


















适合开发者的深度学习:第一天就能使用的编码神经网络工具
当前的深度学习浪潮在五年前就开始了。深度学习是驱动汽车的技术,也可以在Atari游戏中击败人类,甚至能够诊断癌症。
深度学习是机器学习的一个分支。它被证明是一种可以在原始数据中找到模式(比如图像或声音)的有效方法。如果说你想要在没有特定编程的情况下对猫和狗进行分类,首先它会在图片中找到物体对象的边缘,然后从中构建了模式,接下来,它会检测鼻子、尾巴和爪子。这使得神经网络能够对猫和狗进行最终分类。
但是,对于结构化数据,有更好的机器学习算法。例如,如果你有一个带有消费者数据的excel表格,并且想要预测他们的下一个订单,你可以使用更简单的机器学习算法。如下:
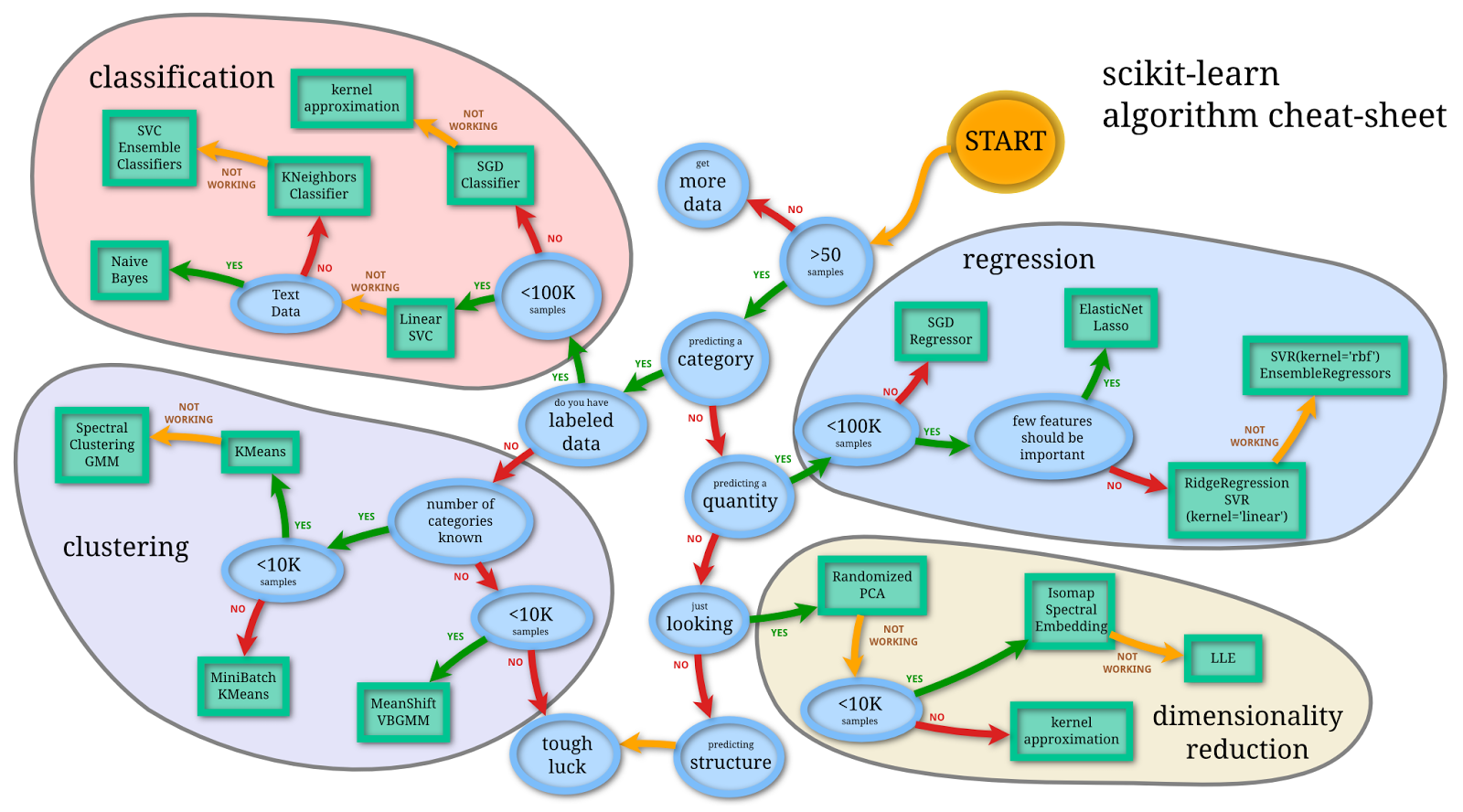
核心逻辑
假设有一个随机调整齿轮的机器。这些齿轮层叠在一起,它们互相影响。在最开始的时候,这台机器不工作。齿轮层是随机调整的,它们都需要调整以给出正确的输出。然后,工程师将检查所有的齿轮,并且标记出是哪些齿轮造成了错误。从最后一层齿轮开始检查,因为这是所有错误造成的结果层。一旦工程师知道是上一层造成的错误的话,他就会逆向工作。这样他就能计算出每一个齿轮对误差起得作用有多少。我们把这个过程称为反向传播算法(back propagation)。
工程师会根据每个齿轮的错误进行调整,然后再次运行机器,直到机器给出正确的输出。
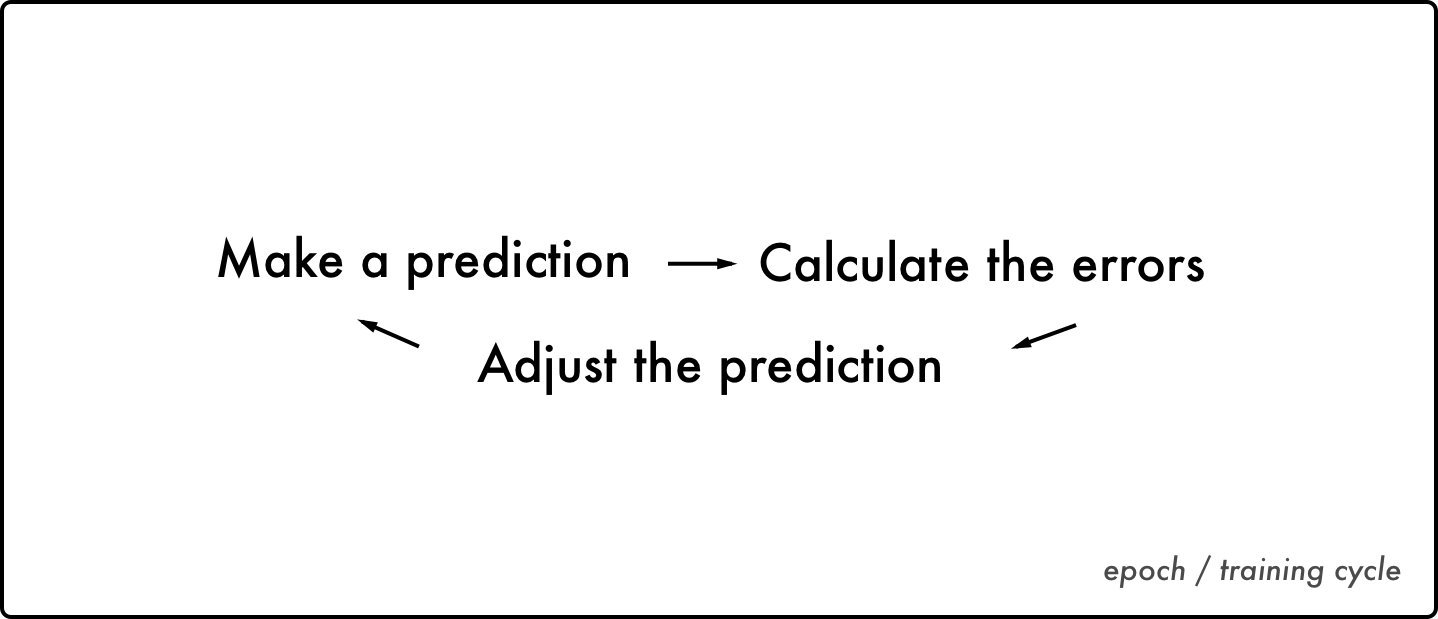
训练循环顺序:作出预测→计算错误→调整预测→作出预测
