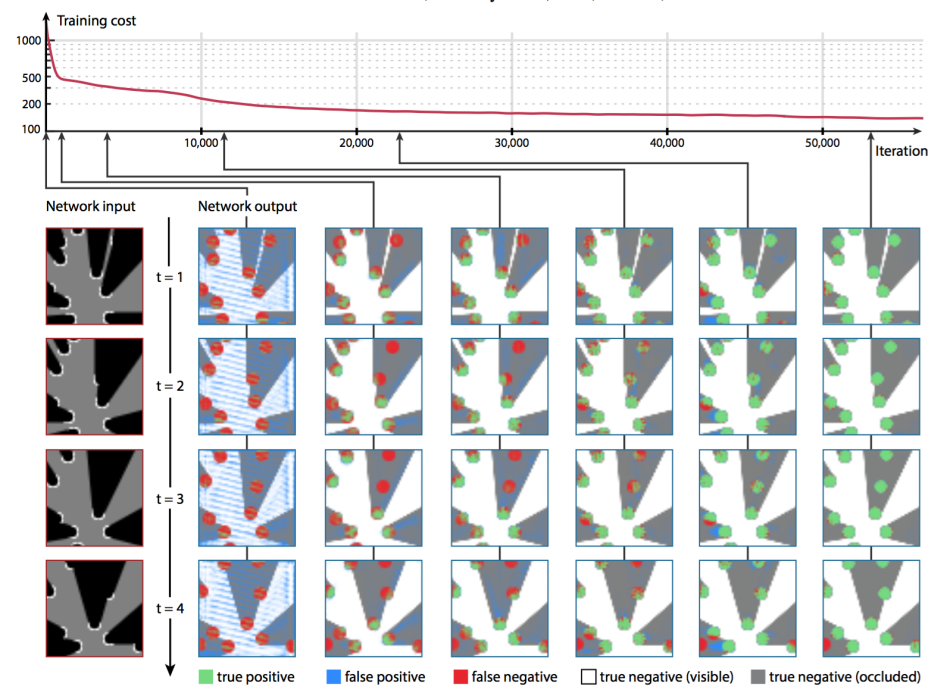
然而,可能是由于它是首个该类型的模型,作者没有提供任何量化的度量标准来表现或比较现有的作品。最后,根据作者的说法,它们正在把这篇文章扩展到更真实的数据和更具挑战性的机器人任务上。
https://launchpad.ai/blog/tracking
最近Launchpad发布了一篇博客文章。人工智能将长期短时记忆(LSTM)引入到运输操作中。对于许多工业和室外应用来说,GPS和射频识别(RFID)跟踪技术现在很普遍,因为它们能捕捉到精确到米级的实时位置信息。然而,如何转化地理空间数据来改善操作过程是一个不容易理解的话题。作者提出了一种自动化的地理空间异常检测系统,该系统通过对被跟踪对象是否偏离预期轨迹来进行评估。利用LSTM网络从历史数据中学习。该系统被应用于一个真实的“数据集”(链接地址为http://sensor.ee.tsinghua.edu.cn/datasets.html),它包括北京28000辆出租车的一个月的轨迹。
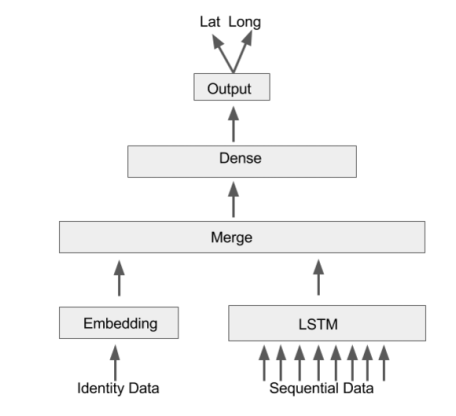
另外,时间标记和出租车的对应位置(纬度和经度)、速度、方位和占用状态也被规范化和分解成顺序数据。顺序数据将由LSTM网络处理。作者还考虑了该对象的身份信息。身份信息(本例中唯一的驱动ID)首先通过嵌入进行预处理,然后与LSTM输出合并。在某种程度上,驱动ID的语义暗示可以判断两辆出租车是否具有相似的移动模式。在一个紧密连接的层之后,整个网络以纬度和经度的形式输出一个1分钟的超前预测。该网络使用Keras实现,网络架构如下图所示:
然后,在一个留存测试数据集中评估完全训练的模型。根据作者的说法,出租车每分钟行驶的平均距离是391米,这意味着如果系统使用当前位置作为预期的位置,那么它将导致391米的误差距离。将5辆LSTM+嵌入的出租车作为训练集的最终结果是2076米的误差。然而,随着出租车数量增加到8000辆,误差减少到152米,低于一分钟的平均行驶距离。
这两种情况都很好地说明了位置感知计算如何从深度学习中获益:一种是从原始传感器数据中获取的信息,另一种是直接使用位置数据来检测操作异常。显然,关于顺序数据的深度学习已经很好地建立起来了,然而,位置感知计算上的应用程序还不是很流行,也许是由于以下原因:
总的来说,目前位置感知计算在机器学习方面的水平非常有限,而在数据挖掘和解释方面需要大量的专家知识。这两种情况表明,数据的自动学习可以有效地改善当前位置感知计算。
一、目标跟踪通过部分可观察的随机过程
https://arxiv.org/abs/1602.00991
https://www.youtube.com/watch?v=cdeWCpfUGWc&feature=youtu.be
背景
