


















伯克利人工智能新研究:通过最大熵强化学习来学习各种技能
深度强化学习(Deep reinforcement learning)在许多任务中都能获得成功。标准深度强化学习算法的目标是掌握一种解决给定任务的单一方法。因此,训练对环境中的随机性、策略的初始化和算法的实现都很敏感。图1展示了这一现象,它显示了两种优化回报函数(reward function)的策略,这些策略鼓励向前运动:虽然两种策略都趋向于一种高绩效的步态,但它们的步态却截然不同。

图1:训练模拟的行走机器人。图出处:Patrick Coady和Patrick Coady(OpenAI Gym)
为什么只发现单一的解决方案是不可取的呢? 因为只知道一种行为方式会使agent(指能自主活动的软件或者硬件实体)容易受到现实中常见的环境变化的影响。例如,想让一个机器人(图2)在一个简单的迷宫中导航到它的目标(蓝色X)。在训练时间(图2a)中,有两段通向目标的通道。该agent可能会通过上面的通道来解决这个问题,因为它看起来稍短一些。但是,如果我们通过阻塞上面的通道来改变环境(图2b),那么agent的解决方案就变得不可行的了。
由于在学习过程中,agent完全专注于上面的通道从而忽视了下面的通道。因此,要适应图2b中的新情况,需要agent重新从头开始重新学习整个任务。
 2a
2a

