











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






图像处理:利用神经网络生成新图像和修复旧图像
2017年09月15日 由 xiaoshan.xiang 发表
725292
0
查看附带Python代码的GitHub repo(链接地址为https://github.com/philkuz/PixelRNN)和Jupyter笔记本(链接地址为https://github.com/philkuz/PixelRNN/blob/master/pixelrnn.ipynb)的文章。
像素递归神经网络(PixelRNNs:链接地址为https://arxiv.org/pdf/1601.06759v3.pdf)结合了多种技术,并利用神经网络生成自然的图像。PixelRNNs模型利用一些新的技术,包括一个新的空间LSTM单元,对图像数据集进行分配,并按顺序推断图像中的像素(a)以生成新的图像,或者(b)预测不可见的像素,以完成遮挡图像。

图1中的图像是由基于32x32 ImageNet数据集的PixelRNN模型生成的,在本文中,我们将创建一个PixelRNN来生成MNIST数据集的图像,你可以在文章中进行跟踪,或者查看我们的Jupyter笔记本(链接地址为https://github.com/philkuz/PixelRNN/blob/master/pixelrnn.ipynb)。
在开始之前,你需要安装Python的TensorFlow(TF:链接地址为https://www.tensorflow.org/install/)。检查一下说明书,对于大多数人来说,它非常简单简单:
如果你以前没有使用过TF,我们推荐O 'reilly的文章,你好,TensorFlow !建立和训练你的第一个TensorFlow模型(链接地址为https://www.oreilly.com/learning/hello-tensorflow)。
我们之前提到过,PixelRNN是一个生成模型。一个生成模型试图模拟我们输入的数据的联合概率分布。在PixelRNN的背景下,这基本上意味着我们需要尽可能紧凑地模拟所有可能的现实图像。这样做将使我们能够从这个分布中生成新的图像。在机器学习中,对自然图像的分布进行建模是一个具有里程碑意义的问题。其他一些神经网络架构已经尝试实现这一任务,包括生成的对抗性网络(a . Redford,et. al .:链接地址为https://arxiv.org/abs/1511.06434),变分自动编码器(y . Pu,et. al .:链接地址为https://arxiv.org/abs/1609.08976)和空间LSTM网络(l . Theis,et. al:链接地址为https://arxiv.org/abs/1506.03478v2)。
为了对图像的分布进行建模,pixelrnn对像素强度进行了如下假设:像素的强度值依赖于在它之前遍历的所有像素。图像从左到右,从上到下沿图像进行。
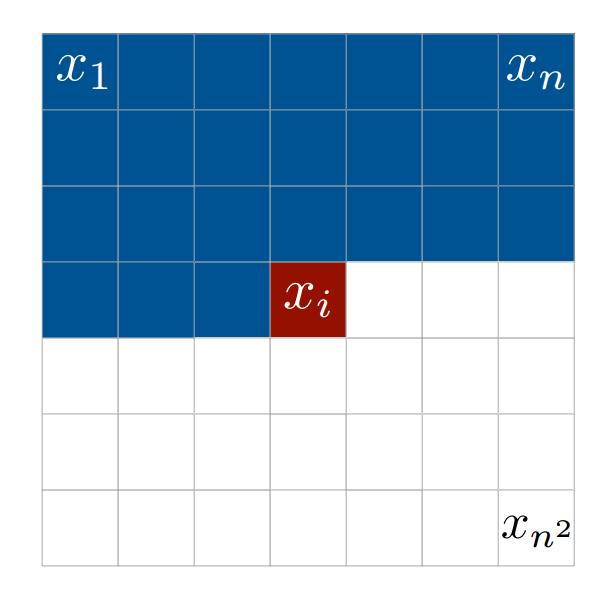
在一个\(nxn \)图像中,我们有一个像素\(x_i \)的强度被限制在所有前导像素\(x_j,0 \lt j \gt i \)上,或者换句话说:
我们通过将图像的所有条件概率相乘来计算图像x的联合概率,就像这样
我们通过一系列特殊的卷积来学习这些条件概率,这些特殊的卷积可以捕获给定像素周围的配置指令。
