











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






利用面部识别算法和卷积神经网络的迁移学习,分析朝鲜海报上的人物性别分布
2017年10月23日 由 yining 发表
524174
0
本文将利用面部识别算法和应用于卷积神经网络的迁移学习,从而简要的分析朝鲜人民的性别分布。
几个月前,荷兰莱顿大学的Koen de Ceuster教授组织了一场关于朝鲜海报的研讨会。海报主要来自于个人私藏。Ceuster教授将这些海报进行数字化,现在它们已经作为莱顿大学的数字收藏的一部分。
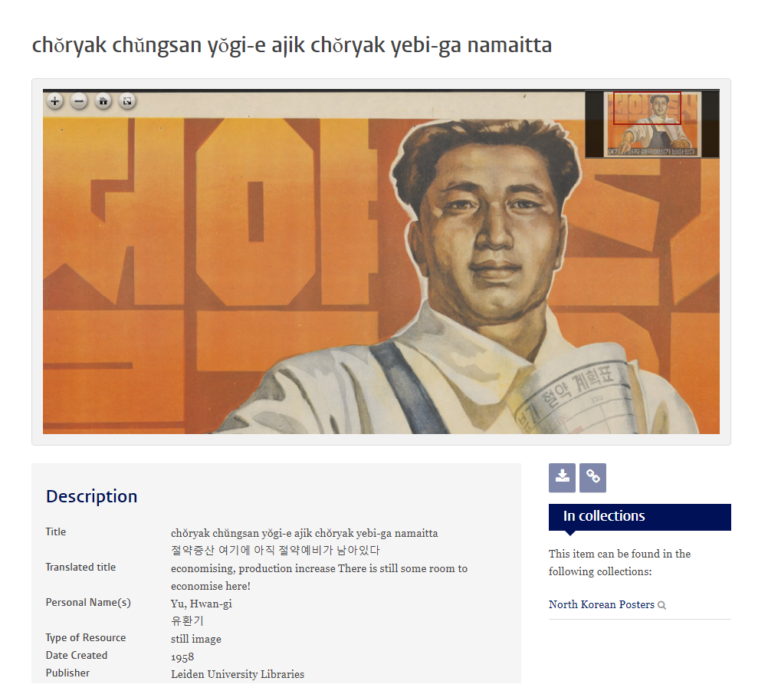
每张海报都有元数据,如标题、艺术家姓名、主题、海报内容的简要描述和各种技术细节。考虑到朝鲜的整个社会状况,我认为进行一些数据挖掘并尝试提取一些统计数据来大致了解这些海报的图像是很有趣的。
人脸检测和性别分类
海报的元数据包含了一些主题标签,告诉我们海报是关于工业、农业、体育等等方面的信息。然而,如果海报以人像为主的话人,上面的信息则少得多。一些海报在它们的数据库中有一个额外的条目,详细描述了它们的内容,但是数量相对较少。但是,我们可以使用计算机视觉算法来检测海报上的人,并根据性别来对他们进行分类。因此,这也会让我们了解到朝鲜的社会活动是如何进行性别化的。
让我们从一些代码开始。人脸检测是一种典型的计算机视觉问题,它的目标是确定图像中是否存在(人脸)。幸运的是,对于2D静态图像来说,算法现在已经很成熟,并且可以广泛使用。先进的技术方法在总体上的准确率大约为80%。如果脸部面积较大的话,准确率更是接近或超过90%。
由于可用的人脸检测算法是根据真实的图像而不是绘图来训练的,这些海报在我们的数据集上可能不会表现得很好。然而,由于朝鲜的艺术是社会主义现实主义的继承者,海报中的人物被画得非常逼真,他们的面部结构与现实中的人脸及其相似。这也让我们这次训练比平常的摄影集看上去更有优势。此外,人脸检测算法面临的主要挑战之一是人像所摆的姿势,尴尬的角度会对准确度产生非常负面的影响。好在朝鲜海报上的人物造型比较趋于美学标准,而且人物主要是面向前方的,所以他们的面部应该更容易辨认。

我们将使用面部识别Python包执行面部检测。这个包本身需要用于Python的Boost C++库和dlib库。因为图片大小和分辨率都会影响人脸的检测,所以图像会被重新调整成原图像的2.5倍大小。一旦找到了一个面孔,我们就会分离出被检测到的图片的区域,并使用imutils包对它执行面部校准。面部校准是一种检测脸部(鼻子,眼睛,下颌线)的主要关键点的操作,然后应用必要的仿射变换(缩放,旋转,转换……),使关键点被投射到一个规范的位置。这有点像数据标准化,确保我们所有的数据都处于类似的规模和位置。最后,这些面孔将被保存到一个单独的文件夹中:
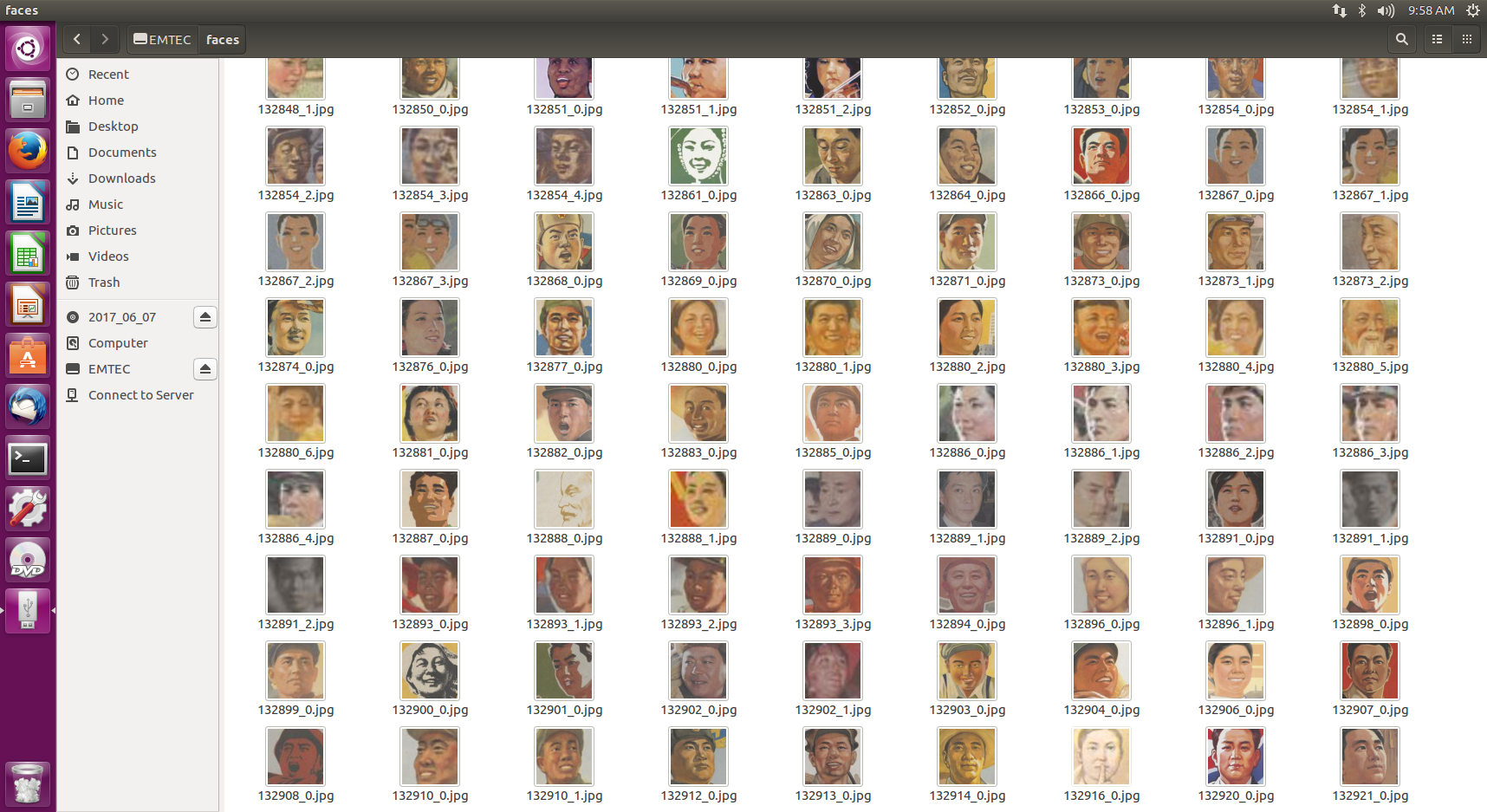
这里总共有1525张脸,我们现在需要对每个性别进行分类。这里没有“开箱即用”的性别检测库,以及开源分类器。开源分类器在真人照片上训练只比随机在海报上找到的面孔稍微好一点,准确率约为60%。由于没有那么多的图像,我们也可以手动进行分类,这样就会有更好的准确度。但这将是单调乏味的重复,而且每次新海报被添加到集合中,我们将不得不再次这样做。
既然我们的目的不是寻找完美的精确性,我们可以尝试使用机器学习来构建一个足够健壮的分类器,这样我们在以后也可以使用它。
为了做到这一点,我们仍然需要手动进行一些分类,以便构造一个对算法进行训练和测试的数据集。通过在控制台中显示每个人的面部,让我们识别性别,然后将文件复制到一个分类的目录结构中。我们将有两个目录,一个用于训练,一个用于测试,每个目录中都包含一个“男性”和“女性”文件夹。当我们识别人脸的性别时,脚本会在75%的时间内自动将源图像复制到训练目录,并在25%的时间内将其复制到测试目录中。最后,当我们遇到来自早期人脸检测步骤的错误判断时,也可以选择丢弃图像。
