


















AI如何用文字表达情绪——使用人工神经网络进行带情感识别的文本分类
本文将带你尝试,不使用文本复杂的矩阵转换将文本分类。本文是对3种方法的综合描述和比较,这些方法被用来对下面这些数据的文本进行分类。完整的代码可以在下面链接找到。
代码:https://github.com/Ankushr785/Emotion-recognition-from-tweets
数据集下载:https://www.atyun.com/uploadfile/2017/09/text_emotion.csv

自然语言处理
所谓自然语言处理,这就是让机器像人类一样理解人类语言。这包括辨别不同句子之间的感情联系,理解说话者的本意,最终产生与之相关意思一致的新句子,并汇总到一起等等。这听起来没什么难以理解的地方,所以我认为即使是初学者不必害怕它会过于复杂。
现在我们知道机器(和大数据)可以比文本字符串更好地处理数字模式,所以处理NLP问题的第一步是将单词转换为矢量,即矢量化。一旦完成,所有需要完成的都是使用矢量作为特征,并将文本处理问题转换为机器学习问题。在我们即将见证的特殊情况下,SVM(支持向量机),朴素贝叶斯分类器 (NBC)和Sigmoid层已经被用来解决同样的问题。我们比较所有这些算法。希望你能够了解上述算法以帮助了解本文另外,我也不太愿意解释SVM和朴素贝叶斯方法。不过你可以在任何地方找到,所以无需担心。
数据预处理

1.删除网址:URL不会帮助你确定句子的特征。他们只是一些该死的链接,跟着他们不会让你根据刚刚阅读的句子做一个很好的描述。在re包中提供了删除网址的方法。
2.删除正则表达式:URL带来了很多符号,如['@','#','%']称为正则表达式。有很多方法可以让这些符号在文本文档中被找到。比如在re包中提供了一个正则表达式查找表来解决这个问题。
3.词形还原:需要将同一页上类似(picking, pick), (motivation, motivate)等的所有单词列出。该NLTK库(Natural Language Toolkit)包含了单词词形还原的包(WordLemmatizer),通过提供全面的查找表解决这个问题。
4.删除重复字母:我希望我的机器能把“I loooove you!”转换为“I love you!”使用itertools包提供的去重函数可以解决这个问题。

矢量化SVM和NBC
SVM是关于在n维空间(n指向特征)创建不同类之间的最优超平面以支持矢量。对于我们的问题陈述,利用SVM的一个好方法是利用Tf-Idf(Term frequency, inverse document frequency)矢量化。
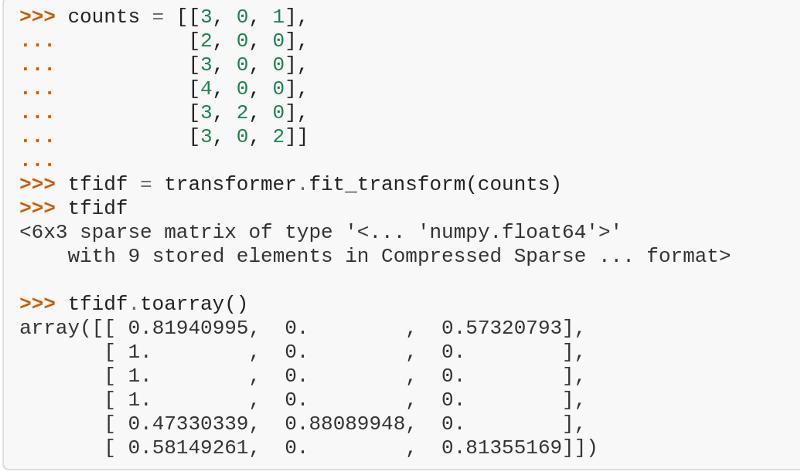
Tf-idf矢量化
如果你认为一个词袋的表示法只是计算每个文档中唯一单词的实例。那么你还是没有抓住重点。在分类过程中,整个语料库中的每个特定的词语(包括在我们的文本数据中的所有句子的组合)都会被给予相等的权重。我们的机器是还是个婴儿,它不会区分词语的重要性。
这个问题的解决方案是减少所有句子相当常见的单词的权重,并且在评估过程中增加不常见单词的权重。Scikit Learn的特征提取库提供了Tf-Idf函数来完成这个任务,对某个句子中的所有单词进行二次加权,并创建一个修改后的词袋。
ANN的矢量化
简单的词袋就足够了,复杂性会进一步下降。
简而言之:SVM和NBC方法
- SVM指向Scikit Learn的SVM软件包提供内置函数,将Tf-idf矢量直接提供给SVM内核。在这种情况下,选择了线性核函数是为了让结果更好。

