


















动态可扩展的神经网络:一种最近发现的技术,可不断地适应新数据
神经网络可以很容易地学习复杂的表示。然而,在一些任务中,新的数据(或数据的类别)在不断变化。例如,你可以训练一个网络来识别8种不同类型的猫的图片。但在未来,你可能想要把图片数量改变为12种。网络需要不断地学习新的数据的过程,就会被称为“持续学习”。
这篇文章讨论的是一种最近的技术“动态可扩展的神经网络”。这种技术试图不断地适应新的数据,而这只是重新训练整个模型的成本的一小部分。
本文将基于“对动态可扩展网络的终身学习”这篇论文进行扩展,论文地址:https://arxiv.org/pdf/1708.01547v2.pdf此外,你还需要了解一些关于神经网络的知识,包括重量、规则化、神经元等等。

持续学习是什么?
随着时间的推移,数据会到达序列中,算法必须学会如何预测新的数据。通常,像传输学习这样的技术会被使用,它的模型在之前的数据上被训练,并且模型的一些特性被用于学习新的数据。这通常是为了减少从头开始训练模型所需要的时间。同时,当新数据稀疏时也会用到它。
存在的问题
执行这种学习的最简单方法就是不断地根据更新的数据对模型进行微调。然而,如果新任务与旧任务有很大的不同,该模型将不能很好地在那个新任务上运行,旧任务的特性也会变得没用。
另一个问题是,在微调之后,模型可能开始执行原始任务。例如,斑马身上的条纹与条纹t恤或栅栏虽然图案看起来类似,但本身的含义是截然不同的。对这种模型进行微调将会降低其识别斑马的性能。
动态可扩展的网络
在一个非常高的水平上,扩展网络的想法是非常合乎逻辑的。训练一个模型,如果它不能很好地预测,那么就要增加它的学习能力。如果一个新任务与现有的任务有很大的不同,那么从旧模型中提取出有用的信息并再次训练一个新的模型。
现在介绍三种不同的技术,使这样的想法成为可能。
- 有选择性的再训练——找到与新任务相关的神经元,并保留它们。
- 动态网络扩展-如果模型不能从训练的第一个步骤中学习(即损失高于阈值),那么就要通过增加更多的神经元来增加模型的容量。
- 网络分割/复制-如果一些新模型的单元已经开始发生剧烈的变化,那么就要复制这些权重,并且重新训练这些复制,同时保持旧的权重不变。
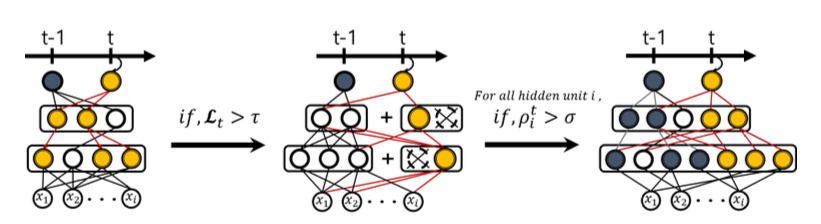 左:选择性训练 中:动态扩展 右:网络分割
左:选择性训练 中:动态扩展 右:网络分割
在上图,图t表示任务序号(task number)。因此,t-1表示前面的任务,t表示当前任务。
