











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






生成对抗网络GAN实现:比较不同的生成对抗网络的作用
2017年10月11日 由 yining 发表
284931
0
一些理论性的生成对抗网络GAN的实现包括:DCGAN, LSGAN, WGAN, WGAN-GP, BEGAN,还有DRAGAN。
这篇文章执行了与论文结构相同的模型结构,并在没有进行择优挑选的情况下将其与CelebA数据集进行了比较。
特征
CelebA
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
DCGAN
论文:Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
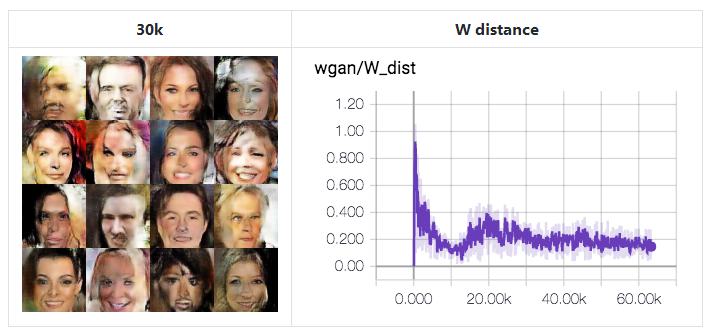
 第二行(50k,30k)表示每次训练迭代。
第二行(50k,30k)表示每次训练迭代。
生成器的更高的学习率(1e-3)产生了更好的结果。然而,在这种情况下,由于其巨大的学习速率,生成器有时会崩溃。
降低两个学习速率可能带来稳定性,如https://ajolicoeur.wordpress.com/cats/这个网站所展示的,其中D_lr=5e-5, G_lr=2e-4。
LSGAN
论文:Mao, Xudong, et al. "Least squares generative adversarial networks." arXiv preprint ArXiv:1611.04076 (2016).
 WGAN
WGAN
论文:Arjovsky, Martin, Soumith Chintala, and Léon Bottou. "Wasserstein gan." arXiv preprint arXiv:1701.07875 (2017).
 WGAN-GP
WGAN-GP
论文:Gulrajani, Ishaan, et al. "Improved training of wasserstein gans." arXiv preprint arXiv:1704.00028 (2017).
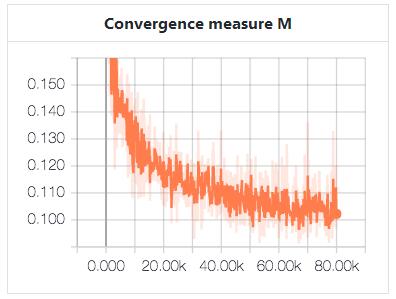
 面部崩溃现象
面部崩溃现象
当迭代增加时,WGAN-GP比其他模型崩溃的更大。
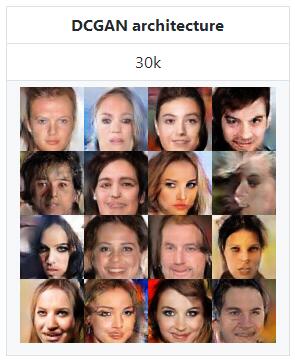
DCGAN架构
 ResNet架构
ResNet架构
ResNet架构在早期阶段展示了最好的视觉质量样本,有7000次迭代(以我的标准)。这可能是由于剩余的体系结构造成的。批量大小为64.