在整理了大约300张图片后(大约完成了整个数据集的1/5),我们最后得到了220张经过训练的面部(140名男性/80名女性)和70个测试的面部(30名女性/40名男性):
现在我们有了数据,我们需要选择一种算法来训练。对于像这样的图像分类任务,卷积神经网络(CNN)通常是理想的候选对象,但是200张图片的数据太少,无法有效地训练CNN。如果没有数百万的样本,我们可能需要找到一个非深度学习的解决方案。我们可以试着使用特征提取的Eigenfaces或Fisherfaces等方法,将结果传递给一个非深度学习的二进制分类器。一个使用fisherfaces的简单尝试得到了超过80%的准确率和召回率,这个结果当然不差,但也不是很好。
一个更好的选择是转移学习,让我们能够利用神经网络的性能而不需要有巨大的训练数据。我们可以尝试使用另一个深度学习模型,这个模型在相当大的数据中被训练成一个相当相似的任务。对于一个已经训练过执行图像分类任务的CNN来说,这意味着我们可以通过移除最终的完全连接的层来进行分类,并重用其他层的输出来反馈给我们自己的分类器,从而“砍掉模型的头部”。因此,我们只能保留卷积层,并将它们作为特性提取器使用。因为一直在类似的数据模型中被训练,但在更大的范围内,它有机会去学习与我们分类任务相关的更广泛的特征, 并且这个分类任务让我们永远无法从一个由几十张图片组成的数据集中学习。

对于我们的模型来说,一个很好的转移学习的方法是VGG-Face CNN,它是一个在260万张图片中接受面部识别任务的基于深度架构的模型。该模型的Python版本可作为深度学习库Keras的一部分,这将使我们的工作更加轻松。
我们将重复使用VGG-Face的卷积层,然后将我们自己的分类器添加到两个完全连接的层和一个s型的激活层(我们将执行一个二进制分类任务:在朝鲜,性别不是过度不固定的),并训练模型超过100个epoch。请注意生成器类的使用:即使我们的数据集相当小,我们输入的图像也足够大了(224×224,RGB)。生成器允许我们在不同的部分加载数据集,并将其作为输入发送给我们的模型。这有点类似于Keras的“ImageDataGenerator”特征,但拥有自己的类可以提供更多的灵活性:
调用save_features()和create_model()后的结果:
我们可以通过对最终的分类器进行修改,或者使用数据增强技术人为地增加数据集,从而进行轻微的改进,由于这些训练数据是十分有限的,所以结果已经很令人满意了。
我们现在可以在训练和测试数据集上对模型进行训练,并使用它来标记整个脸部的集合,结果和我们预期的一样准确:

图表和数据
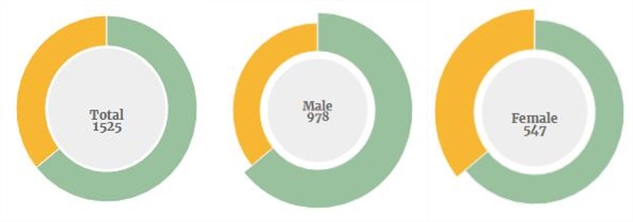
现在面部已经被提取并贴上了标签,我们就可以开始处理一些数字了。让我们从一些一般的统计数据开始:
得出的结论是,男性在海报上的流行程度几乎是女性的两倍。这种不平衡的分配在整个国家的历史中都是相当稳定的,尽管在2000年有所改善:
以上图表的一个有趣的特点是在90年代有一个下滑,这表明在这一时期的海报在收藏中没有得到充分的体现。这可能是由于朝鲜饥荒期间纸张的缺乏而导致的。这也可能表明,饥荒对国家的宣传活动产生了强烈的影响,导致在过去十年里,海报的数量减少了一半以上。
因为海报的元数据包括标签,我们也可以尝试分析其中的性别分布。首先让我们列出最常用的关键词:
现在是在这些关键词中的性别分布:
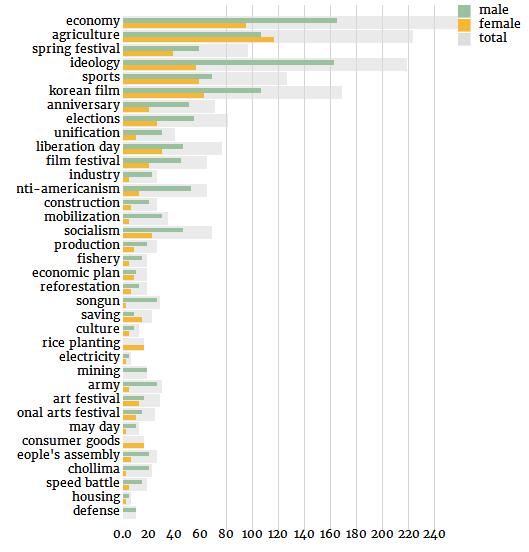
关键词“经济(economy)”意思有点太大了,先忽略不计。在下一个最常见的关键词“农业(agriculture)”中,女性的角色比男性要多。另一方面,如果我们看看与第二产业相关的关键字,如“行业(industry)”、“采矿业(mining)”或“建筑业(construction)”,我们看到的是相反的情况,男性角色比女性更有代表性。