由PixelRNNs主要变体所使用的LSTM单元捕获了几十个或数百个像素的条件依赖关系。在谷歌DeepMind的论文(链接地址为https://arxiv.org/pdf/1601.06759v3.pdf)中,作者实现了一个新型空间双向LSTM单元和对角线BiLSTM,来捕获像素的所需空间配置指令。
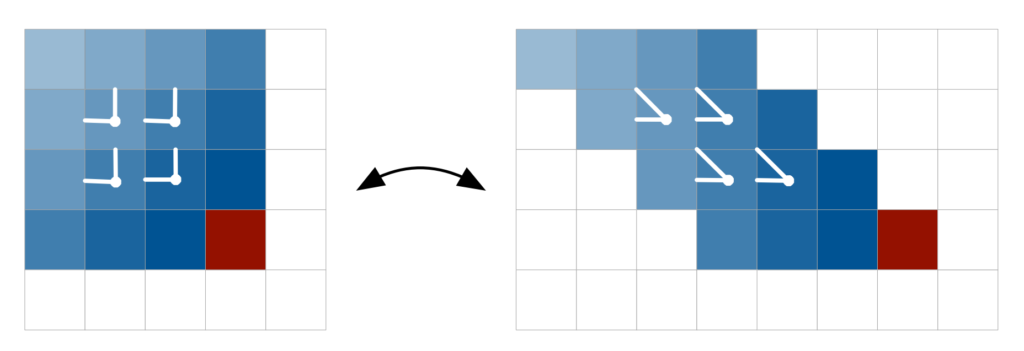
为了获取神经网络第一层以前的配置指令,我们对输入图像进行mask处理,以便于预测给定的像素\(x_i \),我们设置了所有像素未被遍历的值,\(x_j,j \ge i,\)到0,以防止它们影响总体预测。在随后的LSTM层中,我们执行一个类似的mask,但不再在mask中设置\(x_i \)到0。然后我们让图像偏斜,这样每一行都被上面的一行所抵消,如上所示。然后,我们可以使用对角线的BiLSTM单元在扭曲的图像上执行一系列k x 1的卷积。
这使我们能够有效地捕捉图像中的前导像素来预测即将到来的像素。LSTM单元还捕获了它们的接受域内像素之间潜在的无界依赖范围。然而,它需要花费很高的计算成本,因为LSTM需要在未来的一层中“展开”许多步骤。这就引出了一个问题:我们能不能做些更有效率的事情?
更快的替代架构包括用一系列的卷积来替换LSTM单元,以捕获一个更大的但有界的接受域。这使我们能够同时计算接受域内包含的特征,并避免按顺序计算每个细胞隐藏状态的计算成本。
我们在实现卷积运算是,可以在需要的时候执行这些mask(本文使用的笔记本:链接地址为https://github.com/philkuz/PixelRNN/blob/master/DraftRedux.ipynb):
在这里,我们使用了Xavieri初始权值方案(X.Glorot和X.Glorot:链接地址为http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf)来创建卷积内核
接下来,我们将mask应用于图像,以将内核的焦点限制在当前的配置指令。
最后,我们将卷积应用于图像,并应用一个可选的激活函数,如ReLU。
对于本文,我们将在MNIST数据集上训练PixelRNN,然后从PixelRNNs模型得到生成的手写数字,这些手写数字不会出现在我们的数据集中,你可以下载这些数据集(链接地址为http://yann.lecun.com/exdb/mnist/)。但是,如果你使用来自 utils.py的load_data()函数,你不用考虑这个问题。PixelRNNs能够通过预测其他像素来完成部分遮挡的图像。
我们在更早的时候使用卷积描述代替 Diagonal BiLSTM层
除了卷积层,PixelRNNs还利用了剩余连接(He,et. al .:链接地址为https://arxiv.org/abs/1512.03385)。剩余连接可以有效地从神经网络的早期层复制输出,并将其与更深层次的输出连接起来。这有助于保存模型早期学习的信息。对于我们模型中的卷积层,这些剩余连接看起来是这样的:
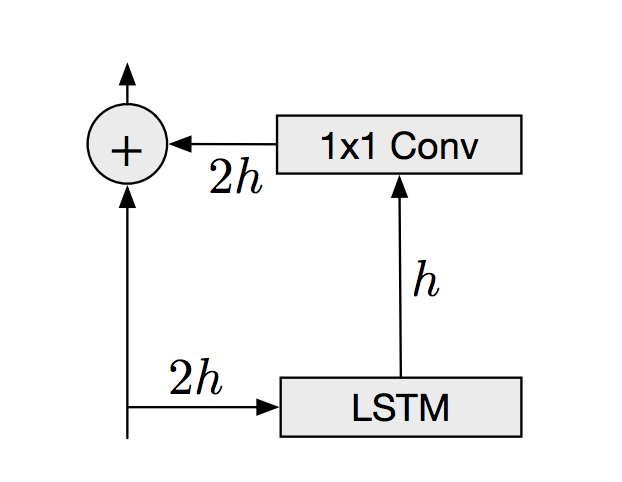
剩余连接允许我们的模型在深度上增加,并且仍然可以获得精度,同时使模型更容易优化。
最后一层在输入上应用一个sigmoid激活函数。该层输出的值在0到1之间,这是得到的标准化像素强度。
考虑到这一点,最终的架构是这样的:
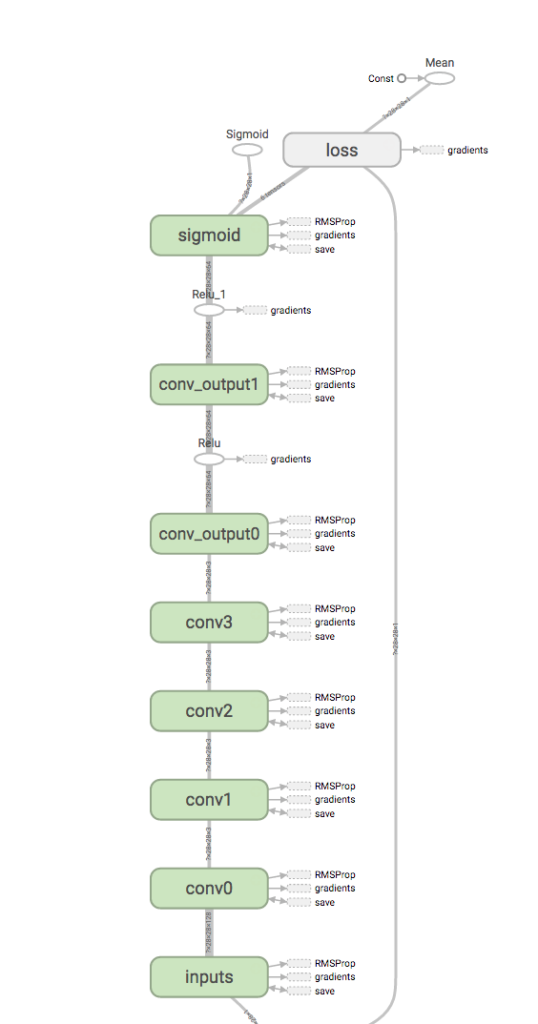
我们可以使用此架构和上面描述的卷积操作来创建神经网络。
我们在图像上应用一个7x7的卷积,同时应用初始的一个mask,移除与预期的像素之间的自连接。
接下来,我们在图像上应用一系列的1x1卷积