 不管面部崩溃原理,Wasserstein距离都在稳步下降。它应该来自于鉴别器网络未能找到上确界(supremum)函数和K-Lipschitz函数。
不管面部崩溃原理,Wasserstein距离都在稳步下降。它应该来自于鉴别器网络未能找到上确界(supremum)函数和K-Lipschitz函数。
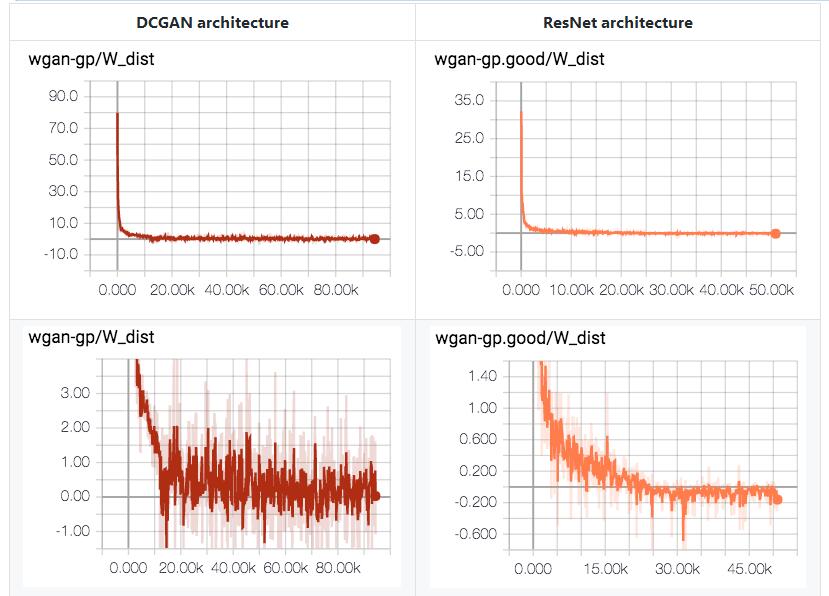
有趣的是,在训练结束的时候,W_dist < 0。这表明了E[fake] > E[real],并且在原始GAN的视图中,这意味着生成器在鉴别器中占主导。
BEGAN
论文:Berthelot, David, Tom Schumm, and Luke Metz. "Began: Boundary equilibrium generative adversarial networks." arXiv preprint arXiv:1703.10717 (2017).
batch_size=16, z_dim=64, gamma=0.5.

 DRAGAN
DRAGAN
论文:Kodali, Naveen, et al. "How to Train Your DRAGAN." arXiv preprint arXiv:1705.07215 (2017).
下载CelebA数据集:
将图像转换为tfrecords格式。转换的选项是硬编码(hard-coded)的,因此确保在运行
如果你想要更改每个模型的设置,你必须直接修改代码。
通过TensorBoard监控:
评估(生成假样本):
要求
这篇文章执行了与论文结构相同的模型结构,并在没有进行择优挑选的情况下将其与CelebA数据集进行了比较。
内容
- 特征
- 模型
- 数据集
- CelebA
- 结果
- DCGAN
- LSGAN
- WGAN
- WGAN-GP
- BEGAN
- DRAGAN
- 结论
- 使用
- 要求
- 类似的工作
特征
- 模型架构与每个论文中提出的架构相同
- 每个模型都没有太大的调优,因此可以改进结果
- 良好的结构
- 用于输入管道的TensorFlow queue runner
- 单一的训练机(单一的评估器)-多模型结构
- 训练和配置的日志记录在TensorBoard上
数据集
CelebA
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- 所有的实验都是在64x64的CelebA数据集上进行的
- 数据集有202599个图像
- 一个epoch包含1580次迭代,批处理大小为128(注:1个epoch等于使用训练集中的全部样本训练一次)
结果
- 默认batch_size=128,z_dim=100(来自DCGAN)
DCGAN
论文:Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
- 相对简单的网络
- 鉴别器(D_lr)的学习率是2e-4,而生成器(G_lr)的学习率是2e-4(上面论文中提到)和1e-3
第二行(50k,30k)表示每次训练迭代。生成器的更高的学习率(1e-3)产生了更好的结果。然而,在这种情况下,由于其巨大的学习速率,生成器有时会崩溃。
降低两个学习速率可能带来稳定性,如https://ajolicoeur.wordpress.com/cats/这个网站所展示的,其中D_lr=5e-5, G_lr=2e-4。
LSGAN
论文:Mao, Xudong, et al. "Least squares generative adversarial networks." arXiv preprint ArXiv:1611.04076 (2016).
- 不同寻常的是,LSGAN使用了巨大的潜在空间维度 (z_dim=1024)
- 但在我的实验中,z_dim=100的结果比在论文中最开始使用的z_dim=1024的结果要好得多
WGAN论文:Arjovsky, Martin, Soumith Chintala, and Léon Bottou. "Wasserstein gan." arXiv preprint arXiv:1701.07875 (2017).
- 与令人印象深刻的理论相比,WGAN的样本并不令人印象深刻
- 也没有提出具体的网络架构,所以DCGAN架构被用于实验
WGAN-GP论文:Gulrajani, Ishaan, et al. "Improved training of wasserstein gans." arXiv preprint arXiv:1704.00028 (2017).