这不仅仅是就业人口统计数据的反映:尤其是在农业部门,阶级的问题更多的是家庭的问题而不是个人的问题。相反,在社会主义的世界里,农业劳动与女性和工业劳动与男性的结合,在社会上有着悠久的历史传统。除了农业之外,另一个领域是女性在与男性的家庭管理(“消费品(consumer goods)”,“储蓄(savings)”)的比较中占了很大的比例。在军事上(“防御(defense)”,“军队(army)”,“先军(songun)”)和更广泛的政治上(“思想体系(ideology)”、“反美主义(anti-americanism)”,“最高人民会议(supreme people’s assembly)”)显示一个高于平均水平的男女失衡的比例。此外,人口分布超过80%的朝鲜最高人民会议参与者是男性(和韩国国会几乎一模一样)。
前面提到,一些海报包含了元数据中的内容的简要描述。为了补充我们从视觉数据中提取的统计数据,我们可以尝试挖掘这些额外的信息来源,看看我们是否能发现一些类似的趋势。为了做到这一点,我们可以迭代整个元数据收集,每次“男性”或“女性”出现时,我们将捕捉跟随的相关名词,这些名词描述了在问题中男性或女性的比重。
为了完成任务,使用spaCy来进行标记化(tokenization)和词性标注(pos-tagging),下面的函数将执行任务,将其作为海报的描述,性别包含了“男性”或“女性”的字符串,以及gender_dict默认变量(将值设置等于0)来存储我们的计数:
这就给出了关于男性的以下结论:
女性的结论:
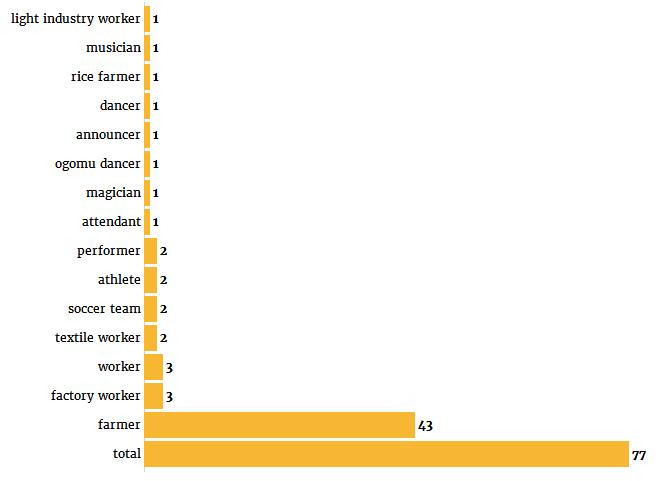
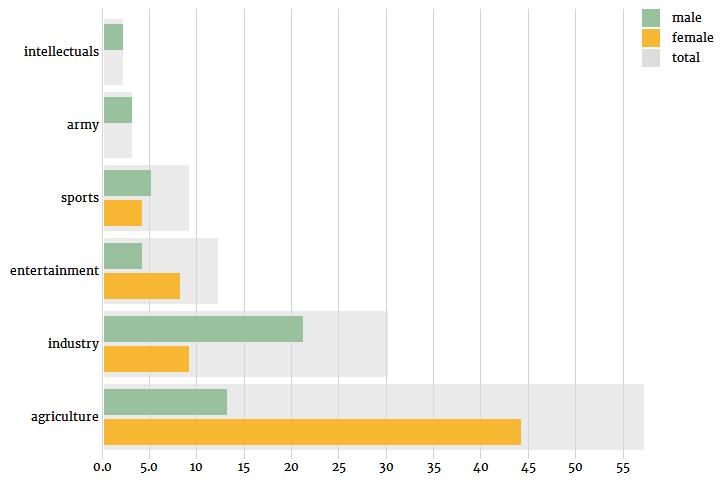
我们可以再次注意到女性农业工人代表的相对优势,以及与工业相关职业中男性角色的相对优势。纺织(Textile)和轻工业(light industry)的海报都有女性角色,但没有男性角色暗示了在这个特定的经济部门中,性别划分可能是什么。最后,值得注意的是,“女性”一词在77个描述中被提到,而提到了“男性”的这个词只有66个,很可能是因为当一个海报的中心人物是男性时,性别特征往往在描述中被省略。总之,如果我们把这些小类别分成更大的类别,我们就可以用下面的图来总结从文本描述中挖掘出来的数据:
方法论的意义和局限性
对可视化或文本数据的某些方面的量化,以及统计数据的编制,显然不能代替详细的定性分析。目前的方法并没有考虑到类似范畴的变化:可能有很多不同的女性工人,我们无法解释。或者类似的,在男性和女性工人被描绘的方式上可能存在差异,正如下面的海报所展示的那样:

另一方面,量化并不一定是客观性的保证:采用的算法都有局限性,可以在最终结果中积累并引入一些显著的偏差。本文中开发的方法更多地是应用在POC级别上,而实际的学术应用程序需要更好的度量标准和进一步的描述,以便更好地解释模型所引入的限制和偏差。另一个限制是更在复杂算法的“黑箱”方面,比如CNNs:虽然可以可视化和理解网络使用的一些特性,但它们很难解释,在某些情况下,可能过于抽象,无法正确的解释。
几个月前,荷兰莱顿大学的Koen de Ceuster教授组织了一场关于朝鲜海报的研讨会。海报主要来自于个人私藏。Ceuster教授将这些海报进行数字化,现在它们已经作为莱顿大学的数字收藏的一部分。
图来源:莱顿大学的数字收藏网站
每张海报都有元数据,如标题、艺术家姓名、主题、海报内容的简要描述和各种技术细节。考虑到朝鲜的整个社会状况,我认为进行一些数据挖掘并尝试提取一些统计数据来大致了解这些海报的图像是很有趣的。
人脸检测和性别分类
海报的元数据包含了一些主题标签,告诉我们海报是关于工业、农业、体育等等方面的信息。然而,如果海报以人像为主的话人,上面的信息则少得多。一些海报在它们的数据库中有一个额外的条目,详细描述了它们的内容,但是数量相对较少。但是,我们可以使用计算机视觉算法来检测海报上的人,并根据性别来对他们进行分类。因此,这也会让我们了解到朝鲜的社会活动是如何进行性别化的。
让我们从一些代码开始。人脸检测是一种典型的计算机视觉问题,它的目标是确定图像中是否存在(人脸)。幸运的是,对于2D静态图像来说,算法现在已经很成熟,并且可以广泛使用。先进的技术方法在总体上的准确率大约为80%。如果脸部面积较大的话,准确率更是接近或超过90%。