神经网络以同样的方式运作。它知道输入和输出并调整齿轮以找到两者之间的相关性。给定一个输入,它会调整齿轮来预测输出。然后,它将预测值与实际值进行比较。
差异介于预测值和实际值之间。为了将错误最小化,神经网络对齿轮进行调优,直到预测值和实际值之间的差异尽可能地降低。
梯度下降(gradient descent)是将误差最小化的最优方式。误差是由误差/成本函数计算的。
一个浅层的人工神经网络
许多人认为人工神经网络是我们大脑皮质的数字复制品。这不是真实的。这是Frank Rosenblatt的灵感来源,他是神经网络的发明者。

用一个或两个小时时间操作神经网络模拟器来理解它。首先,我们将实现一个简单的神经网络,以了解TFlearn中的语法(syntax)。在TFlearn中,最经典的101问题是OR operator。尽管神经网络更适合于其他类型的数据,但这个问题对于理解它是如何工作的是非常好的。
所有的深度学习项目都遵循同样的核心逻辑:
- 它从库开始,然后导入和清洗数据。不管是图像、音频还是感官数据,所有输入都被转换成数字。这些长长的数字列表是我们神经网络的输入。
- 现在设计你的神经网络,选择类型还有在你的网络中层数。
- 然后让它进入学习过程。它知道输入和输出值,并搜索它们之间的相关性。
- 最后一步是给你训练的神经网络做一个预测。
以下是我们的神经网络的代码:
# 1. Import library of functions
import tflearn
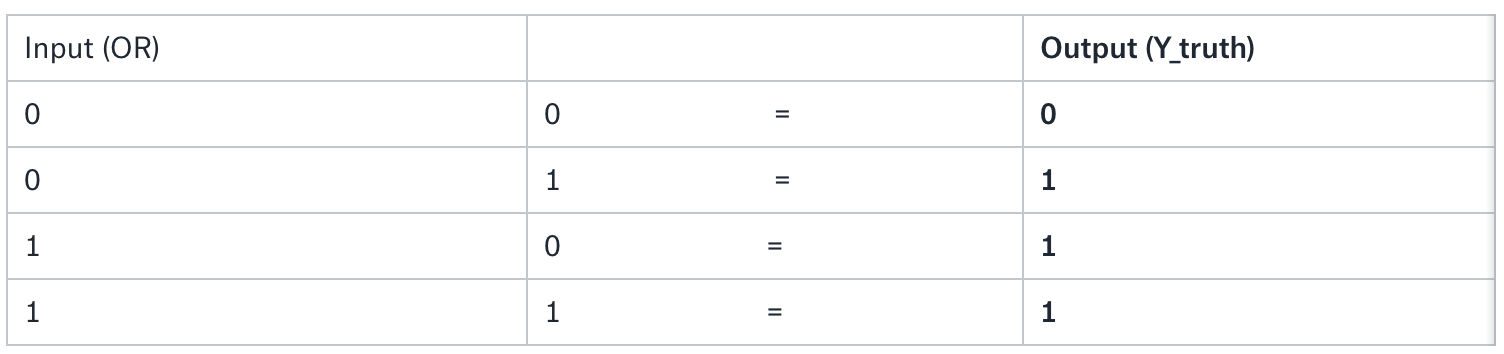
# 2. Logical OR operator / the data
OR = [[0., 0.], [0., 1.], [1., 0.], [1., 1.]]
Y_truth = [[0.], [1.], [1.], [1.]]
# 3. Building our neural network/layers of functions
neural_net = tflearn.input_data(shape=[None, 2])
neural_net = tflearn.fully_connected(neural_net, 1, activation='sigmoid')
neural_net = tflearn.regression(neural_net, optimizer='sgd', learning_rate=2, loss='mean_square')
# 4. Train the neural network / Epochs
model = tflearn.DNN(neural_net)
model.fit(OR, Y_truth, n_epoch=2000, snapshot_epoch=False)
# 5. Testing final prediction
print("Testing OR operator")
print("0 or 0:", model.predict([[0., 0.]]))
print("0 or 1:", model.predict([[0., 1.]]))
print("1 or 0:", model.predict([[1., 0.]]))
print("1 or 1:", model.predict([[1., 1.]]))