然后,我们使用ReLU激活来构造另一个1x1的卷积序列。
最后,我们用一个带有s形的激活的最后卷积层来预测一系列的图像的像素。
为了训练神经网络,我们提供了一些小批量的binUNK图像,并利用我们的神经网络预测每个并行像素。我们将预测和图像的二进制像素值之间的交叉熵最小化。我们使用学习率为0.001的RMSProp优化器优化这个目标,选择使用网格搜索。谷歌DeepMind论文将RMSProp优化列入到“通过所有实验的经验最有效的优化器”的名单中。在实践中,我们发现剪裁渐变有助于稳定学习。我们使用的每个卷积都包含100和16个隐藏单元。
使用以下程序优化我们在上面构建的神经网络:
训练神经网络之后,我们可以使用生成的模型生成样本图像,其中样本图像使用我们描述的生成模型。我们还可以通过部分遮挡的图像来推断剩下的像素值,进而完善整张图像。这样做的代码相当简单:
我们可以使用同样的生成过程来完成遮挡图像,只需要修改起始点。

如你所见,该算法能够成功地完成遮挡图像。显然,生成的数字和原始数字之间存在一些差异。例如,左上角的7在生成图像中变成了9。然而,这些错误并不是不合理的——在遮挡之后的曲线可以任意地属于几个不同的手写数字。
PixelRNN框架为生成建模提供了一个有用的架构。尽管我们为MNIST实现了一个单一的颜色通道版本,谷歌DeepMind的原始论文讨论了一个可以处理多通道彩色图像的稍微复杂的架构。该系统可以建模更复杂的数据集,如CIFAR10(链接地址为https://www.google.com/url?q=https://www.cs.toronto.edu/~kriz/cifar.html&sa=D&ust=1487746033540000&usg=AFQjCNHAfFjAk4duKpOqPn5i1abnYtH1Cg)和ImageNet(链接地址为http://www.image-net.org/)。TensorFlow Magenta团队有一个很好的评论(链接地址为https://github.com/tensorflow/magenta/blob/master/magenta/reviews/pixelrnn.md),解释了这个算法背后比论文的层次高的数学。
我们在这里展示的是简单数据集使用一个相对快速的模型的基准,这个模型可以学习MNIST图像的分布。接下来的步骤可能包括扩展这个模型,以处理由多个颜色通道组成的图像,比如CIFAR10。
另一种选择是实现原始对角线的BiLSTM单元,以取代更快速的卷积。这个实现的计算成本要高得多——即使是在最先进的GPU上。我们在实践中发现,基于卷积的架构比对角线的BiLSTM快20倍。
进一步研究基于卷积的架构,PixelCNN,可以在这篇论文中找到带有PixelCNN解码器的条件图像生成(链接地址为https://arxiv.org/pdf/1606.05328v2.pdf)。OpenAI最近又进一步研究并开发了一个repo(链接地址为https://github.com/openai/pixel-cnn),使用几个重要体系改进来执行上面论文提到的更快的计算版本。
别忘了看看我们的笔记本(链接地址为https://github.com/philkuz/PixelRNN/blob/master/pixelrnn.ipynb)和repo,注意,如果你没有GPU,你可以从AWS租用以节省开支。Phillip写了一个关于如何启动AWS EC2实例的指南(链接地址为https://github.com/philkuz/DeepAWS),包括如何设置一个Jupyter笔记本服务器。