由于可用的人脸检测算法是根据真实的图像而不是绘图来训练的,这些海报在我们的数据集上可能不会表现得很好。然而,由于朝鲜的艺术是社会主义现实主义的继承者,海报中的人物被画得非常逼真,他们的面部结构与现实中的人脸及其相似。这也让我们这次训练比平常的摄影集看上去更有优势。此外,人脸检测算法面临的主要挑战之一是人像所摆的姿势,尴尬的角度会对准确度产生非常负面的影响。好在朝鲜海报上的人物造型比较趋于美学标准,而且人物主要是面向前方的,所以他们的面部应该更容易辨认。
人脸检测(幸好背景中的人物的面孔没有被检测到)
我们将使用面部识别Python包执行面部检测。这个包本身需要用于Python的Boost C++库和dlib库。因为图片大小和分辨率都会影响人脸的检测,所以图像会被重新调整成原图像的2.5倍大小。一旦找到了一个面孔,我们就会分离出被检测到的图片的区域,并使用imutils包对它执行面部校准。面部校准是一种检测脸部(鼻子,眼睛,下颌线)的主要关键点的操作,然后应用必要的仿射变换(缩放,旋转,转换……),使关键点被投射到一个规范的位置。这有点像数据标准化,确保我们所有的数据都处于类似的规模和位置。最后,这些面孔将被保存到一个单独的文件夹中:
- 面部识别Python包地址:https://pypi.python.org/pypi/face_recognition
- Boost C++ library安装地址:http://www.boost.org/
- dlib安装地址:https://pypi.python.org/pypi/dlib
- 面部校准:https://www.pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/
- imutils包安装地址:https://github.com/jrosebr1/imutils
from imutils.face_utils import FaceAligner
from dlib import rectangle
import face_recognition
import imutils
import dlib
import cv2
import os
def resize(img):
resized = cv2.resize(img, (0,0), fx=2.5, fy=2.5)
return resized
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") #path to the dlib model shape_predictor_68_face_landmarks.dat
fa = FaceAligner(predictor, desiredFaceWidth=224)
images = os.listdir('Posters')
for i, index in enumerate(images):
print(index, ':', i, '/', len(images))
image_path = 'Posters\\' + index + '\\' + index + '.jpg'
img = cv2.imread(image_path)
img = resize(img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face_locations = face_recognition.face_locations(img, number_of_times_to_upsample=0)
for j, face_location in enumerate(face_locations):
top, right, bottom, left = face_location
dlib_rect = rectangle(left, top, right, bottom) #convert to dlib rect object
faceOrig = imutils.resize(img[top:bottom, left:right], width=224)
faceAligned = fa.align(img, gray, dlib_rect)