有选择性的再训练
训练一个新模型的最简单的方法是在每次新任务到来时对整个模型进行训练。然而,由于深度神经网络可以变得非常大,这种方法也会变得非常昂贵。
为了避免这样的问题,在第一个任务中,模型采用L1正则化训练。这确保了网络中的稀疏,也就是说,只有一些神经元与其他神经元相连。你们马上就会明白为什么这样做是有用的。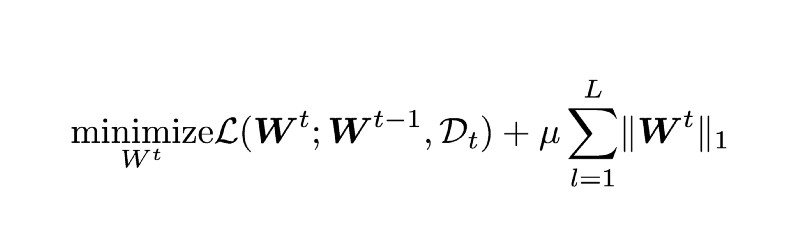
初始任务的损失函数
W^t表示在时间t上模型的权值,这种情况下,t=1。D_t表示在时间t上训练数据。这个方程的右半部分,从μ开始,就是L1正则化项,μ是正则化强度。L表示网络从第一层到最后一层的各个层。该规则试图使模型的权重接近(或等于)零。
l1和l2的正则化相关内容,你可以从这里阅读:http://cs231n.github.io/neural-networks-2/#reg
当需要学习下一个任务时,一个稀疏的线性分类器被安装到模型的最后一层,然后网络就可以被训练使用:
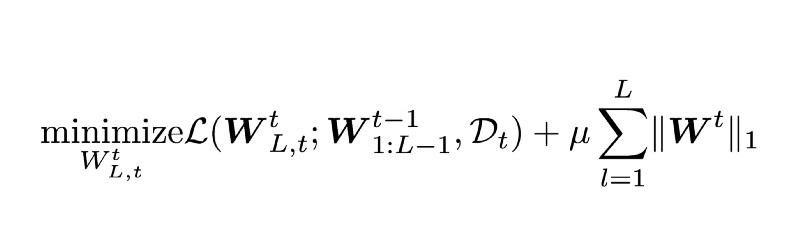
为下一个任务训练网络
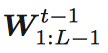
这个数学符号意味着除了最后一层以外的所有层的权重。所有的这些层(从第一个到最后一个)都是固定的,而新添加的层是用相同的l1正则化来优化的,从而促进稀疏的连接。
构建这种稀疏的连接有助于识别那些在模型其他部分受到影响的神经元。这一发现是通过广度优先搜索(Breadth First Search)完成的,它是一种非常流行的搜索算法。然后,只有那些权重可以被更新,节省了大量的计算时间,而没有连接的权重也不会被触及。当在旧任务上的表现降低时,这种办法也有助于防止消极学习。
动态网络的扩展
有选择性的再训练与更旧的任务高度相关。但是,当更新的任务有相当不同的分布时,它的训练就会开始失败。可以使用另一种技术来确保更新的数据可以通过增加网络的容量来表示。通过增加额外的神经元来做到这一点。
假设你希望通过k个神经元来扩展网络的第l层。这一层(和前一层)的新权重矩阵将看上去有些维度:
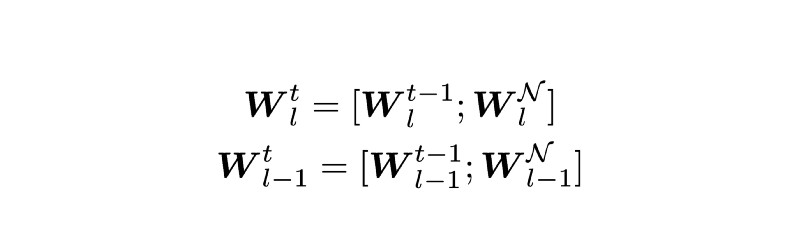 是在增加了k个神经元之后的神经元总数。
是在增加了k个神经元之后的神经元总数。
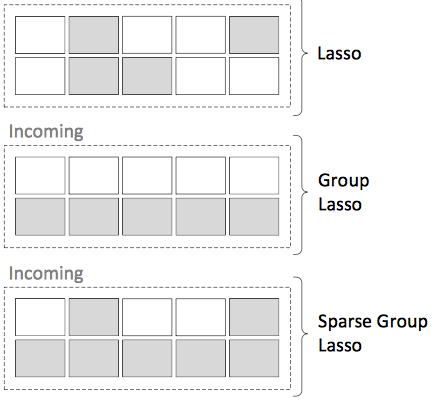