输出:
Training Step: 2000 | total loss: 0.00072 | time: 0.002s
| SGD | epoch: 2000 | loss: 0.00072 -- iter: 4/4
Testing OR operator
0 or 0: [[ 0.04013482]]
0 or 1: [[ 0.97487926]]
1 or 0: [[ 0.97542077]]
1 or 1: [[ 0.99997282]]
代码图片版: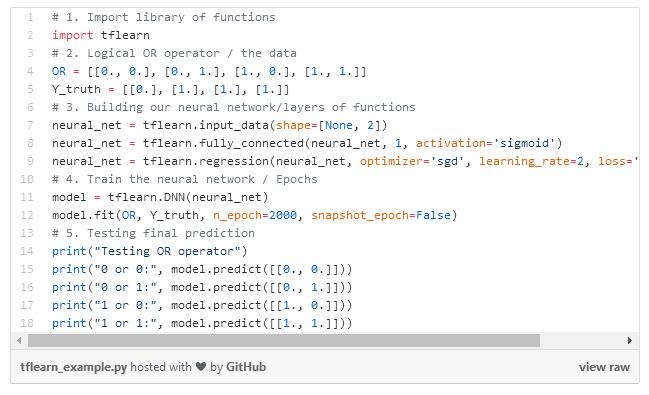
第一行:代码开始时是注释,用来解释代码。
第二行:包含TFlearn库,这让我们可以从谷歌的Tensorflow中使用深度学习功能。
第五到六行:表格中数据存储在列表中,每个数字末尾的点将每个整数映射为浮点数。它使用十进制值存储数字,使计算精确。
第九行:初始化神经网络并指定输入数据的维度或形状。每一个OR operator都是成对的,因此它有一个“2”的形状。它们中没有默认值,并且代表了批处理大小。
第十行:输出层。激活函数将在一个间隔内的层上的输出映射。在我们的例子中,我们使用了一个映射值在0到1之间的Sigmoid函数。阅读更多关于第9行和第10行的内容,地址:http://tflearn.org/layers/core/。
第十一行:应用回归。优化器选择哪种算法来最小化成本函数。学习速率决定了修改神经网络的速度,而损失变量决定了如何计算错误。
第十四行:选择使用哪个神经网络。它还用于指定存储训练日志的位置。
第十五行:训练你的神经网络和模型。选择你的输入数据(或)和真正的标签(Y_truth)。Epochs会通过神经网络来决定所有数据运行的次数。如果你设置快照=True,那么它会在每个阶段之后验证模型。
第十八到二十二行:用你的训练模型做出预测。
阅读更多关于第十四到二十二行的内容。地址:http://tflearn.org/models/dnn/。
输出标签:第一个结果意味着组合[0.]&[0.]有4%的概率为真实的。训练步骤显示出你训练了多少批次。
因为数据可以适应一个批处理,所以它和Epoch是一样的。如果数据对于内存来说太大的话,你就需要把训练分解成块。损失衡量的是每个epoch的错误总和。
SGD代表随机梯度下降和使成本函数最小化的方法。
Iter将显示当前的数据索引和输入项的总数。
你可以在几乎所有TFlearn的神经网络中找到上述的逻辑和语法。了解代码的最佳方法是修改它并创建几个错误。
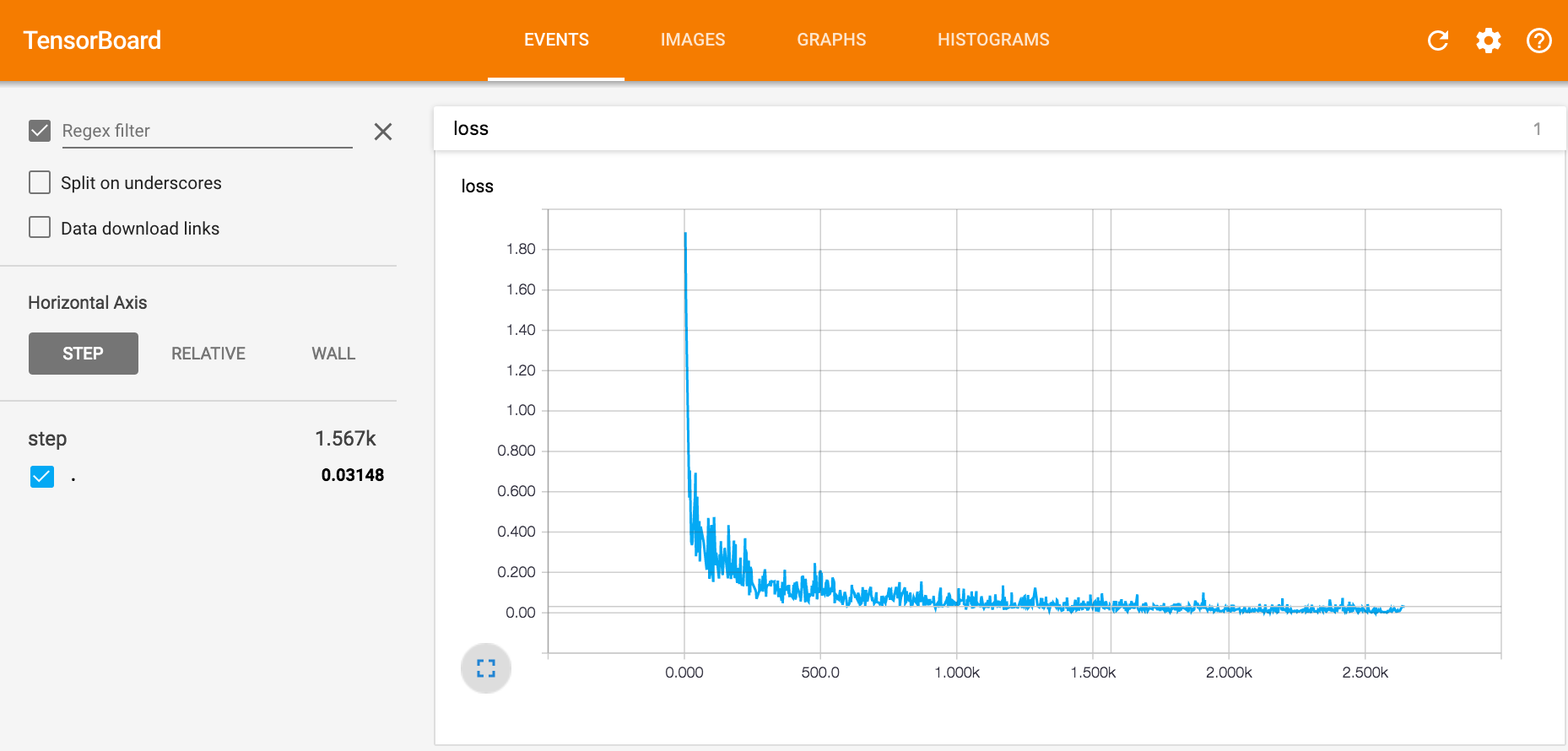
损失曲线显示每个训练步骤的错误数量
使用Tensorboard时,你可以形象化每一个实验,并建立一个直觉来判断每个参数是如何改变训练的。下面是一些你可以运行的示例的建议。我建议你花几个小时来适应环境和TFlearn参数。
实验
- 增加训练和epochs
- 尝试从文档中添加和更改一个参数到每个函数。例如,g = tflearn.fullyconnected(g, 1, activation=’sigmoid’)变成tflearn.fullyconnected(g, 1, activation=’sigmoid’, bias=False)