cv2.imwrite('faces/' + index + '_' + str(j) + '.jpg', faceAligned)
这里总共有1525张脸,我们现在需要对每个性别进行分类。这里没有“开箱即用”的性别检测库,以及开源分类器。开源分类器在真人照片上训练只比随机在海报上找到的面孔稍微好一点,准确率约为60%。由于没有那么多的图像,我们也可以手动进行分类,这样就会有更好的准确度。但这将是单调乏味的重复,而且每次新海报被添加到集合中,我们将不得不再次这样做。
既然我们的目的不是寻找完美的精确性,我们可以尝试使用机器学习来构建一个足够健壮的分类器,这样我们在以后也可以使用它。
朝鲜人的面部
为了做到这一点,我们仍然需要手动进行一些分类,以便构造一个对算法进行训练和测试的数据集。通过在控制台中显示每个人的面部,让我们识别性别,然后将文件复制到一个分类的目录结构中。我们将有两个目录,一个用于训练,一个用于测试,每个目录中都包含一个“男性”和“女性”文件夹。当我们识别人脸的性别时,脚本会在75%的时间内自动将源图像复制到训练目录,并在25%的时间内将其复制到测试目录中。最后,当我们遇到来自早期人脸检测步骤的错误判断时,也可以选择丢弃图像。
import cv2
import os
import matplotlib.pyplot as plt
images = os.listdir('faces')
def smaller(img):
resized = cv2.resize(img, (0,0), fx=1/2, fy=1/2)
return resized
plt.axis('off')
for index, image in enumerate(images):
img = cv2.imread('faces/' + image)
img = smaller(img)
plt.imshow(cv2.cvtColor((img), cv2.COLOR_BGR2RGB))
plt.show(block=False)
category = ''
while category not in ['m', 'f', 'o']:
print(index, '/', len(images))
print(image)
category = input('Category ? ')
if index % 4 == 0:
path = 'data7/test'
else:
path = 'data7/train'
if category == 'm':
cv2.imwrite(path + '/male/' + image, img)
elif category == 'f':
cv2.imwrite(path + '/female/' + image, img)
elif category == 'o':
cv2.imwrite('data7/other/' + image, img)
在整理了大约300张图片后(大约完成了整个数据集的1/5),我们最后得到了220张经过训练的面部(140名男性/80名女性)和70个测试的面部(30名女性/40名男性):
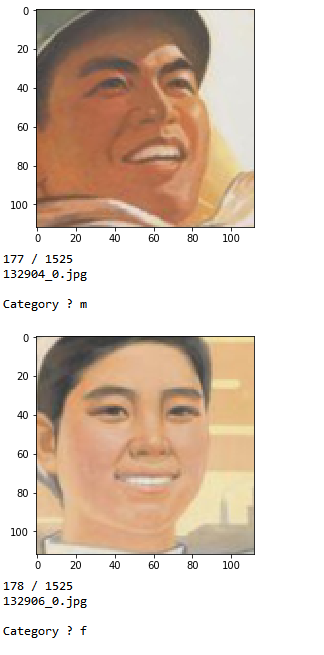 手动标注数据集
手动标注数据集
现在我们有了数据,我们需要选择一种算法来训练。对于像这样的图像分类任务,卷积神经网络(CNN)通常是理想的候选对象,但是200张图片的数据太少,无法有效地训练CNN。如果没有数百万的样本,我们可能需要找到一个非深度学习的解决方案。我们可以试着使用特征提取的Eigenfaces或Fisherfaces等方法,将结果传递给一个非深度学习的二进制分类器。一个使用fisherfaces的简单尝试得到了超过80%的准确率和召回率,这个结果当然不差,但也不是很好。
一个更好的选择是转移学习,让我们能够利用神经网络的性能而不需要有巨大的训练数据。我们可以尝试使用另一个深度学习模型,这个模型在相当大的数据中被训练成一个相当相似的任务。对于一个已经训练过执行图像分类任务的CNN来说,这意味着我们可以通过移除最终的完全连接的层来进行分类,并重用其他层的输出来反馈给我们自己的分类器,从而“砍掉模型的头部”。因此,我们只能保留卷积层,并将它们作为特性提取器使用。因为一直在类似的数据模型中被训练,但在更大的范围内,它有机会去学习与我们分类任务相关的更广泛的特征, 并且这个分类任务让我们永远无法从一个由几十张图片组成的数据集中学习。