像素递归神经网络(PixelRNNs:链接地址为https://arxiv.org/pdf/1601.06759v3.pdf)结合了多种技术,并利用神经网络生成自然的图像。PixelRNNs模型利用一些新的技术,包括一个新的空间LSTM单元,对图像数据集进行分配,并按顺序推断图像中的像素(a)以生成新的图像,或者(b)预测不可见的像素,以完成遮挡图像。
图1
图1中的图像是由基于32x32 ImageNet数据集的PixelRNN模型生成的,在本文中,我们将创建一个PixelRNN来生成MNIST数据集的图像,你可以在文章中进行跟踪,或者查看我们的Jupyter笔记本(链接地址为https://github.com/philkuz/PixelRNN/blob/master/pixelrnn.ipynb)。
在开始之前,你需要安装Python的TensorFlow(TF:链接地址为https://www.tensorflow.org/install/)。检查一下说明书,对于大多数人来说,它非常简单简单:
pip install tensorflow
如果你以前没有使用过TF,我们推荐O 'reilly的文章,你好,TensorFlow !建立和训练你的第一个TensorFlow模型(链接地址为https://www.oreilly.com/learning/hello-tensorflow)。
生成图像模型和前期工作
我们之前提到过,PixelRNN是一个生成模型。一个生成模型试图模拟我们输入的数据的联合概率分布。在PixelRNN的背景下,这基本上意味着我们需要尽可能紧凑地模拟所有可能的现实图像。这样做将使我们能够从这个分布中生成新的图像。在机器学习中,对自然图像的分布进行建模是一个具有里程碑意义的问题。其他一些神经网络架构已经尝试实现这一任务,包括生成的对抗性网络(a . Redford,et. al .:链接地址为https://arxiv.org/abs/1511.06434),变分自动编码器(y . Pu,et. al .:链接地址为https://arxiv.org/abs/1609.08976)和空间LSTM网络(l . Theis,et. al:链接地址为https://arxiv.org/abs/1506.03478v2)。
PixelRNN生成模型
为了对图像的分布进行建模,pixelrnn对像素强度进行了如下假设:像素的强度值依赖于在它之前遍历的所有像素。图像从左到右,从上到下沿图像进行。
图2
在一个\(nxn \)图像中,我们有一个像素\(x_i \)的强度被限制在所有前导像素\(x_j,0 \lt j \gt i \)上,或者换句话说:
$$x_i \sim p(x_i | x_1, x_2, \cdots, x_{i-1})$$我们通过将图像的所有条件概率相乘来计算图像x的联合概率,就像这样
$$p(x) = \prod_{i=1}^{n^2} p(x_i | x_1, \cdots, x_{i-1})$$我们通过一系列特殊的卷积来学习这些条件概率,这些特殊的卷积可以捕获给定像素周围的配置指令。
对角线BiLSTMs和卷积
由PixelRNNs主要变体所使用的LSTM单元捕获了几十个或数百个像素的条件依赖关系。在谷歌DeepMind的论文(链接地址为https://arxiv.org/pdf/1601.06759v3.pdf)中,作者实现了一个新型空间双向LSTM单元和对角线BiLSTM,来捕获像素的所需空间配置指令。
图3