Fed向量

SVM的模型
2. NBC指向朴素贝叶斯分类器需要直接输入文本和相应的标签。它假设样本句子的单词之间没有相互关系。因此,这个任务可以归结为简单地将一个情绪与一个基于单词数量和频率的句子联系起来。textblob库提供了一个全面的朴素贝叶斯分类器实现此功能。
ANN

我们已经建立了一个3层神经网络来解决这个问题。深度学习解决方案的原理是加深对句子的理解,也就是加强我们从句子中创建的向量和映射的情感之间的联系。我们希望机器排列单词理解并引导句子传达有意义的情感。在这里,建立了一个非常基础的神经网络,以更好地利用SVM和NBC提供的分类。我们来看看构建神经网络的不同的层。
- 输入层包含句子的词袋表示。让我们称之为“l0”。
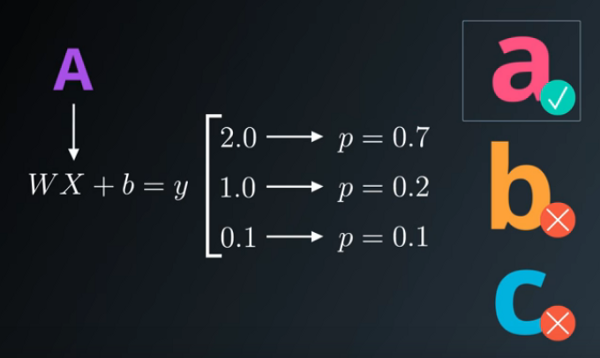
Logistic分类器
2.数据被馈送到转换为逻辑分类器(WX + b)的隐藏层。然而,偏置的向量“b”未被添加到该层中的矩阵点积“WX”。损失函数和(W,B)参数矩阵以矩阵形式储存在“突触”中,毕竟,这是我们正在谈论的是人工神经网络,我们应该打个比方!
3.然后,logistic分类器矩阵被缩放为sigmoid非线性(应对缩放问题)。这完成了我们的第二层-隐藏层“l1 = sigmoid_matrix_multiplication(l0,weight_parameters)”。
4.损失函数通过在训练数据上迭代一特定次数并使用SGD(随机梯度下降)优化,得到最佳参数矩阵“W”和“b”。
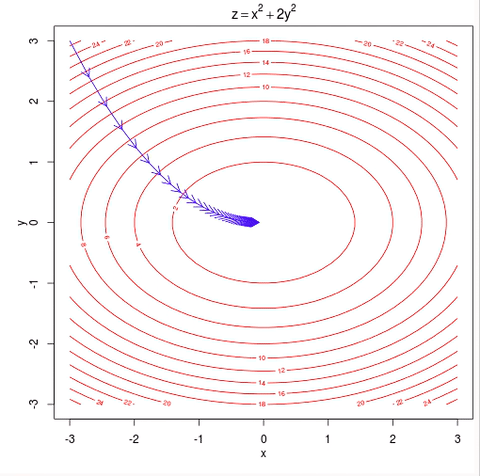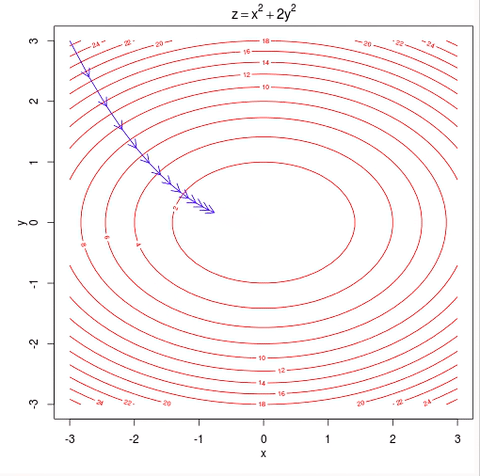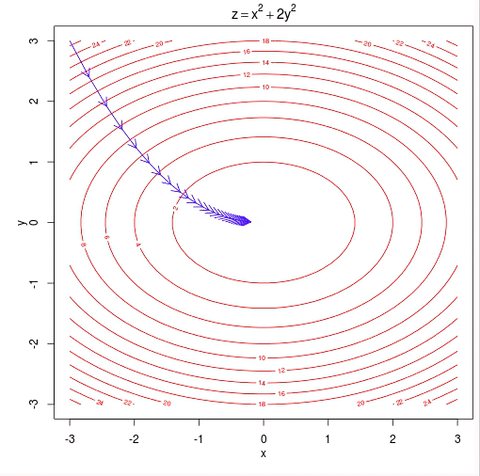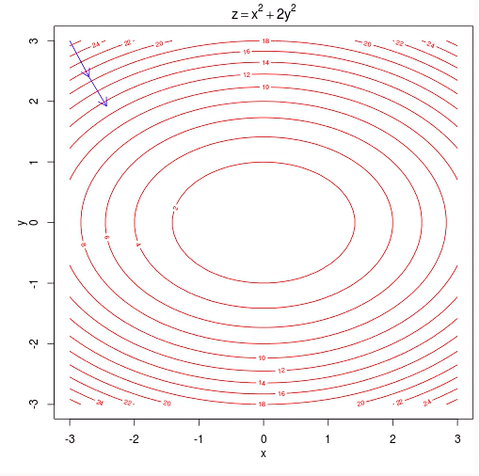
参数优化
5.第三层—输出层用于将SGD优化偏置项“b”添加到矩阵点积“WX”。你可以查看下面链接,了解为什么在这里进行分类是必要的。
(https://stackoverflow.com/questions/7175099/why-the-bias-is-necessary-in-ann-should-we-have-separate-bias-for-each-layer)