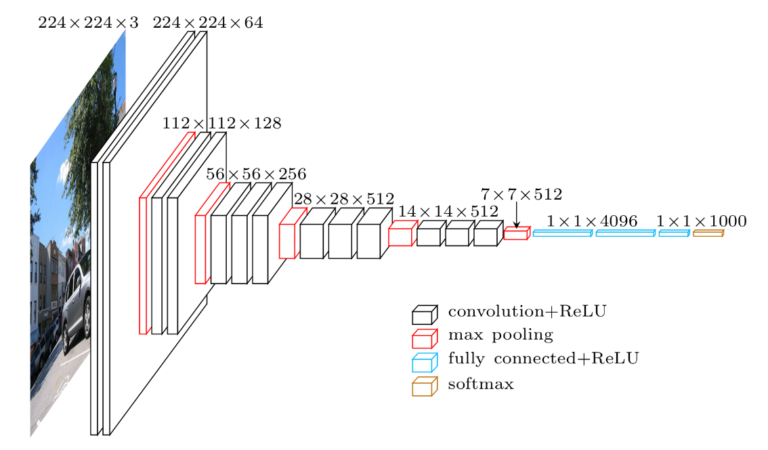
对于我们的模型来说,一个很好的转移学习的方法是VGG-Face CNN,它是一个在260万张图片中接受面部识别任务的基于深度架构的模型。该模型的Python版本可作为深度学习库Keras的一部分,这将使我们的工作更加轻松。
- VGG-Face CNN安装地址:http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
VGG-16模型架构,VGG Face基于此架构
我们将重复使用VGG-Face的卷积层,然后将我们自己的分类器添加到两个完全连接的层和一个s型的激活层(我们将执行一个二进制分类任务:在朝鲜,性别不是过度不固定的),并训练模型超过100个epoch。请注意生成器类的使用:即使我们的数据集相当小,我们输入的图像也足够大了(224×224,RGB)。生成器允许我们在不同的部分加载数据集,并将其作为输入发送给我们的模型。这有点类似于Keras的“ImageDataGenerator”特征,但拥有自己的类可以提供更多的灵活性:
import os
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras_vggface.vggface import VGGFace
from inspect import getsourcefile
from os.path import abspath
from generator import Generator
path = os.path.dirname(abspath(getsourcefile(lambda:0)))
categories = os.listdir(os.path.join(path, 'data7/test'))
y_train = []
X_train = []
y_test = []
X_test = []
batch_size = 10
print('Getting samples')
for i, category in enumerate(categories):
print(category)
samples = os.listdir(os.path.join(path, 'data7/test', category))
for sample in samples:
X_test.append(os.path.join(path, 'data7/test', category, sample))
y_test.append(i)
for i, category in enumerate(categories):
print(category)
samples = os.listdir(os.path.join(path, 'data7/train', category))
for sample in samples:
X_train.append(os.path.join(path, 'data7/train', category, sample))
y_train.append(i)
training_generator = Generator(width = 224, height = 224, channels = 3, batch_size = batch_size).generate(X_train, y_train, return_labels = False, shuffle = False)
testing_generator = Generator(width = 224, height = 224, channels = 3, batch_size = batch_size).generate(X_test, y_test, return_labels = False, shuffle = False)
