











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






训练Tensorflow目标检测模型,制作人脸检测识别应用程序
2017年10月12日 由 xiaoshan.xiang 发表
180425
0
人工智能使得人脸检测识别程序成为可能。在这篇文章中,我将重点介绍一个带有自定义类别的人脸检测识别检测器。你要做的第一件事就是去设置它。这里有一个编写了如何在本地机器上进行设置的Tensorflow文档。文档地址如下:
我们将使用Tensorflow对象目标检测来训练一个实时对象识别应用程序。这个存储库中可以找到可以使用经过训练的模型:https://github.com/qdraw/tensorflow-face-object-detector-tutorial

你可以使用以下脚本在Ubuntu的/usr/local中自动安装OpenCV。该脚本安装OpenCV 3.2,并与Ubuntu 16.04一起使用。
在Mac上,我使用OpenCV 3.3.0 en Python 2.7.13。我尝试了OpenCV 3.2和3.3,但它们无法在Python 3.6中使用。可是,在Ubuntu Linux上,这种组合运行良好。
第一步是复制Tensorflow-models存储库。对于本教程,我们只使用slim和目标检测(object_detection)模块。
还需要编译protobuf库。
示例代码在tensorflow 人脸目标检测器教程存储库中可用。你可以复制这个repo。
转到子文件夹:
使用PIP安装依赖项:我使用Python 3.6和安装了绑定OpenCV的Python。
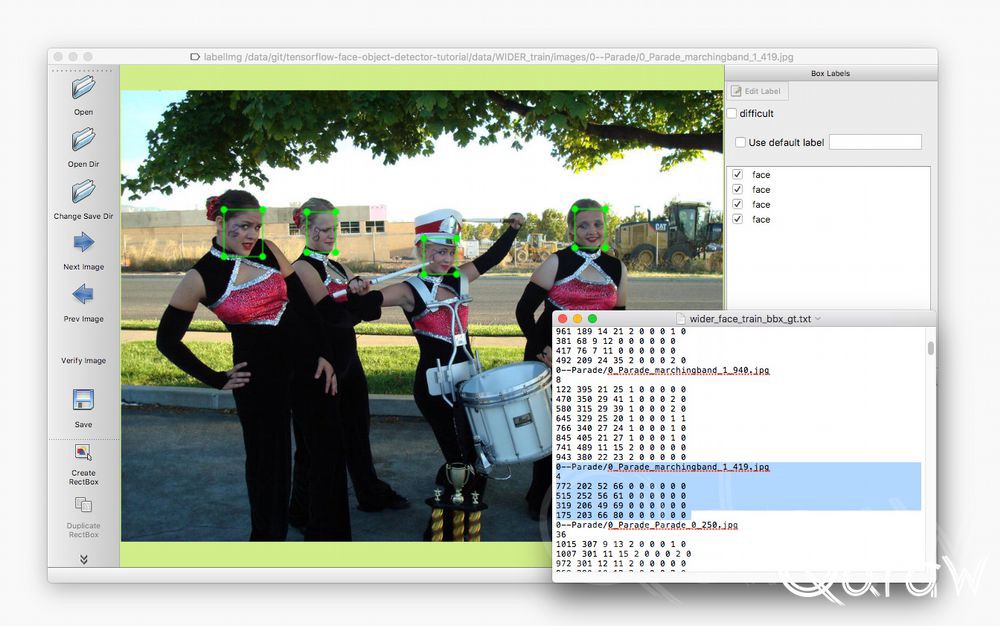
香港中文大学(Chinese University of Hong Kong)有大量的标注图像数据集。WIDER FACE数据集是一个人脸检测基准数据集。我用labelImg(https://github.com/tzutalin/labelImg)来显示边框。所选的文本是人脸检测注释。
001_down_data.py脚本将用于下载WIDERFace数据集(http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/)和ssd_mobilenet_v1_coco_11_06_2017(https://medium.com/@qdraw/how-to-train-a-tensorflow-face-object-detection-model-3599dcd0c26f#%20downloading%20from:%20https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md)。我将使用预先训练的模型来加速训练时间。