- 在输入数据中添加整数
- 在输入层中改变形状
- 在输出层中更改激活函数
- 对梯度下降使用不同的方法
- 改变神经网络计算成本的方式
- 改变X和Y,而不是逻辑运算符
- 将输出数据更改为XOR逻辑运算符。例如,从[1.]到[0.]交换最后的Y_truth。你需要在你的网络中添加一个图层让它运行
- 使它学得更快
- 找到一种方法让每一个学习步骤都超过0.1秒
开始
Python与Tensorflow结合是深度学习中最常见的堆栈。TFlearn是一个在Tensorflow上运行的高级框架。另一个常见的框架是Keras。它是一个更具有鲁棒性的库,但是我发现TFlearn语法更容易理解。它们都是在Tensorflow上运行的高级框架。
你可以在电脑的CPU上运行简单的神经网络。但是大多数的实验需要几个小时甚至几周的时间才能运行。这就是为什么大多数人使用现代GPU进行深度学习的原因,通常是通过云服务的途径。
对于云GPU来说,最简单的解决方案是使用FloydHub。如果你有基本的命令行技能,那么设置它不需要超过5分钟。
使用FloydHub docs来安装floyd-cli命令行工具。如果你在安装时被困在任何地方,FloydHub会在他们的内部通话聊天中提供支持。
这有一个Floydhub的安装视频,并且使用了TFlearn、Jupyter Notebook和Tensorboard来运行。
[video width="1152" height="720" mp4="https://www.atyun.com/uploadfile/2017/10/videoplayback.mp4"][/video]
视频地址:https://www.youtube.com/watch?v=byLQ9kgjTdQ
让我们使用TFlearn、Jupyter Notebook和Tensorboard来运行你的第一个神经网络。在安装和登录到FloydHub之后,下载你需要的文件。然后,到你的终端,输入以下命令:
git clone https://github.com/emilwallner/Deep-Learning-101.git
打开文件夹,并启动FloydHub:
cd Deep-Learning-101
floyd init 101
在你的浏览器中,FloydHub将会打开web面板,你将会被提示创建一个名为101的新的FloydHub项目。完成之后,返回到你的终端并运行相同的init命令。
floyd init 101
现在,你可以在FloydHub上运行你的神经网络了。通过floyd runcommand,你可以进入不同的设置。在我们的案例中,我们想要:
- 在FloydHub上架置一个我已经上传的公共数据集。在数据目录类型(data directory type)——data emilwallner/datasets/cifar-10/1:data中可以找到。你可以通过在FloydHub上浏览它探索该数据集(以及许多其他公共数据集)