def save_features():
model = VGGFace(include_top=False, input_shape=(224, 224, 3), weights='vggface', pooling = 'avg')
bottleneck_features_train = model.predict_generator(training_generator, len(X_train) // batch_size)
np.save(open('bottleneck_features_train.npy', 'wb'), bottleneck_features_train)
bottleneck_features_test = model.predict_generator(testing_generator, len(X_test) // batch_size)
np.save(open('bottleneck_features_testing.npy', 'wb'), bottleneck_features_test)
def create_model():
train_data = np.load(open('bottleneck_features_train.npy', 'rb'))
train_labels = np.array([0] * 80 + [1] * 140)
train_labels = train_labels[:len(train_labels) - (len(train_labels) % batch_size)]
validation_data = np.load(open('bottleneck_features_testing.npy', 'rb'))
validation_labels = np.array([0] * 30 + [1] * 40)
validation_labels = validation_labels[:len(validation_labels) - (len(validation_labels) % batch_size)]
model = Sequential()
model.add(Dense(256, activation='relu', input_shape=train_data.shape[1:]))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels,
epochs=100,
batch_size=batch_size,
validation_data=(validation_data, validation_labels))
score = model.evaluate(validation_data, validation_labels)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
print("Baseline Error: %.2f%%" % (100-score[1]*100))
调用save_features()和create_model()后的结果:
Epoch 95/100
220/220 [==============================] – 0s – loss: 0.0091 – acc: 0.9955 – val_loss: 1.7121 – val_acc: 0.8714
Epoch 96/100
220/220 [==============================] – 0s – loss: 0.0328 – acc: 0.9909 – val_loss: 0.7962 – val_acc: 0.9143
Epoch 97/100
220/220 [==============================] – 0s – loss: 0.1059 – acc: 0.9727 – val_loss: 0.8883 – val_acc: 0.9000
Epoch 98/100