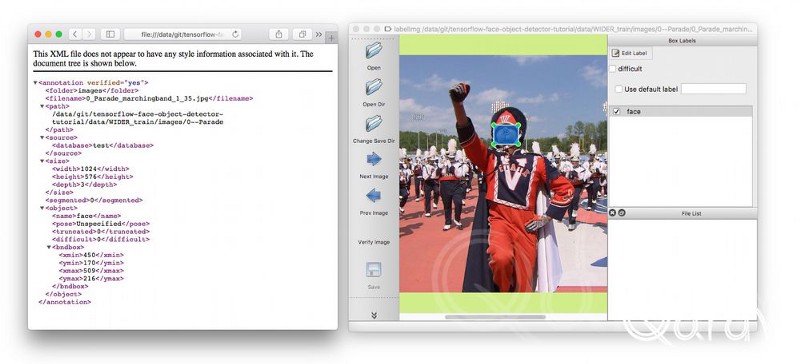
首先,我们需要将人脸检测数据集转换为Pascal XML。Tensorflow和labelImg使用不同的格式。这些人脸检测图像将下载到WIDER_train文件夹中。我们将使用002 _data-to-pascal-xml.py转换WIDERFace数据并且将数据复制到一个不同的子文件夹中。我的电脑需要5分钟处理9263张图片。
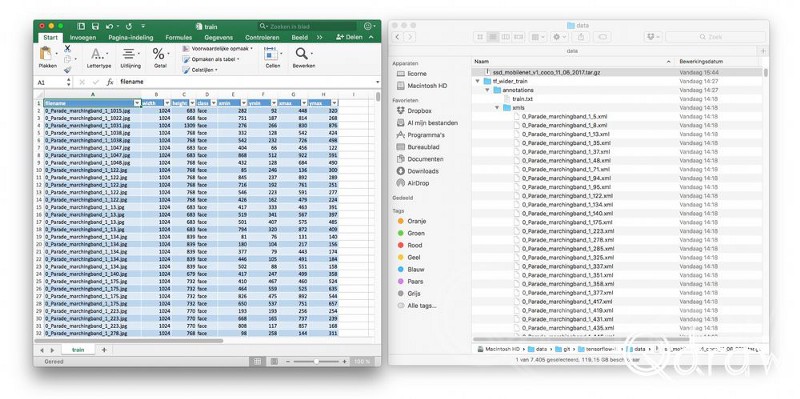
当数据转换为Pascal XML时,索引已经被创建。通过训练和验证数据集,我们将这些文件作为输入来制作TFRecords。也可以用labelImg这样的工具来手动标记图像,并使用这个步骤在这里创建一个索引。
$ python 003_xml-to-csv.py
TFRecords文件是一个大型的二进制文件,该文件被读取以训练机器学习模型。在下一步中,该文件将被Tensorflow按顺序读取。训练和验证数据将被转换成二进制文件。
TFRecord的训练数据(847.6 MB)
TFRecord 的验证数据(213.1MB)
在存储库中,ssd_mobilenet_v1_face.config文件用来训练人工神经网络的配置文件。该文件基于pet检测器。
在本例中,num_classes的数量仍然是一个,因为只有人脸才会被识别。
变量fine_tune_checkpoint用于指示以前模型的路径以获得学习。微调检查点文件(fine tune checkpoint file)在应用转移学习上被使用。转移学习是一种机器学习方法,它专注于将从一个问题中获得的知识应用到另一个问题上。
在类train_input_reader中,用带有TFRecord文件的链接以训练模型。在配置文件中,需要将其自定义到正确的位置。
变量label_map_path包含索引ID和名称。使用这个文件,0被用作占位符,所以我们从数字1开始。
验证有两个很重要的变量。在eval_config类中的变量 num_examples用于设置示例的数量。
eval_input_reader类描述了验证数据的位置。在这个位置也有一条路径。
此外,还可以改变学习速度、批量大小和其他设置。现在,我保留了默认设置。
现在,它将开始真正的工作。计算机将从人脸检测数据集中学习并建立一个神经网络。当我在CPU上模拟训练时,需要几天的时间才能得到一个好的结果。但强大的Nvidia显卡可以将时间缩短为几个小时。
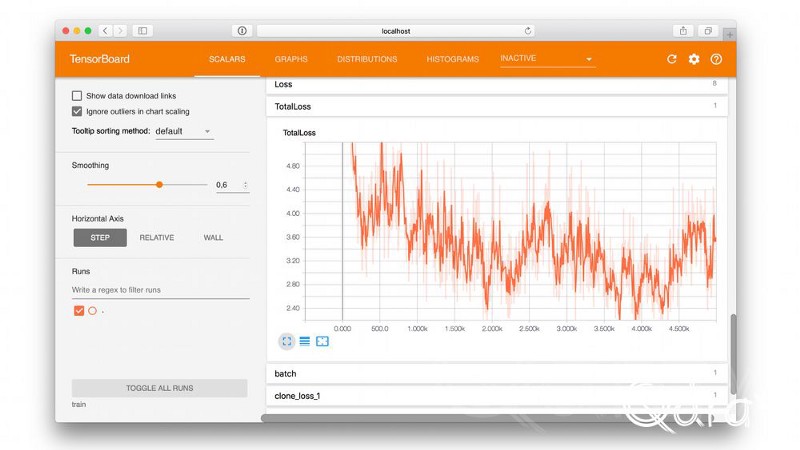
Tensorboard深入的了解了学习过程。该工具是Tensorflow的一部分,且可以自动安装。
在带有计算机视觉库Tensorflow目标识别检测中使用该模型。 以下命令提供了模型存储库的位置和最后一个检查点。文件夹文件夹将包含frozen_inference_graph.pb。
