











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






手势识别:使用标准2D摄像机建立一个强大的的手势识别系统
2017年09月22日 由 xiaoshan.xiang 发表
853239
0
手势和语言一样,是人类交流的一种自然形式。事实上,它们可能是最自然的表达方式。进化研究表明,人类语言是从手势开始的,而不是声音。另一个证明就是婴儿在学会说话之前,使用手势来传达情感和欲望。

许多科技公司一次又一次尝试用手势控制器来代替键盘和鼠标,以记录用户的手部或手臂动作的意图。虽然一些第一类系统使用了有线手套,但现代的方法往往依赖于特殊的摄像头和计算机视觉算法。最著名的例子是微软的Kinect,它于2010年11月推出,并创下了吉尼斯世界纪录,成为最畅销的消费设备。尽管Kinect最初取得了成功,但手势控制器并没有得到消费者的广泛认可。
原因可能是传统的手势控制系统有几个缺点:首先,它们要求用户购买特殊的硬件,比如立体声摄像机或飞行时间摄像头,以在三维空间中捕捉视觉数据。这已经排除了像笔记本电脑或智能手机这样的标准消费硬件。其次,现有体系的表现并不完美。现实世界是混乱的,每个用户都倾向于以略微不同的方式执行一个给定的手势。这使得构建强大的、用户独立的识别模型变得困难。

在TwentyBN上,我们采用了一种不同的手势识别方法,使用了一个非常大的、带注释的动态手势视频并使用神经网络训练这些数据集。我们已经创建了一个端到端的解决方案,它运行在各种各样的摄像机平台上。这使得我们可以建立一个手势识别系统,它是稳健的,并且只用一个RGB摄像机实时工作。
“Jester”数据集
为了训练我们的系统,我们使用了大量的简短的,密集的视频剪辑,这些视频片段是由我们社区的群众收集的。该数据集(https://www.twentybn.com/datasets/jester)包含15万段25个不同类别的人类手势视频,以8:1:1的比例进行训练/ dev/测试;它还包括两个“无手势”类,以帮助网络区分特定的手势和未知的手势动作。视频显示,人类演员在网络摄像头前表演通用手势,比如“向左/右转”,“两个手指向上/向下滑动,”或“将手向前/向后摆动”。“如果你想了解更多关于这个数据集的信息,你可能会发现,我们已经发布了一个在创意共享许可下用于非商业用途的重要的图像抓拍。”
视频剪辑是具有挑战性的,因为它们捕捉了真实世界的复杂动态。看看这段视频:

虽然这个手势对人类来说很容易辨认,但对于计算机来说却很难理解,因为视频中包含了次优光照条件和背景噪音(猫穿过场景)。Jester的训练迫使神经网络学习相关的视觉特征等级,以便将信号(手运动)与噪音(背景运动)分开。基本的运动检测是不够的。
模型架构
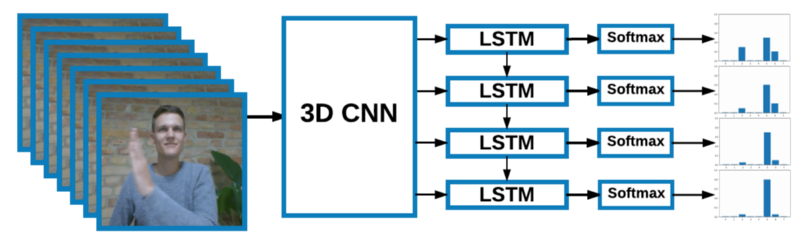
过去几个月我们的工作重点是有效地使用我们日益增长的Jester数据集,设计和训练神经网络。我们研究了几个体系结构,提出了一个既满足高性能需求又创建最小运行时开销的解决方案。最后,我们在一个包含三维卷积网络(3d - cnn)的架构上聚合,以提取时空特征,一个循环层(LSTM)来建模更长的时间关系,以及一个输出类概率的softmax层。
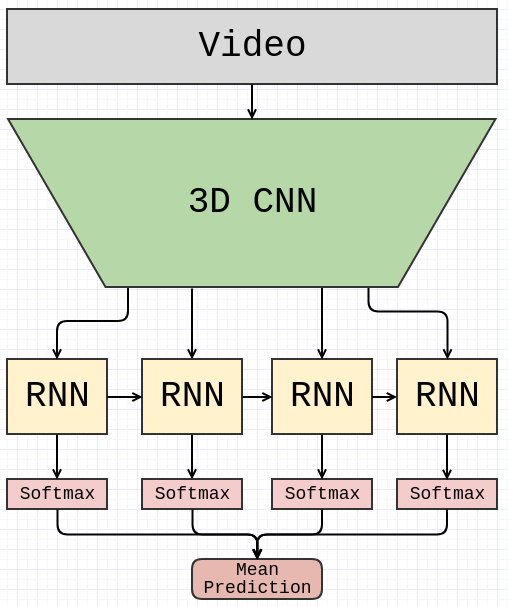
与擅长处理图像的2d - cnns相比,3d - cnns使用三维滤镜将二维卷积扩展到时域。视频被处理成帧的三维“卷”。在神经网络的下层使用这样的3D过滤器是有帮助的,特别是在运动中起关键作用的任务中。神经网络的输出是一系列特性,每一个特性都可以被看作是一个小的输入视频片段的压缩表示。
然后由LSTM层处理这个特性序列,允许较长的时间依赖。在测试的时候,我们利用了一个事实:循环网络是一个可以通过时间来完成的动态系统。在训练时,每一个循环隐藏状态通过一个softmax层转换为类概率向量,得到的预测序列在时间上是平均的。平均向量被用来计算损失。可以认为这是一种让网络尽快输出合适的标签的方式,迫使它与视频中发生的事情保持同步。这种常见的方法可以使模型具有反应性,并在完成一个手势之前,输出对正确的类的最佳猜测。
我们的3d - cnn架构是一系列成对的层的序列,这些层的过滤器大小分别为1和3,按顺序排列。过滤器大小为1的层用于解释channel-wise相关性,并减少下一层的通道数。过滤器大小为3的层捕获空间信息。最终的架构能够达到18fps的处理速度,有87%的离线验证精度。
成果
为了展示我们的成果,我们使用Python和Javascript创建了一个简单的客户机-服务器系统,我们可以使用它来实时演示网络的推断。

系统由多个并行进程组成,分别负责系统的不同部分:视频捕获、网络推理、编制和HTTP服务。该模型在TensorFlow中实现,我们使用协议缓冲区来保存和加载网络。这让我们可以在网络浏览器中查看当前的网络摄像头流,并查看预测的质量。你可以在这里看一段更长的视频(https://www.youtube.com/watch?v=VlPnqL5osYQ)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消