2b
图2:一个机器人在迷宫中导航
最大熵策略及其能量形式
让我们首先回顾一下强化学习:一个agent与环境相互作用,它是通过反复观察当前状态(state,简称s),采取一个行动(action,简称a),然后获得一个回报(reward,简称r)。agent使用(随机)策略(π)来选择行动,并找到最好的策略,从而最大化累积回报,该回报是agent在贯穿一个长度T的片段上收集的:
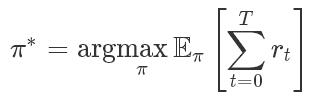
我们定义Q函数Q(s,a),作为一种状态s下的期望累积回报。让我们再次看一下图2a中这个机器人。当机器人处于初始状态时,Q函数可能看起来像图3a(灰色曲线)中描述的那样,有两种截然不同的模式。传统的强化学习方法是指定一个单向的策略分布,以最大Q值为中心,并扩展到邻近的行动,以提供探测(红色分布)的噪声。由于探测偏向上面的通道,所以agent在那里改良了策略,并且完全忽略了下面的通道。
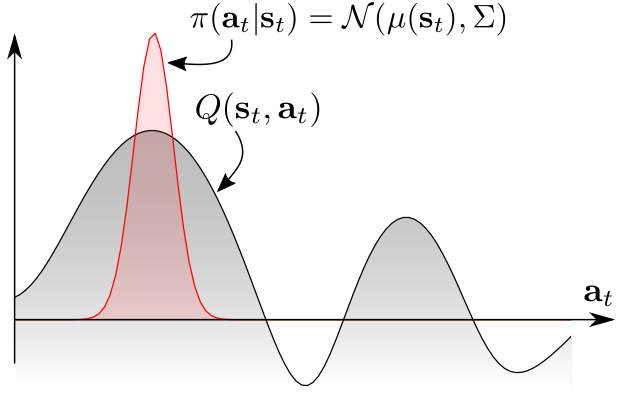
3a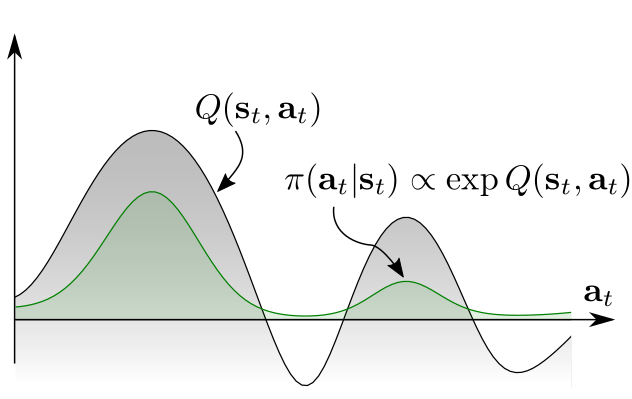
3b
图3:一个多峰的(multimodal)Q函数
在高层次上,一个明显的解决方案是,确保agent对所有有希望的状态进行探测,同时优先考虑更有希望的状态。形式化这个想法的一种方法是直接用指数化的Q值来定义策略(图3b,绿色的分布):
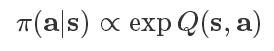
这个密度有一种“玻尔兹曼分布”形式,在这里,Q函数作为负能量,它为所有的行动分配了一个非零的可能性。因此,agent将会意识到所有引导解决任务的行动,这些行动可以帮助agent适应不断变化的情况,其中一些解决方案可能会变得不可行。但是,事实上,我们可以证明通过能量形式定义的策略是最大熵强化学习目标的最优方案。
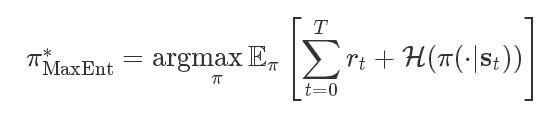
这仅仅是通过策略的熵来增加传统的强化学习目标(Ziebart 2010)。
学习这种最大熵模型的概念在统计模型中有它的起源,其目标是找到具有最高熵的概率分布,同时还能满足观测到的统计数据。例如,如果分布在欧氏空间中,观察的统计量是均值和协方差,那么最大熵分布是一个高斯分布,对应均值和协方差。在实践中,我们更喜欢最大熵模型,因为它们在与观测到的信息相匹配时,对未知量的估计最少。
柔性贝尔曼方程和柔性Q学习
通过使用柔性贝尔曼方程,我们可以获得最大熵目标的最佳解决方案
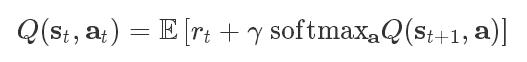
其中
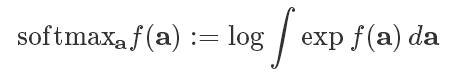
柔性贝尔曼方程可以被证明为熵增回报函数的最佳Q函数(例,Ziebart 2010)。但是,请注意与传统的贝尔曼方程的相似之处,它使用的是Q函数的硬性最大值,而不是柔性最大值。就像硬性的版本一样,柔性贝尔曼方程式是一个收缩,它在动作空间中可以用动态编程或无模型的时序差分学习方式来解决问题(例,Ziebart, 2008; Rawlik, 2012; Fox, 2016)。
然而,在连续域中,有两个主要的挑战。首先,精确的动态编程是不可行的,因为柔性贝尔曼的等式方程需要对每个状态和行为进行控制,并且softmax涉及到整个行动空间的集成。其次,最优策略是由难以处理的基于能源的分配所决定的。为了解决第一个挑战,我们可以使用具有表达能力的神经网络函数近似者,可以用随机梯度下降法对采样状态和动作进行训练,然后有效地推广到新的状态动作元组。为了解决第二个挑战,我们可以采用近似的推理技术,比如Markov chain Monte Carlo,在之前的基于能源的策略(Heess,2012)中已经讨论过。为了加速推理,我们使用了摊销的Stein变分梯度下降法(Wang and Liu, 2016)训练一个推论网络来生成近似样本。该算法被称为“柔性Q学习(soft Q-learning)”,结合了深度Q学习和摊销的Stein变分梯度下降法。
应用强化学习
既然我们可以通过柔性Q学习来学习最大熵的策略,我们可能会想知道这种方法的实际用途是什么? 在下面的部分中,我们将通过实验说明柔性Q学习允许更好的探测,允许在相似的任务之间进行策略转换,允许从现有的策略中轻松地组合新策略,并通过在训练时进行广泛的探索来提高鲁棒性。
更好的探索
柔性Q学习为我们提供了一种隐式的探测策略,通过将每个动作分配为非零概率,根据当前对其价值的可信度,有效地以一种自然的方式将探测和开发结合起来。为了看到这一点,让我们考虑一个类似于介绍中讨论过的两个通道的迷宫(图4)。任务是找到一种到目标状态的方法,用蓝色方块表示,并假设回报与目标的距离成比例。由于迷宫几乎是对称的,这样的回报会导致两种模式的目标,但只有一种模式对应于任务的实际解决方案。因此,在训练的时候探测这两个通道以发现这两者中哪一个最好是十分关键的。如果足够幸运,可以从一开始就尝试下面的通道,单模式策略只能解决这个问题。另一方面,多模式的柔性Q学习策略可以通过随机地跟随两个通道来解决任务,直到agent找到目标(图4)。