为了获取神经网络第一层以前的配置指令,我们对输入图像进行mask处理,以便于预测给定的像素\(x_i \),我们设置了所有像素未被遍历的值,\(x_j,j \ge i,\)到0,以防止它们影响总体预测。在随后的LSTM层中,我们执行一个类似的mask,但不再在mask中设置\(x_i \)到0。然后我们让图像偏斜,这样每一行都被上面的一行所抵消,如上所示。然后,我们可以使用对角线的BiLSTM单元在扭曲的图像上执行一系列k x 1的卷积。
这使我们能够有效地捕捉图像中的前导像素来预测即将到来的像素。LSTM单元还捕获了它们的接受域内像素之间潜在的无界依赖范围。然而,它需要花费很高的计算成本,因为LSTM需要在未来的一层中“展开”许多步骤。这就引出了一个问题:我们能不能做些更有效率的事情?
一种更快的方法——同时计算多个特征
更快的替代架构包括用一系列的卷积来替换LSTM单元,以捕获一个更大的但有界的接受域。这使我们能够同时计算接受域内包含的特征,并避免按顺序计算每个细胞隐藏状态的计算成本。
我们在实现卷积运算是,可以在需要的时候执行这些mask(本文使用的笔记本:链接地址为https://github.com/philkuz/PixelRNN/blob/master/DraftRedux.ipynb):
def conv2d(
inputs,
num_outputs,
kernel_shape, # [kernel_height, kernel_width]
mask_type, # None, "A" or "B",
strides=[1, 1], # [column_wise_stride, row_wise_stride]
padding="SAME",
activation_fn=None,
weights_initializer=tf.contrib.layers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=tf.zeros_initializer,
biases_regularizer=None,
scope="conv2d"):
with tf.variable_scope(scope):
batch_size, height, width, channel = inputs.get_shape().as_list()
kernel_h, kernel_w = kernel_shape
stride_h, stride_w = strides
center_h = kernel_h // 2
center_w = kernel_w // 2
在这里,我们使用了Xavieri初始权值方案(X.Glorot和X.Glorot:链接地址为http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf)来创建卷积内核
weights_shape = [kernel_h, kernel_w, channel, num_outputs]
weights = tf.get_variable("weights", weights_shape,
tf.float32, weights_initializer, weights_regularizer)
接下来,我们将mask应用于图像,以将内核的焦点限制在当前的配置指令。
if mask_type is not None:
mask = np.ones(
(kernel_h, kernel_w, channel, num_outputs), dtype=np.float32)
mask[center_h, center_w+1: ,: ,:] = 0.