- 尝试了两种网络架构,DCGAN架构和appendix C中的ResNet架构
- 与DCGAN架构相比,ResNet具有更复杂的架构和更好的性能
- 有趣的是,样本的视觉质量提高得很快((ResNet WGAN-GP在7000次迭代中拥有最好的样本),但在继续训练时情况会变得更糟
- 根据DRAGAN来看,WGAN的约束太过严格,无法学习优秀的生成器
面部崩溃现象当迭代增加时,WGAN-GP比其他模型崩溃的更大。
DCGAN架构
ResNet架构ResNet架构在早期阶段展示了最好的视觉质量样本,有7000次迭代(以我的标准)。这可能是由于剩余的体系结构造成的。批量大小为64.
不管面部崩溃原理,Wasserstein距离都在稳步下降。它应该来自于鉴别器网络未能找到上确界(supremum)函数和K-Lipschitz函数。有趣的是,在训练结束的时候,W_dist < 0。这表明了E[fake] > E[real],并且在原始GAN的视图中,这意味着生成器在鉴别器中占主导。
BEGAN
论文:Berthelot, David, Tom Schumm, and Luke Metz. "Began: Boundary equilibrium generative adversarial networks." arXiv preprint arXiv:1703.10717 (2017).
- 根据我所知,最好的模型能产生最好的视觉效果
- 它还展示了这个项目中最好的性能
- 尽管可选的改进没有实现(论文中的第3.5.1部分)
- 然而,这些样品所产生的样本与其他模型略有不同,看起来细节有些消失
- 因此,我想知道不同数据集的结果是什么
batch_size=16, z_dim=64, gamma=0.5.
DRAGAN论文:Kodali, Naveen, et al. "How to Train Your DRAGAN." arXiv preprint arXiv:1705.07215 (2017).
- 与其他论文提到的内容不同的是,DRAGAN的动机是为了提高GAN的工作效率
- 这种通过博弈论(game theory)的方法是非常独特和有趣的
- 它也显示了良好的结果
- 这个算法看起来与WGAN-GP相似
 结论
结论
- BEGAN展示了最好的表现
- 部分原因是网络架构和参数设置非常谨慎
- 它是否会对其他数据集起作用
- WGAN和WGAN-GP的结果并不像它的美丽的理论那样令人印象深刻
- 由于缺乏定量的测量方法,除了BEGAN之外,很难对模型进行排名。从每个模型中生成的样本的视觉质量都是相似的
- 相反地,自DCGAN以来,已经有了很多GANs,但是在视觉质量方面并没有显著的提高(除了BEGAN)
使用
下载CelebA数据集:
$ python download.py celeba
将图像转换为tfrecords格式。转换的选项是硬编码(hard-coded)的,因此确保在运行
convert.py之前修改它。$ python convert.py
如果你想要更改每个模型的设置,你必须直接修改代码。
$ python train.py --help
usage: train.py [-h] [--num_epochs NUM_EPOCHS] [--batch_size BATCH_SIZE]
[--num_threads NUM_THREADS] --model MODEL [--name NAME]
[--renew]
optional arguments:
-h, --help show this help message and exit
--num_epochs NUM_EPOCHS
default: 20
--batch_size BATCH_SIZE
default: 128
--num_threads NUM_THREADS
# of data read threads (default: 4)
--model MODEL DCGAN / LSGAN / WGAN / WGAN-GP / EBGAN / BEGAN /
DRAGAN
--name NAME default: name=model
--renew train model from scratch - clean saved checkpoints and
summaries
通过TensorBoard监控:
$ tensorboard --logdir=summary/name
评估(生成假样本):
$ python eval.py --help
usage: eval.py [-h] --model MODEL [--name NAME]
optional arguments:
-h, --help show this help message and exit
--model MODEL DCGAN / LSGAN / WGAN / WGAN-GP / EBGAN / BEGAN / DRAGAN
--name NAME default: name=model
要求
- python 2.7
- tensorflow 1.2
- tqdm
- (可选) pynvml - 自动gpu选项
类似的工作
- wiseodd/generative-models;地址:https://github.com/wiseodd/generative-models
- hwalsuklee/tensorflow-generative-model-collections;地址:https://github.com/hwalsuklee/tensorflow-generative-model-collections
- sanghoon/tf-exercise-gan;地址:https://github.com/sanghoon/tf-exercise-gan
- YadiraF/GAN_Theories;地址:https://github.com/YadiraF/GAN_Theories
- https://ajolicoeur.wordpress.com/cats/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消