


















如何正确的猜拳:反事实遗憾最小化算法
反事实遗憾算法是一种自我演绎的AI模型。本质是两个AI智能体互相对抗,从头开始学习游戏。事实上在多数情况下,这是一个智能体进行自我对抗,所以它的学习速度会翻倍(重点注意,尽管它本身是和自己玩,但实际上它并没有足够聪明到站在对手的位置理解它上一步的行为。)
与许多最近在AI研究中的重大突破(如AlphaGo)不同,CFR不依赖于神经网络计算概率或特定举措的价值。取代通过自我对局数百万甚至上亿的的方法,它从总结每个操作对特定位置加以考虑的遗憾总量着手。
这个算法令人兴奋的是,随着游戏的进行它将越来越接近游戏的最佳策略,即纳什均衡。它已经在许多游戏和领域证明了自己,最有趣的是扑克特别是无限德州扑克。这是我们目前拥有的最好的扑克AI算法。
遗憾匹配
遗憾匹配(RM)是一种寻找最大限度地减少对游戏每个步骤决策遗憾的算法。顾名思义,它从过去的行为学习告知未来决策,通过赞同它后悔以前没有采取的行为。
在这个模式中,既有积极的遗憾和消极的遗憾。当消极遗憾被你定义成你期望的情况:在特别得情况下采取特别行动的遗憾。这意味着如果在这种情况下没有选择这个行为,智能体会做得更好。
 Garry Kasparov意识到他对Viswanathan Anand的错误。
Garry Kasparov意识到他对Viswanathan Anand的错误。
积极的遗憾也定义成你期望的: 这是一种智能体可以跟踪导致积极结果的行为的机制。(我个人认为应该被称为别的东西,但这无所谓。)
在智能体在自我对抗的每场游戏后,最新游戏中遇到的负面和积极的遗憾都被添加到所有其他盘游戏中的总结里,并且计算出新的策略。
简而言之,通过概率,它偏好采取过去产生的积极成果的行动并避免采取导致负面结果的行为。
与其他的学习机制一样人类也有遗憾学习机制—我们尝试做一些事情,如果失败并引起消极的情绪反应,我们会记下这种遗憾,并让自己再次尝试。以“Scissors-Paper-Rock(SPR)”游戏为例(就是猜拳),如果我们在对手出布的时候出了石头,我们就后悔没有出剪子。

这种模式在零和游戏中向靠拢纳什均衡,对于那些不熟悉博弈论的人来说,游戏中每个智能体的赢或输完全可以由其他智能体的赢或输来平衡。例如,剪刀,石头,布,是零和游戏。当你打败你的对手时,你赢了+1,他们输了-1,和为零。
猜拳
在这里,我们将猜拳(SPR)标准化作为一种存在纳什均衡的标准的零和的双人游戏。虽然这句话包含了很多信息,但我们将其分解成组件。首先,SPR可以定义为元组< N,A,u >,正式称为规格化形式:
- N = 1,... .n代表n个玩家的有限集合。在猜拳中,一般是N={1,2}
- S是一个有限动作的组。这里每个玩家都有相同的动作选择,所以S ={ S,P,R }
![]()
是所有玩家同时行动的所有可能组合。即,A = {(R,R),......,(S,P)},并且每个组合被称为动作剖析。
U是一个函数映射,将每个玩家的每个行动的数据储存成一个效果或者回报的矢量。
- U是每个动作简档映射到向量为每个玩家公用事业/回报的功能。例如,(R,P)=(-1,1)意味着如果玩家1出了石头给玩家2的布(即输了),玩家1的奖励为-1。因此,我们可以为玩家1定义一个效用矩阵如下:
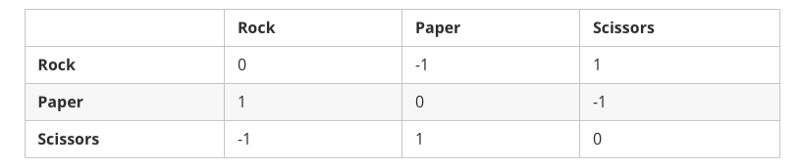
此外,我们也可以定义策略σᵢ(s)作为玩家ᵢ选择动作s∈S的概率。当玩家使用遗憾匹配来更新自己的战略,σᵢ(s)预支成正比的累积遗憾。请注意,每个效用向量的和都为0,因此我们将其称为零和博弈。在任何双人零和博弈中,当两个玩家都坚持遗憾匹配时,他们的平均策略收敛于纳什均衡,即两者都能够最大化自己预期的效用:
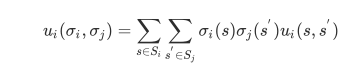
但现在已经有足够的数学抽象了。我们言归正传,在实践中了解一些关于遗憾匹配实际工作的具体原理。在本教程中,我们将编写一个实现RM算法完猜拳游戏的简单程序。我们假设读者有Python编程语言的基础知识,最好是接触过Numpy。
我们首先导入本程序所需的模块。
from __future__ import division
from random import random
import numpy as np
import pandas as pd
然后我们定义猜拳游戏的基本参数。“utilities”是上述效用函数,用于确定行动剖析的实用值。按惯例,我们定义行的玩家是玩家1,列的玩家是玩家2.因此,为了查询给定动作剖析(s1 = Rock,s2 = Paper)的玩家1的实用值,我们调用
utilities.loc['ROCK', 'PAPER']。class RPS:
actions = ['ROCK', 'PAPER', 'SCISSORS']
n_actions = 3
utilities = pd.DataFrame([
# ROCK PAPER SCISSORS
[ 0, -1, 1], # ROCK
[ 1, 0, -1], # PAPER
[-1, 1, 0] # SCISSORS
], columns=actions, index=actions)
每个玩家负责维护自己的策略和遗憾的统计。目前,我们只提出一个类框架,但稍后会回到实现细节。有几个变量需要解释:
- 策略:对应于σ(s),策略向量,表示当前采取行动的概率。
- 策略总计:
![]()
是从游戏开始到现在策略向量的总和。
- Regret_sum:是每次迭代的遗憾矢量的总和。
- avg_strategy:归一化策略总和
class Player:
def __init__(self, name):
self.strategy, self.avg_strategy,\
self.strategy_sum, self.regret_sum = np.zeros((4, RPS.n_actions))