- 使用云GPU——GPU
- 使用Tensorboard——Tensorboard
- 在Jupyter Notebook模式下运行——mode jupyter
好了,让我们来运行:
floyd run --data emilwallner/datasets/cifar-10/1:data --gpu --tensorboard --mode jupyter
一旦它在你的浏览器中启动了Jupyter,那么点击名为start-here.ipnyb的文件。start-here.ipnyb是一个简单的神经网络,可以了解在TFlearn中的语法。它学习OR operator的逻辑,稍后会做出详细解释。
在菜单行中,单击Kernel > Restart & Run All。如果你看到了这个信息,那么就证明它是有效的,你就可以继续操作。
然后,到你的FloydHub项目中去寻找Tensorboard的链接。
一个深度神经网络
深度学习是一种有多个隐藏层的神经网络。关于卷积神经网络的工作,已经有了很多详细的教程。
教程地址:
1.https://www.youtube.com/watch?v=FmpDIaiMIeA&t=1202s
2.http://cs231n.github.io/convolutional-networks/
3.https://www.youtube.com/watch?v=LxfUGhug-iQ
所以,我们将集中讨论你可以应用到大多数神经网络的高级概念。
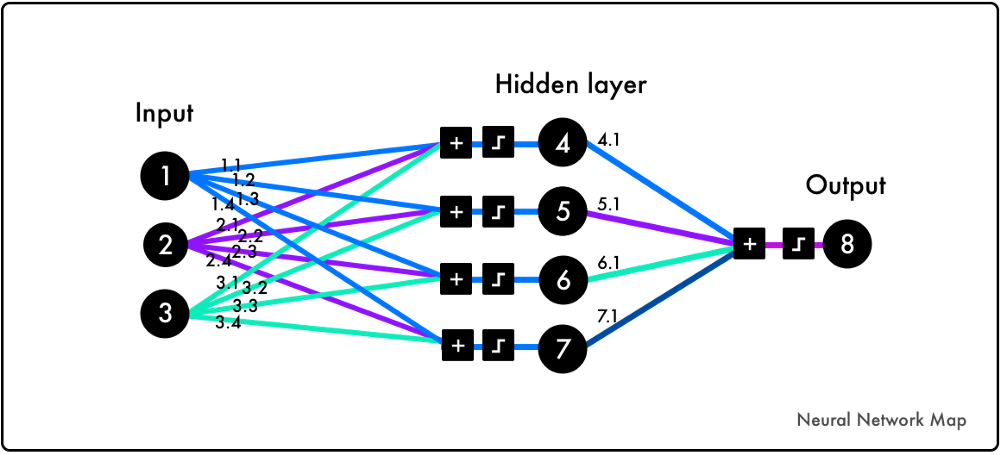
注意:可视化并不是一个深度神经网络,它需要一个以上的隐藏层
你需要训练神经网络来预测它没有经过训练的数据,它需要一种概括的能力。这是学习(learning)和遗忘(forgetting)之间的平衡。
你想让它学会把信号从噪音中分离出来,但也要忘记在训练数据中发现的信号。如果神经网络学习得不充分,那就不合适了。相反的是过度拟合。
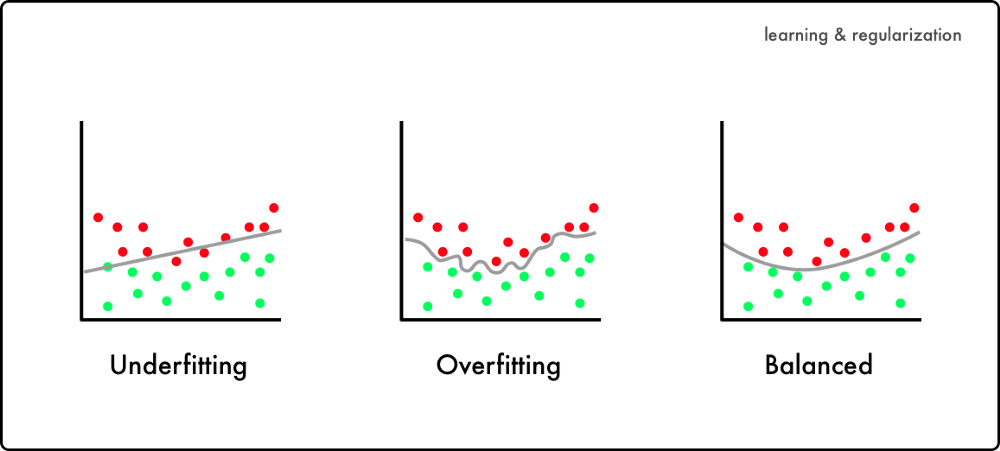
正则化是通过忘记训练特定的信号来减少过度拟合的过程。为了直观地理解这些概念,我们将使用CIFAR-10数据集。它是一个在10个不同的类别中有6万张图片的数据集,比如汽车、卡车和鸟类等等。它的目标是在10个类别中预测新图像所属于哪一个类别。

CIFAR中的样本图片
通常情况下,我们必须刮掉数据,清洗它,并对图像应用过滤器。但是为了缩小它的范围,我们只关注神经网络。你可以在安装部分的Jupyter Notebbok上运行所有示例。地址:https://github.com/emilwallner/Deep-Learning-101
输入层获取一个已被映射到数字的图像。输出层将图像分为10个类别。隐藏层是由卷积、汇聚和连接的层组成的。
选择图层的数量
让我们将一个与三组图层的神经网络进行比较。每个集合包括一个卷积、池和连接的层。
前两个实验被称为experiment-0-few-layers.ipynb和experiment-0-three-layer-sets.ipynb。