6.最后使用softmax函数将逻辑分数(logits)转换为概率。这些概率将给我们最接近特定情绪的感觉。
优化在完整数据上迭代指定的次数。如果本地迭代次数对错误减少没有任何影响,则迭代停止。
结果
以下是培训后获得的全部数据的15%。
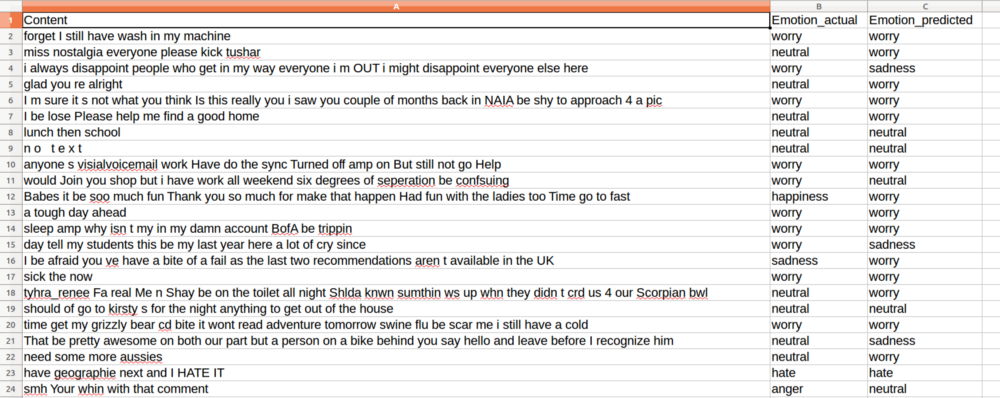
虽然非常规的ANN方法似乎并不优于传统的NBC和SVM方法,但是当你有大量数据需要处理时,它很有用,因为它能保持所有样本的强大记忆能力。