这篇AAAI16论文提出了一种端到端对象跟踪方法,其中一端是模拟2D激光扫描仪收集的原始数据,另一端是整个环境状态,甚至包括遮挡的对象,如下图所示:
在这个跟踪问题背后,值得关注的是,由于遮挡,原始数据只能捕获环境的一部分。类似于局部可观察的随机过程的问题,传统上由贝叶斯滤波(如卡尔曼滤波)解决,反过来又涉及到许多手工设计的状态表示,并隐含着对模型分布的某些假设或抽样。这篇论文提出了第一个端到端可训练的解决方案,使机器人代理能够在无监督的情况下学习置信状态表示,以及相应的预测和更新操作,使其与传统方法相比更加有效省力。
模型
跟踪问题被认为是一种生成模型,包括一个详细描述环境动态的隐马尔可夫过程h。与此同时,它的外观层y捕捉到单个物体的位置,并且可以通过第三层,即传感器测量x的层进行部分观察,如下图所显示的
目标在给定x的历史输入序列中估计y的条件分布。注意y实际上不是马尔可夫过程,因此,隐藏马尔可夫模型等方法不能在这里应用。或者,这可以通过递归的贝叶斯估计来处理,在给定历史输入序列x(信念)的情况下,递归计算h的条件分布。目标可以估计为y的可信度的条件分布。这篇论文通过两个神经网络权重W_F 和W_P表达的最终目标,同时第一个网络指定了历史输入序列到可信度的模型,第二网络指定从可信度到位置(y at t)的模型。两个网络链接在一起,有效地使它们成为一个整体的前馈循环神经网络。该信任度的隐藏状态表示是从原始数据中学习的,并作为网络的内存从一个时间步骤传递到下一个。过滤过程如下图所示:
更具体地说,作者使用一个带有卷积运算的四层前馈循环网络,然后是每个层的sigmoid激活。网络的架构如下:
无人监督的培训
上述模型可以以常规方法训练,以尽量减少目标分布的负对数概度。然而,由于遮挡,y的地面实况数据可能无法访问。作者提出,通过删除当前时间步骤和当前n步骤(将其设置为0)之间的所有的观察,从而对网络进行训练,这样不仅可以预测下一个步骤,而且还可以预测未来进行更多的步骤(例如n步)。观察漏失必须在所有数据集中进行空间和时间上的执行,以避免过度拟合。这使得网络可以在没有地面实况数据的情况下进行训练,这是一种相对无监督的方式。
结果
训练集的总数量为1万个序列,长度为2000时间步骤。随机梯度下降训练5万次。有两个重要的发现:首先,无监督的训练结果与监督式学习结果几乎相同,表明观察漏失是有效的。第二,可信度层的激活显示了不同对象移动模式的适应表现。训练的进度可以在下面看到,也可以通过原创论文的附加视频看到(视频链接地址https://www.youtube.com/watch?v=cdeWCpfUGWc&feature=youtu.be)。
然而,可能是由于它是首个该类型的模型,作者没有提供任何量化的度量标准来表现或比较现有的作品。最后,根据作者的说法,它们正在把这篇文章扩展到更真实的数据和更具挑战性的机器人任务上。
二、基于地理空间轨迹的位置预测
https://launchpad.ai/blog/tracking
背景