图4:接受柔性Q学习训练的策略可以在训练过程中探测这两个通道
最大熵微调策略
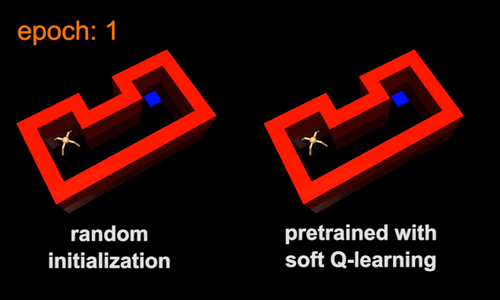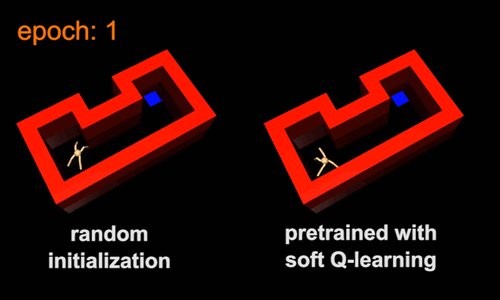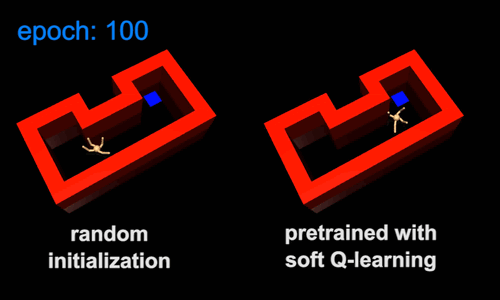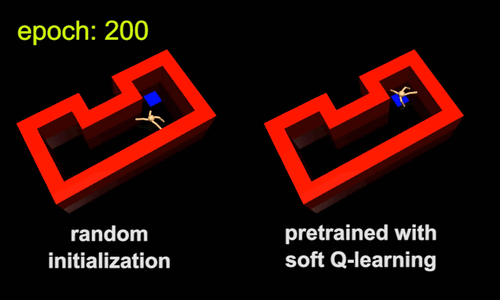
强化学习的标准做法是为每个新任务从头开始训练agent。这样的话,速度可能会很慢,因为agent会把之前任务中获取的知识扔掉。相反,agent可以从类似的之前的任务中转移技能,使它能够更快地学习新的任务。转移技能的一种方法是对通用任务进行预训练,然后将它们作为模板或初始化,以用于更具体的任务。例如,行走的技能包含了在迷宫中导航的技能,因此行走技能可以作为学习导航技能的有效初始化。为了展示这个想法,我们训练了一个最大熵的策略,此策略是不管agent行走的方向是怎样的,只要agent以高速行走,就会给它回报。由此产生的策略会学习走路,但不会因为最大熵目标(图5a)而尝试任何单一方向。接下来,我们将行走技能用于一系列导航技能,如图5b中的导航技能。在新任务中,agent只需要选择哪一种行为会使自己更接近目标,这比从头开始学习同样的技能要简单得多。传统的策略在接受一般任务时,将会收敛于特定的行为。比如,它可能只学会在一个方向上行走。因此,它不能直接将行走技能转移到迷宫环境中,因为这需要多个方向的运动。

5a
 5b
5b
图5:在新的环境中,最大熵预训练使agent能够更快地学习。与其他目标任务相同的预先训练过的策略的视频:https://www.youtube.com/watch?v=7Nm1N6sUoVs&feature=youtu.be
组合性
类似于“一般到特殊”的转移,我们可以从现有的策略中组合出新的技能——即使没有通过相交不同的技能来进行任何微调。其想法很简单:采取两种柔性策略,每一种都对应一组不同的行为,并将它们的Q函数组合在一起。实际上,可以通过简单地添加构成任务的回报函数,直到一个有界限的错误,从而证明组合策略对于组合任务来说是最优的。
下图有一个平面机械臂,左侧的两个agent接受了训练,将柱状物体移动到一个用红色条纹表示的目标位置。注意,这两个任务的解决方案空间是如何重叠的:通过将圆柱移动到条纹的交点,两个任务都可以同时得到解决。实际上,右边的策略是通过简单地将两个Q函数加在一起得到的,将圆柱移动到交叉处,而不需要为合并的任务明确地训练一个策略。传统的策略不会表现出相同的组合性属性,因为它们只能表示特定的、不一致的解决方案。

图6:将两个技能合并成一个新的技能
鲁棒性
由于最大熵公式鼓励agent尝试所有可能的解决方案,所以这些agent会去探索很大一部分的状态空间。因此,它们学会了在各种情况下采取行动,并更有力地应对环境中的干扰。为了说明这一点,我们训练了一个Sawyer机器人,通过指定一个目标末端执行器的姿势,把乐高积木堆在一起。图7显示了训练期间的一些快照。

图7:用柔性Q学习来堆叠乐高积木的训练。图出处:Aurick Zhou
机器人在30分钟后第一次成功;一个小时后,它就能连续地堆叠出这些块;两小时后,这个策略就完全聚合了。聚合策略也很有鲁棒性,就像下面的动图中所显示的那样,在这种情况下,机械臂对与在正常执行过程中遇到的配置非常不同的配置进行干扰,并且每次都能成功地恢复。

图8:经过训练的策略对干扰有鲁棒性
据我们所知,只有很少的几项工作在现实世界的机器人上展示了成功的无模型强化学习。Rusu等人(2016)使用强化学习训练机器人手臂到达俄罗斯红场,并在模拟中进行训练。Veerk等人(2017)表示,如果从演示中初始化,Sawyer机器人可以在大约30分钟的体验中执行一种插入式的任务。值得注意的是,我们的柔性Q学习结果,如上所示,只使用了一个机器人进行训练,并且没有使用任何模拟或演示。