# Convolutional network building
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
# One set of layers
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu')
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
你可以通过点击Kernel > Restart & Run All菜单栏来运行这些Nootebook。然后看一下Tensorboard的训练日志。你会发现,有很多层的准确率要高于15%。没有很多的层是不合适的,这证明了它没有进行足够的学习。
你可以在前面下载的文件夹中运行相同的示例,以及所有即将进行的实验。
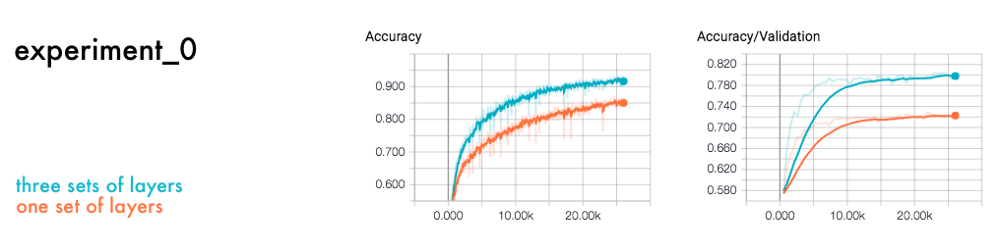
repo中的experiment_0.ipynb
看一看精确性和准确性/有效性(Accuracy和Accuracy/Validation)。在深度学习中,将数据集一分为二是最好的实践。一种是训练神经网络,另一种是验证神经网络。这样你就可以知道神经网络对新数据的预测或者它的泛化能力有多好。
正如我们所看到的,训练数据的精确性高于验证数据集的准确性。神经网络包括背景噪音和阻碍它预测新图像的细节。为了解决这个问题,你可以惩罚复变函数,并在神经网络中引入噪声。为了防止这一现象的发生,常用的正则化技术是dropout层,并对复变函数进行惩罚。
Dropout层
我们可以将dropout正则化与民主(democracy)的价值进行比较。它们没有很多强大的神经元来决定最终的结果,而是分配了权力。
神经网络被迫学习几种独立的表达方式。当它做出最终的预测时,它有几个不同的模式可供学习。这有一个有着dropout层的神经网络的例子。
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu')
#The dropout layer
network = dropout(network, 0.5)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
在这个比较中,除了一个有dropout层而另一个没有之外,它们的神经网络是一样的。
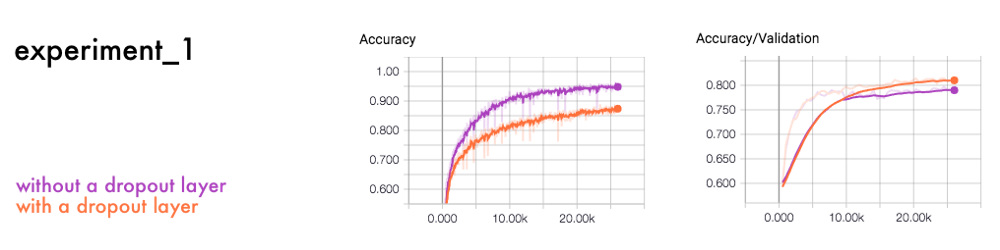
在神经网络的每一层,神经元相互依赖。有些神经元比其他神经元更有影响力。而dropout层会随机地对不同的神经元进行不同的测试。这样,每个神经元都必须对最终的输出做出不同的贡献。
第二种防止过度拟合的方法是在每一层上应用L1或L2正则化函数。
L1和L2正则化
假设你想描述一匹马。如果描述得太详细,你就排除了太多数样子的马。但是,如果说得太笼统的话,你可能会把其他动物也包括在内。L1和L2正则化可以帮助网络进行区分。
