











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






现代人工智能:为语言和图像构建ML分类器
2017年09月28日 由 xiaoshan.xiang 发表
308532
0
基于梯度的优化是现代人工智能的主要工作。使用线性网络——无论是ReLU还是maxout网络,LSTM网络,还是一个经过仔细配置的sigmoid网络,都没有足够的饱和——至少在训练集,我们能够拟合大部分我们所关心的问题,对抗样本的存在表明,能够解释训练数据,甚至能够正确地标注测试数据并不意味着我们的模型能够真正理解我们要求它们执行的任务。相反,它们对数据分布中没有出现的点的线性反应过于自信,而这些自信的预测往往是非常不正确的。Goodfellow的研究表明,我们可以通过明确识别问题点和在每一个点上纠正模型来部分地纠正这个问题。
神经网络的缺点是过度拟合,因此,ML工程师一直在寻找有效的正则化语言模型。人们意识到有两种标准的规范:
它们可以防止过度拟合,并在性能上增加1%或2%的改进。
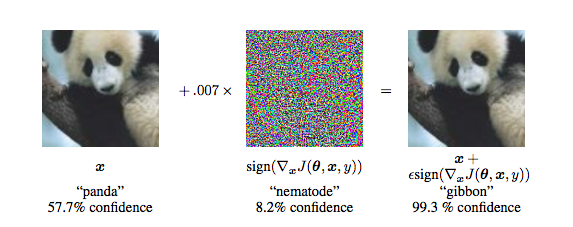
2015年,Ian Goodfellow提出了基于正则化技术的对抗样本。一个对抗样本是一个例子,该例子在添加了一小部分噪声时使模型错误分类。考虑如下图,如果你把左边的图像馈送给一个神经网络分类器,它将会被分类为“熊猫”,但是如果你馈送右边的图像,它将会被归类为“长臂猿”。
为了让分类器对这种对抗性的干扰产生强大的作用,Goodfellow建议在2015年ICLR(https://arxiv.org/pdf/1412.6572.pdf)的损失函数中增加一种对抗损失的成分。这比在训练集里加入噪声的例子要好得多,因为噪声实际上比对抗的干扰要弱得多,另一个原因是在高维的输入空间中,平均噪音向量与成本梯度是近似正交的。对抗性的干扰被选择用来持续增加成本。
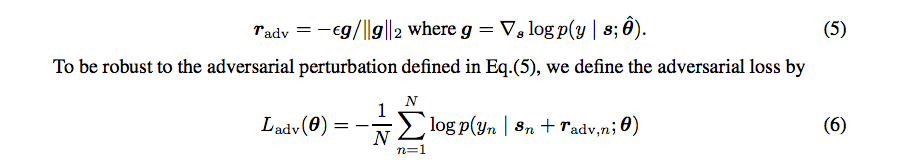
Goodfellow提出的技术依赖于训练标签,因此它只能应用于监督学习环境。2016年,Miyato提出了一种虚拟对抗性正则化(https://arxiv.org/abs/1507.00677)技术,该技术不依赖训练标签。这种类型的正则化可以在任何环境下应用。
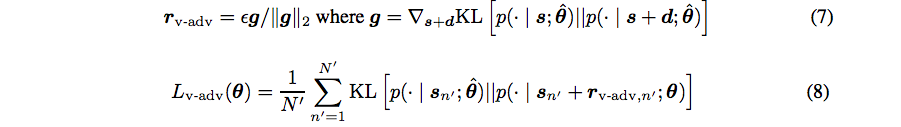
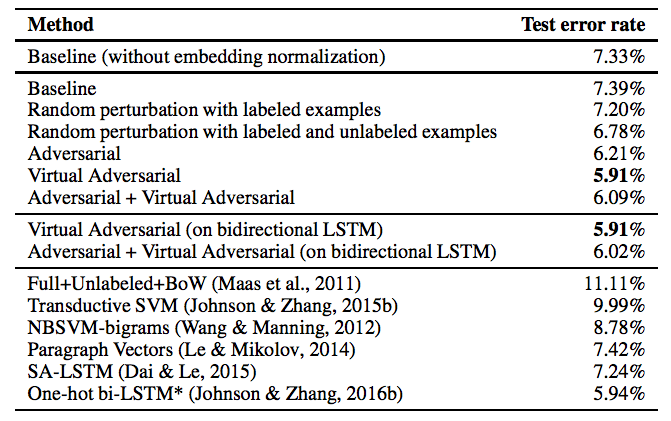
这些技术都能很好地处理像图像这样的连续数据,但在离散文本上表现很差。今年,Goodfellow和 Miyato通过文本分类任务的改进展示了如何使用文本的对抗性正则化技术(https://arxiv.org/pdf/1605.07725.pdf)。
我们可以利用这些技术来进一步改进现有的分类器。如果你对如何实现这些损失函数感兴趣,请查看(https://github.com/tensorflow/models/tree/master/adversarial_text)
神经网络的缺点是过度拟合,因此,ML工程师一直在寻找有效的正则化语言模型。人们意识到有两种标准的规范:
- Dropouts;
- L1 / L2正则化。
它们可以防止过度拟合,并在性能上增加1%或2%的改进。
2015年,Ian Goodfellow提出了基于正则化技术的对抗样本。一个对抗样本是一个例子,该例子在添加了一小部分噪声时使模型错误分类。考虑如下图,如果你把左边的图像馈送给一个神经网络分类器,它将会被分类为“熊猫”,但是如果你馈送右边的图像,它将会被归类为“长臂猿”。
为了让分类器对这种对抗性的干扰产生强大的作用,Goodfellow建议在2015年ICLR(https://arxiv.org/pdf/1412.6572.pdf)的损失函数中增加一种对抗损失的成分。这比在训练集里加入噪声的例子要好得多,因为噪声实际上比对抗的干扰要弱得多,另一个原因是在高维的输入空间中,平均噪音向量与成本梯度是近似正交的。对抗性的干扰被选择用来持续增加成本。
Goodfellow提出的技术依赖于训练标签,因此它只能应用于监督学习环境。2016年,Miyato提出了一种虚拟对抗性正则化(https://arxiv.org/abs/1507.00677)技术,该技术不依赖训练标签。这种类型的正则化可以在任何环境下应用。
这些技术都能很好地处理像图像这样的连续数据,但在离散文本上表现很差。今年,Goodfellow和 Miyato通过文本分类任务的改进展示了如何使用文本的对抗性正则化技术(https://arxiv.org/pdf/1605.07725.pdf)。
我们可以利用这些技术来进一步改进现有的分类器。如果你对如何实现这些损失函数感兴趣,请查看(https://github.com/tensorflow/models/tree/master/adversarial_text)

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消