mask[center_h+1:, :, :, :] = 0.
if mask_type == 'a':
mask[center_h,center_w,:,:] = 0.
weights *= tf.constant(mask, dtype=tf.float32)
tf.add_to_collection('conv2d_weights_%s' % mask_type, weights)
最后,我们将卷积应用于图像,并应用一个可选的激活函数,如ReLU。
outputs = tf.nn.conv2d(inputs,
weights, [1, stride_h, stride_w, 1], padding=padding, name='outputs')
tf.add_to_collection('conv2d_outputs', outputs)
if biases_initializer != None:
biases = tf.get_variable("biases", [num_outputs,],
tf.float32, biases_initializer, biases_regularizer)
outputs = tf.nn.bias_add(outputs, biases, name='outputs_plus_b')
if activation_fn:
outputs = activation_fn(outputs, name='outputs_with_fn')
return outputs
生成图像与MNIST
对于本文,我们将在MNIST数据集上训练PixelRNN,然后从PixelRNNs模型得到生成的手写数字,这些手写数字不会出现在我们的数据集中,你可以下载这些数据集(链接地址为http://yann.lecun.com/exdb/mnist/)。但是,如果你使用来自 utils.py的load_data()函数,你不用考虑这个问题。PixelRNNs能够通过预测其他像素来完成部分遮挡的图像。
神经网络的特性
我们在更早的时候使用卷积描述代替 Diagonal BiLSTM层
除了卷积层,PixelRNNs还利用了剩余连接(He,et. al .:链接地址为https://arxiv.org/abs/1512.03385)。剩余连接可以有效地从神经网络的早期层复制输出,并将其与更深层次的输出连接起来。这有助于保存模型早期学习的信息。对于我们模型中的卷积层,这些剩余连接看起来是这样的:
图4
剩余连接允许我们的模型在深度上增加,并且仍然可以获得精度,同时使模型更容易优化。
最后一层在输入上应用一个sigmoid激活函数。该层输出的值在0到1之间,这是得到的标准化像素强度。
考虑到这一点,最终的架构是这样的:
图5
我们可以使用此架构和上面描述的卷积操作来创建神经网络。
def pixelRNN(height, width, channel, params):
"""
Args
height, width, channel - the dimensions of the input
params the hyperparameters of the network
"""
input_shape = [None, height, width, channel]
inputs = tf.placeholder(tf.float32, input_shape)
我们在图像上应用一个7x7的卷积,同时应用初始的一个mask,移除与预期的像素之间的自连接。
# input of main recurrent layers
scope = "conv_inputs"
conv_inputs = conv2d(inputs, params.hidden_dims, [7, 7], "A", scope=scope)
接下来,我们在图像上应用一系列的1x1卷积
# main recurrent layers
last_hid = conv_inputs
for idx in xrange(params.recurrent_length):
scope = 'CONV%d' % idx
last_hid = conv2d(last_hid, 3, [1, 1], "B", scope=scope)
print("Building %s" % scope)
然后,我们使用ReLU激活来构造另一个1x1的卷积序列。
# output recurrent layers
for idx in xrange(params.out_recurrent_length):
scope = 'CONV_OUT%d' % idx
last_hid = tf.nn.relu(conv2d(last_hid, params.out_hidden_dims, [1, 1], "B", scope=scope))
print("Building %s" % scope)
最后,我们用一个带有s形的激活的最后卷积层来预测一系列的图像的像素。
conv2d_out_logits = conv2d(last_hid, 1, [1, 1], "B", scope='conv2d_out_logits')
output = tf.nn.sigmoid(conv2d_out_logits)
return inputs, output, conv2d_out_logits
inputs, output, conv2d_out_logits = pixelRNN(height, width, channel, p)
训练过程
为了训练神经网络,我们提供了一些小批量的binUNK图像,并利用我们的神经网络预测每个并行像素。我们将预测和图像的二进制像素值之间的交叉熵最小化。我们使用学习率为0.001的RMSProp优化器优化这个目标,选择使用网格搜索。谷歌DeepMind论文将RMSProp优化列入到“通过所有实验的经验最有效的优化器”的名单中。在实践中,我们发现剪裁渐变有助于稳定学习。我们使用的每个卷积都包含100和16个隐藏单元。