通常,我们不想增加k个神经元。我们只希望网络能够计算出正确的神经元数量。幸运的是,已经有一种现有的技术,使用Lasso来规范网络,使其拥有稀疏的权重(然后可以被删除)。这一技术在“对于深神经网络的Group Sparse正则化”这篇论文中得到了详细的描述。论文地址:https://arxiv.org/pdf/1607.00485.pdf
在一个层上使用Lasso会得到这样的结果(Group Lasso是被使用的技术):
网络分割/复制
在转移学习中有一个常见的问题,叫做语义漂移(semantic drift),或者是catastrophic forgetting,catastrophic forgetting的模型会慢慢地改变了它的权重,以至于忘记了最初的任务。
虽然它可以添加l2正则化确保权重不会发生显著变化,但如果新任务非常不同的话(模型在某个点之后就会失败),那么它就不会有帮助。
相反,如果它们在一定范围内移动的话,那么最好就要复制神经元。如果神经元的值超过一定的值,就会产生一个神经元的副本,并随之产生一个分裂,然后这个复制的单元被作为副本添加到同一层。
具体来说,对于一个隐藏的单元i,如果新权重和旧权值( ρ_i)之间的l2距离(i)是大于的,那么就会产生分裂。是一个超参数。在分割之后,整个网络将需要重新训练,但是收敛速度很快,因为初始化不仅是随机的,而且有一个合理的最优值。
训练和评估
三种数据集:
- MNIST-Variation:这个数据集包含62,000张从0到9的手写数字的图像。这些数字被旋转并在背景中有噪声(不像MNIST)。
- CIFAR-10:这个数据集包含6万张通用对象的图像,包括车辆和动物。
- AWA-Class:这个数据集包含了50种动物的30475张图片。
为了比较性能,我们使用了各种各样的模型。它们分别是:
- DDN-STL:一个深度神经网络,分别为每一项任务训练。
- DNN-MTL:一个为所有任务同时训练的DNN。
- DNN-L2:在当前任务和前一任务的权重之间,一种经过l2正则化训练的DNN。
- DNN-EWC:一个使用弹性的权重巩固训练的DNN。详细内容,参见:https://arxiv.org/pdf/1612.00796.pdf
- DNN-Progressive:详细内容,参见:https://arxiv.org/pdf/1606.04671.pdf
- DEN:动态可扩展的网络。
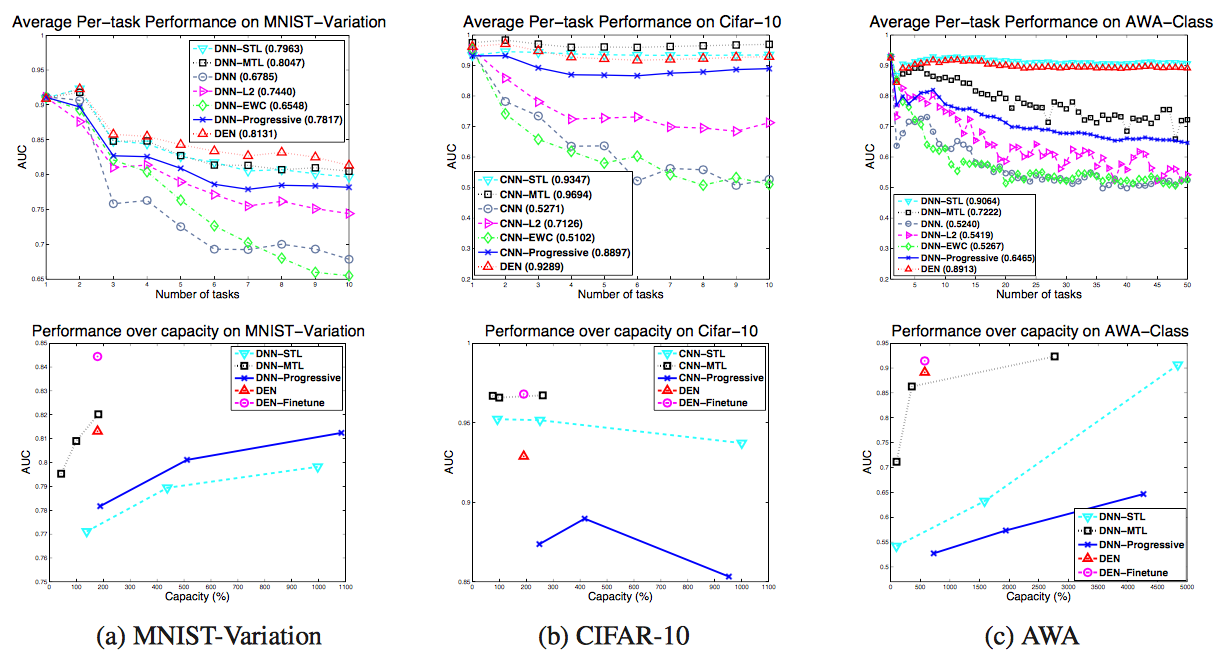
第一行:每个任务的平均性能 第二行:网络容量的性能。
很明显,DEN的准确性很好,同时也确保了它们不会浪费参数。