在github资料库中的模型/ frozen_inference_graph.github.pb文件夹是人工神经网络的一个冻结模型。香港中文大学(Chinese University of Hong Kong)有一个WIDERFace数据集,这个数据集已经被用来训练模型。
除了用于Tensorflow目标识别检测训练的数据外,还有一个评估数据集。基于此评估数据集,可以计算精度。对于我的模型,我计算了精度(平均精度)。我以14337步的速度获得了83.80%的分数(epochs)。对于这个过程,Tensorflow有一个脚本,使它可以在Tensorboard中看到分数是多少。除了训练之外,建议你运行评估过程。
然后可以使用Tensorboard监视进程。
https://github.com/tensorflow/models/blob/4f32535fe7040bb1e429ad0e3c948a492a89482d/research/object_detection/g3doc/installation.md
我们将使用Tensorflow对象目标检测来训练一个实时对象识别应用程序。这个存储库中可以找到可以使用经过训练的模型:https://github.com/qdraw/tensorflow-face-object-detector-tutorial
OpenCV
你可以使用以下脚本在Ubuntu的/usr/local中自动安装OpenCV。该脚本安装OpenCV 3.2,并与Ubuntu 16.04一起使用。
$ curl -L https://raw.githubusercontent.com/qdraw/tensorflow-object-detection-tutorial/master/install.opencv.ubuntu.sh | bash
在Mac上,我使用OpenCV 3.3.0 en Python 2.7.13。我尝试了OpenCV 3.2和3.3,但它们无法在Python 3.6中使用。可是,在Ubuntu Linux上,这种组合运行良好。
$ brew install homebrew/science/opencv
slim和目标检测(object_detection)模块的设置
第一步是复制Tensorflow-models存储库。对于本教程,我们只使用slim和目标检测(object_detection)模块。
$ nano .profile
export PYTHONPATH=$PYTHONPATH:/home/dion/models/research:/home/dion/models/research/slim
还需要编译protobuf库。
$ protoc object_detection/protos/*.proto --python_out=.