self.name = name
def __repr__(self):
return self.name
def update_strategy(self):
"""
set the preference (strategy) of choosing an action to be proportional to positive regrets
e.g, a strategy that prefers PAPER can be [0.2, 0.6, 0.2]
"""
self.strategy = np.copy(self.regret_sum)
self.strategy[self.strategy < 0] = 0 # reset negative regrets to zero
summation = sum(self.strategy)
if summation > 0:
# normalise
self.strategy /= summation
else:
# uniform distribution to reduce exploitability
self.strategy = np.repeat(1 / RPS.n_actions, RPS.n_actions)
self.strategy_sum += self.strategy
def regret(self, my_action, opp_action):
"""
we here define the regret of not having chosen an action as the difference between the utility of that action
and the utility of the action we actually chose, with respect to the fixed choices of the other player.
compute the regret and add it to regret sum.
"""
result = RPS.utilities.loc[my_action, opp_action]
facts = RPS.utilities.loc[:, opp_action].values
regret = facts - result
self.regret_sum += regret
def action(self, use_avg=False):
"""
select an action according to strategy probabilities
"""
strategy = self.avg_strategy if use_avg else self.strategy
return np.random.choice(RPS.actions, p=strategy)
def learn_avg_strategy(self):
# averaged strategy converges to Nash Equilibrium
summation = sum(self.strategy_sum)
if summation > 0:
self.avg_strategy = self.strategy_sum / summation
else:
self.avg_strategy = np.repeat(1/RPS.n_actions, RPS.n_actions)
游戏/环境的定义 我们有两名玩家Alasdair和Calum,除非明确指定max_game,否则玩1000局。“play_regret_matching”函数充分描述了原始遗憾匹配的过程:
- 从累积遗憾计算遗憾匹配策略剖析。
- 根据策略剖析选择每个玩家操作情况
- 计算玩家遗憾并添加到玩家累积的遗憾中。
class Game:
def __init__(self, max_game=10000):
self.p1 = Player('Alasdair')
self.p2 = Player('Calum')
self.max_game = max_game
def winner(self, a1, a2):
result = RPS.utilities.loc[a1, a2]
if result == 1: return self.p1
elif result == -1: return self.p2
else: return 'Draw'
def play(self, avg_regret_matching=False):
def play_regret_matching():
for i in xrange(0, self.max_game):
self.p1.update_strategy()
self.p2.update_strategy()
a1 = self.p1.action()
a2 = self.p2.action()
self.p1.regret(a1, a2)
self.p2.regret(a2, a1)
winner = self.winner(a1, a2)
num_wins[winner] += 1
def play_avg_regret_matching():
for i in xrange(0, self.max_game):
a1 = self.p1.action(use_avg=True)
a2 = self.p2.action(use_avg=True)
winner = self.winner(a1, a2)
num_wins[winner] += 1
num_wins = {
self.p1: 0,
self.p2: 0,
'Draw': 0
}
play_regret_matching() if not avg_regret_matching else play_avg_regret_matching()