使用以下程序优化我们在上面构建的神经网络:
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(conv2d_out_logits, inputs, name='loss'))
optimizer = tf.train.RMSPropOptimizer(p.learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
new_grads_and_vars = \
[(tf.clip_by_value(gv[0], -p.grad_clip, p.grad_clip), gv[1]) for gv in grads_and_vars]
optim = optimizer.apply_gradients(new_grads_and_vars)
生成和遮挡完成
训练神经网络之后,我们可以使用生成的模型生成样本图像,其中样本图像使用我们描述的生成模型。我们还可以通过部分遮挡的图像来推断剩下的像素值,进而完善整张图像。这样做的代码相当简单:
def predict(sess, images, inputs, output):
return sess.run(output, {inputs: images})
def generate(sess, height, width, inputs, output):
samples = np.zeros((100, height, width, 1), dtype='float32')
for i in range(height):
for j in range(width):
next_sample = binarize(predict(sess, samples, inputs, output))
samples[:, i, j] = next_sample[:, i, j]
return samples
def generate_occlusions(sess, height, width, inputs, output):
samples = occlude(images, height, width)
starting_position = [0,height//2]
for i in range(starting_position[1], height):
for j in range(starting_position[0], width):
next_sample = binarize(predict(sess, samples, inputs, output))
samples[:, i, j] = next_sample[:, i, j]
return samples
我们可以使用同样的生成过程来完成遮挡图像,只需要修改起始点。
图6
如你所见,该算法能够成功地完成遮挡图像。显然,生成的数字和原始数字之间存在一些差异。例如,左上角的7在生成图像中变成了9。然而,这些错误并不是不合理的——在遮挡之后的曲线可以任意地属于几个不同的手写数字。
下一步
PixelRNN框架为生成建模提供了一个有用的架构。尽管我们为MNIST实现了一个单一的颜色通道版本,谷歌DeepMind的原始论文讨论了一个可以处理多通道彩色图像的稍微复杂的架构。该系统可以建模更复杂的数据集,如CIFAR10(链接地址为https://www.google.com/url?q=https://www.cs.toronto.edu/~kriz/cifar.html&sa=D&ust=1487746033540000&usg=AFQjCNHAfFjAk4duKpOqPn5i1abnYtH1Cg)和ImageNet(链接地址为http://www.image-net.org/)。TensorFlow Magenta团队有一个很好的评论(链接地址为https://github.com/tensorflow/magenta/blob/master/magenta/reviews/pixelrnn.md),解释了这个算法背后比论文的层次高的数学。
我们在这里展示的是简单数据集使用一个相对快速的模型的基准,这个模型可以学习MNIST图像的分布。接下来的步骤可能包括扩展这个模型,以处理由多个颜色通道组成的图像,比如CIFAR10。
另一种选择是实现原始对角线的BiLSTM单元,以取代更快速的卷积。这个实现的计算成本要高得多——即使是在最先进的GPU上。我们在实践中发现,基于卷积的架构比对角线的BiLSTM快20倍。
进一步研究基于卷积的架构,PixelCNN,可以在这篇论文中找到带有PixelCNN解码器的条件图像生成(链接地址为https://arxiv.org/pdf/1606.05328v2.pdf)。OpenAI最近又进一步研究并开发了一个repo(链接地址为https://github.com/openai/pixel-cnn),使用几个重要体系改进来执行上面论文提到的更快的计算版本。
别忘了看看我们的笔记本(链接地址为https://github.com/philkuz/PixelRNN/blob/master/pixelrnn.ipynb)和repo,注意,如果你没有GPU,你可以从AWS租用以节省开支。Phillip写了一个关于如何启动AWS EC2实例的指南(链接地址为https://github.com/philkuz/DeepAWS),包括如何设置一个Jupyter笔记本服务器。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消