最近Launchpad发布了一篇博客文章。人工智能将长期短时记忆(LSTM)引入到运输操作中。对于许多工业和室外应用来说,GPS和射频识别(RFID)跟踪技术现在很普遍,因为它们能捕捉到精确到米级的实时位置信息。然而,如何转化地理空间数据来改善操作过程是一个不容易理解的话题。作者提出了一种自动化的地理空间异常检测系统,该系统通过对被跟踪对象是否偏离预期轨迹来进行评估。利用LSTM网络从历史数据中学习。该系统被应用于一个真实的“数据集”(链接地址为http://sensor.ee.tsinghua.edu.cn/datasets.html),它包括北京28000辆出租车的一个月的轨迹。
模型
另外,时间标记和出租车的对应位置(纬度和经度)、速度、方位和占用状态也被规范化和分解成顺序数据。顺序数据将由LSTM网络处理。作者还考虑了该对象的身份信息。身份信息(本例中唯一的驱动ID)首先通过嵌入进行预处理,然后与LSTM输出合并。在某种程度上,驱动ID的语义暗示可以判断两辆出租车是否具有相似的移动模式。在一个紧密连接的层之后,整个网络以纬度和经度的形式输出一个1分钟的超前预测。该网络使用Keras实现,网络架构如下图所示:
结果
然后,在一个留存测试数据集中评估完全训练的模型。根据作者的说法,出租车每分钟行驶的平均距离是391米,这意味着如果系统使用当前位置作为预期的位置,那么它将导致391米的误差距离。将5辆LSTM+嵌入的出租车作为训练集的最终结果是2076米的误差。然而,随着出租车数量增加到8000辆,误差减少到152米,低于一分钟的平均行驶距离。
评论
这两种情况都很好地说明了位置感知计算如何从深度学习中获益:一种是从原始传感器数据中获取的信息,另一种是直接使用位置数据来检测操作异常。显然,关于顺序数据的深度学习已经很好地建立起来了,然而,位置感知计算上的应用程序还不是很流行,也许是由于以下原因:
- 评估中遇到的困难。事实上,上述案例更像是概念验证工作,因为它们没有通过提出可比和公平的评价指标来定量评估它们的工作。
- 缺少可靠的注释数据集。位置感知计算(通常是位置)的地面实况通常是不可访问的。例如,在第一篇论文中,在现实环境中记录所有目标的地面实况位置可能不太实际,大规模的学习不那么可行。
- 时间复杂度。与声音识别非常相似,时间数据序列的最小长度,使得地理空间意义是任意的且高度与上下文相关。在语音识别和光学字符识别(OCR)中,这个问题目前由连接主义时间分类器(CTC)处理,是否可以扩展到位置感知的计算仍未可知。
总的来说,目前位置感知计算在机器学习方面的水平非常有限,而在数据挖掘和解释方面需要大量的专家知识。这两种情况表明,数据的自动学习可以有效地改善当前位置感知计算。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
序列预测问题的简单介绍








广告


写评论取消
回复取消