print num_wins
def conclude(self):
"""
let two players conclude the average strategy from the previous strategy stats
"""
self.p1.learn_avg_strategy()
self.p2.learn_avg_strategy()
现在让我们实现未完成的玩家类,从“regret”和“action”函数开始。考虑到行动剖析(Rock,Paper),不采取行动相应的遗憾基本上是行动与对手行为之间的效用差异,即(Rock = -1,Scissor = 1,Paper = 0),剪刀被明确的舍弃了。
class Player:
# ....
def regret(self, my_action, opp_action):
"""
We here define the regret of not having chosen an action as the difference between the utility of that action and the utility of the action we actually chose, with respect to the fixed choices of the other player. Compute the regret and add it to regret sum.
"""
result = RPS.utilities.loc[my_action, opp_action]
facts = RPS.utilities.loc[:, opp_action].values
regret = facts - result
self.regret_sum += regret
def action(self, use_avg=False):
"""
select an action according to strategy probabilities
"""
strategy = self.avg_strategy if use_avg else self.strategy
return np.random.choice(RPS.actions, p=strategy) # p refers to 'probability'
“update_strategy”函数与遗憾匹配算法的核心思想一致:“选择与过去没有选择的积极后悔成正比的行为”,因此策略实际上是积极的遗憾归一化。然而,请注意,当没有积极的遗憾(也就是,说上一场比赛是完美的)时,我们采取随机策略,尽可能地减少暴露采取行动的偏见,因为这种偏见可以被对手利用。
class Player:
# ....
def update_strategy(self):
"""
Set the preference (strategy) of choosing an action to be proportional to positive regrets. e.g, a strategy that prefers PAPER can be [0.2, 0.6, 0.2]
"""
self.strategy = np.copy(self.regret_sum)
self.strategy[self.strategy < 0] = 0 # reset negative regrets to zero
summation = sum(self.strategy)
if summation > 0:
# normalise
self.strategy /= summation
else:
# uniform distribution to reduce exploitability
self.strategy = np.repeat(1 / RPS.n_actions, RPS.n_actions)
self.strategy_sum += self.strategy
def learn_avg_strategy(self):
# averaged strategy converges to Nash Equilibrium
summation = sum(self.strategy_sum)
if summation > 0:
self.avg_strategy = self.strategy_sum / summation
else:
self.avg_strategy = np.repeat(1/RPS.n_actions, RPS.n_actions)
现在我们可以开始运行了!尝试多次运行后你可能会发现:单纯的遗憾匹配并不总是产生均匀分布的赢家数,反而平均后悔遗憾匹配可以产生。如果你在单纯的遗憾匹配的在每个中间迭代打印“num_wins”,不甚至看到优胜者定期在p1和p2之间产生。这是由于简单遗憾匹配的可利用性。想象你知道对手喜欢出剪刀,你可能会在接下来的几个回合中偏向出石头,并且需要一段时间后悔自己的偏见。
然而,平均的结果是在SPR中随机选择一个完美的策略。这是对对手采取的任何固定策略的最佳反应,在每个动作选择中都没有留下可利用的信息。
if __name__ == '__main__':
game = Game()
print '==== Use simple regret-matching strategy === '
game.play()
print '==== Use averaged regret-matching strategy === '
game.conclude()
game.play(avg_regret_matching=True)
完整的源代码可从以下网址获得:
https://gist.github.com/namoshizun/7a3b820b013f8e367e84c70b45af7c34