复制教程存储库并安装依赖项
示例代码在tensorflow 人脸目标检测器教程存储库中可用。你可以复制这个repo。
$ git clone https://github.com/qdraw/tensorflow-face-object-detector-tutorial.git
转到子文件夹:
$ cd tensorflow-face-object-detector-tutorial/
使用PIP安装依赖项:我使用Python 3.6和安装了绑定OpenCV的Python。
$ pip install -r requirements.txt
下载训练和验证数据
香港中文大学(Chinese University of Hong Kong)有大量的标注图像数据集。WIDER FACE数据集是一个人脸检测基准数据集。我用labelImg(https://github.com/tzutalin/labelImg)来显示边框。所选的文本是人脸检测注释。
001_down_data.py脚本将用于下载WIDERFace数据集(http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/)和ssd_mobilenet_v1_coco_11_06_2017(https://medium.com/@qdraw/how-to-train-a-tensorflow-face-object-detection-model-3599dcd0c26f#%20downloading%20from:%20https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md)。我将使用预先训练的模型来加速训练时间。
$ python 001_down_data.py
将WIDERFace转换为Pascal XML
首先,我们需要将人脸检测数据集转换为Pascal XML。Tensorflow和labelImg使用不同的格式。这些人脸检测图像将下载到WIDER_train文件夹中。我们将使用002 _data-to-pascal-xml.py转换WIDERFace数据并且将数据复制到一个不同的子文件夹中。我的电脑需要5分钟处理9263张图片。
$ python 002_data-to-pascal-xml.py
创建Pascal XML到Tensorflow CSV的索引
当数据转换为Pascal XML时,索引已经被创建。通过训练和验证数据集,我们将这些文件作为输入来制作TFRecords。也可以用labelImg这样的工具来手动标记图像,并使用这个步骤在这里创建一个索引。
$ python 003_xml-to-csv.py
创建TFRecord文件
TFRecords文件是一个大型的二进制文件,该文件被读取以训练机器学习模型。在下一步中,该文件将被Tensorflow按顺序读取。训练和验证数据将被转换成二进制文件。
TFRecord的训练数据(847.6 MB)
$ python 004_generate_tfrecord.py --images_path=data/tf_wider_train/images --csv_input=data/tf_wider_train/train.csv --output_path=data/train.record
TFRecord 的验证数据(213.1MB)
$ python 004_generate_tfrecord.py --images_path=data/tf_wider_val/images --csv_input=data/tf_wider_val/val.csv --output_path=data/val.record
设置配置文件
在存储库中,ssd_mobilenet_v1_face.config文件用来训练人工神经网络的配置文件。该文件基于pet检测器。
在本例中,num_classes的数量仍然是一个,因为只有人脸才会被识别。
变量fine_tune_checkpoint用于指示以前模型的路径以获得学习。微调检查点文件(fine tune checkpoint file)在应用转移学习上被使用。转移学习是一种机器学习方法,它专注于将从一个问题中获得的知识应用到另一个问题上。
在类train_input_reader中,用带有TFRecord文件的链接以训练模型。在配置文件中,需要将其自定义到正确的位置。
变量label_map_path包含索引ID和名称。使用这个文件,0被用作占位符,所以我们从数字1开始。
item {
id: 1
name: 'face'
}验证有两个很重要的变量。在eval_config类中的变量 num_examples用于设置示例的数量。
eval_input_reader类描述了验证数据的位置。在这个位置也有一条路径。
此外,还可以改变学习速度、批量大小和其他设置。现在,我保留了默认设置。
训练
现在,它将开始真正的工作。计算机将从人脸检测数据集中学习并建立一个神经网络。当我在CPU上模拟训练时,需要几天的时间才能得到一个好的结果。但强大的Nvidia显卡可以将时间缩短为几个小时。
$ python ~/tensorflow_models/object_detection/train.py --logtostderr --pipeline_config_path=ssd_mobilenet_v1_face.config --train_dir=model_output
Tensorboard深入的了解了学习过程。该工具是Tensorflow的一部分,且可以自动安装。
$ tensorboard --logdir= model_output
将检查点转换为protobuf
在带有计算机视觉库Tensorflow目标识别检测中使用该模型。 以下命令提供了模型存储库的位置和最后一个检查点。文件夹文件夹将包含frozen_inference_graph.pb。
$ python ~/tensorflow_models/object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path ssd_mobilenet_v1_face.config \
--trained_checkpoint_prefix model_output/model.ckpt-12262 \
--output_directory model/
TL; DR;
在github资料库中的模型/ frozen_inference_graph.github.pb文件夹是人工神经网络的一个冻结模型。香港中文大学(Chinese University of Hong Kong)有一个WIDERFace数据集,这个数据集已经被用来训练模型。
评估
除了用于Tensorflow目标识别检测训练的数据外,还有一个评估数据集。基于此评估数据集,可以计算精度。对于我的模型,我计算了精度(平均精度)。我以14337步的速度获得了83.80%的分数(epochs)。对于这个过程,Tensorflow有一个脚本,使它可以在Tensorboard中看到分数是多少。除了训练之外,建议你运行评估过程。
python ~/tensorflow_models/object_detection/eval.py --logtostderr --pipeline_config_path=ssd_mobilenet_v1_face.config --checkpoint_dir=model_output --eval_dir=eval
然后可以使用Tensorboard监视进程。
tensorboard --logdir=eval --port=6010

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消