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='relu', regularizer='L2')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu', regularizer='L2')
network = conv_2d(network, 64, 3, activation='relu', regularizer='L2')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu', regularizer='L2')
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
如果我们像之前的实验一样做一个类似的比较,我们会得到一个相似的结果。
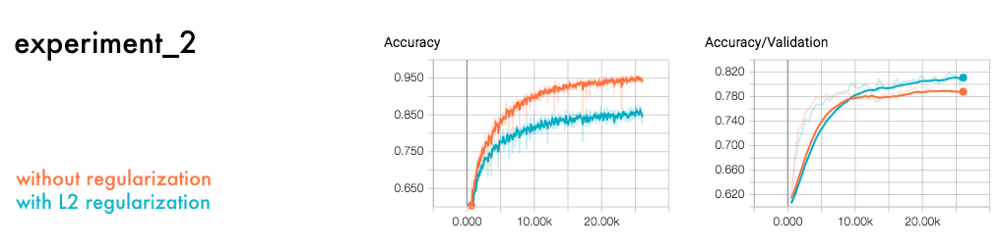
具有正则化函数的神经网络在没有它们的情况下表现得更出色。正则化函数L2惩罚的功能过于复杂。它度量每个函数对最终输出的贡献。然后它会惩罚有大系数的那些。
批量大小
另一个核心超参数是批处理大小,它是每个训练步骤所使用的数据量。下面是大批量和小批量大小的比较。
#Large batch size
model.fit(X, Y,
n_epoch=50,
shuffle=True,
validation_set=(X_test, Y_test),
show_metric=True,
batch_size=2000,
run_id='cifar_large_batch_size')
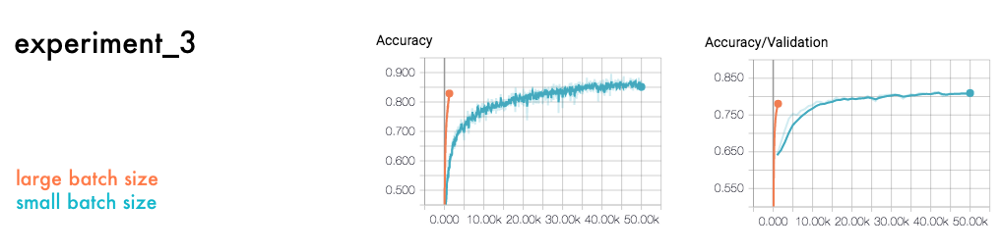
正如我们在结果中看到的,一个大批处理需要更少的周期,但是有更精确的训练步骤。相比之下,较小的批处理更随机,但需要更多的训练步骤。
此外,虽然大量的批处理需要更少的学习步骤。但是,你需要更多的内存和时间来计算每一步。
学习速率
最后一个实验是对一个具有小、中、大学习速率的网络进行比较。
#Large learning rate
network = regression(network,
optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.01)
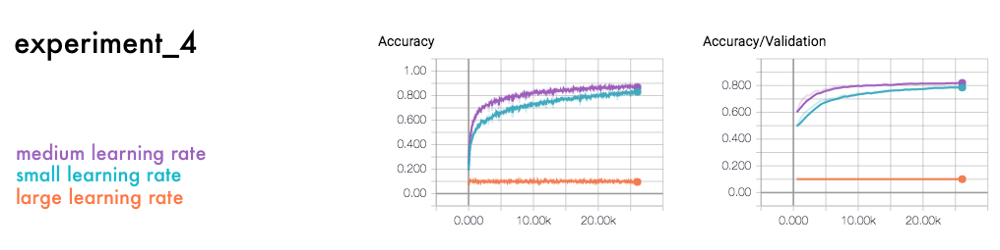
学习速率通常被认为是最重要的参数之一。它调节了如何在每个学习步骤中调整预测的变化。如果学习速率过高或过低,它可能不会收敛,就像上面的大的学习速率一样。
设计神经网络并没有固定的方法,很多都和实验有关。如果你能够访问大量计算能力,你可以创建程序来设计和优化超级参数。当你完成了你的工作后,你应该spin down你的云GPU实例。做法是在FloydHub web仪表盘中点击取消。
接下来可以做些什么?
在TFlearn的官方示例repo中,你可以切身体会一些表现最好的卷积神经网络。尝试复制一些方法,并改进CIFAR-10数据集的验证。repo地址:https://github.com/tflearn/tflearn/tree/master/examples/images。