220/220 [==============================] – 0s – loss: 0.0445 – acc: 0.9864 – val_loss: 0.7507 – val_acc: 0.9143
Epoch 99/100
220/220 [==============================] – 0s – loss: 0.0226 – acc: 0.9864 – val_loss: 0.8338 – val_acc: 0.9143
Epoch 100/100
220/220 [==============================] – 0s – loss: 0.0279 – acc: 0.9909 – val_loss: 0.8331 – val_acc: 0.9429
32/70 [============>……………..] – ETA: 0sTest loss: 0.833102767808
Test accuracy: 0.942857142857
Baseline Error: 5.71%
我们可以通过对最终的分类器进行修改,或者使用数据增强技术人为地增加数据集,从而进行轻微的改进,由于这些训练数据是十分有限的,所以结果已经很令人满意了。
我们现在可以在训练和测试数据集上对模型进行训练,并使用它来标记整个脸部的集合,结果和我们预期的一样准确:
性别分类
图表和数据
现在面部已经被提取并贴上了标签,我们就可以开始处理一些数字了。让我们从一些一般的统计数据开始:
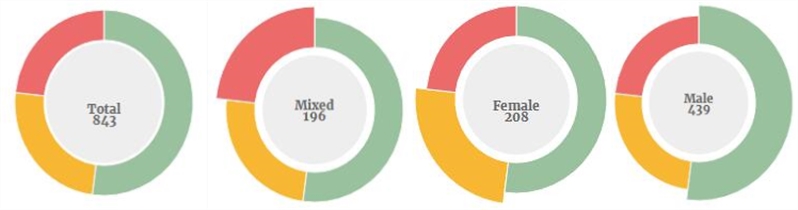
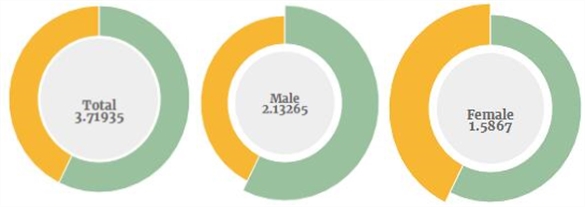
男女面部数量分布
海报中塑造的人物性别分布
在混合人物的海报中性别分布
得出的结论是,男性在海报上的流行程度几乎是女性的两倍。这种不平衡的分配在整个国家的历史中都是相当稳定的,尽管在2000年有所改善:
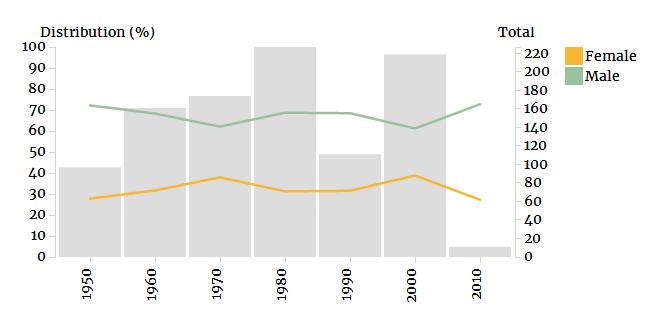
以上图表的一个有趣的特点是在90年代有一个下滑,这表明在这一时期的海报在收藏中没有得到充分的体现。这可能是由于朝鲜饥荒期间纸张的缺乏而导致的。这也可能表明,饥荒对国家的宣传活动产生了强烈的影响,导致在过去十年里,海报的数量减少了一半以上。
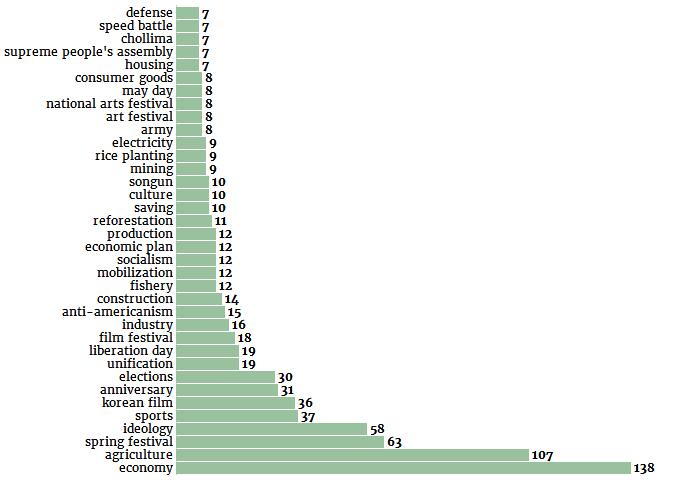
因为海报的元数据包括标签,我们也可以尝试分析其中的性别分布。首先让我们列出最常用的关键词:
现在是在这些关键词中的性别分布:
关键词“经济(economy)”意思有点太大了,先忽略不计。在下一个最常见的关键词“农业(agriculture)”中,女性的角色比男性要多。另一方面,如果我们看看与第二产业相关的关键字,如“行业(industry)”、“采矿业(mining)”或“建筑业(construction)”,我们看到的是相反的情况,男性角色比女性更有代表性。
这不仅仅是就业人口统计数据的反映:尤其是在农业部门,阶级的问题更多的是家庭的问题而不是个人的问题。相反,在社会主义的世界里,农业劳动与女性和工业劳动与男性的结合,在社会上有着悠久的历史传统。除了农业之外,另一个领域是女性在与男性的家庭管理(“消费品(consumer goods)”,“储蓄(savings)”)的比较中占了很大的比例。在军事上(“防御(defense)”,“军队(army)”,“先军(songun)”)和更广泛的政治上(“思想体系(ideology)”、“反美主义(anti-americanism)”,“最高人民会议(supreme people’s assembly)”)显示一个高于平均水平的男女失衡的比例。此外,人口分布超过80%的朝鲜最高人民会议参与者是男性(和韩国国会几乎一模一样)。
前面提到,一些海报包含了元数据中的内容的简要描述。为了补充我们从视觉数据中提取的统计数据,我们可以尝试挖掘这些额外的信息来源,看看我们是否能发现一些类似的趋势。为了做到这一点,我们可以迭代整个元数据收集,每次“男性”或“女性”出现时,我们将捕捉跟随的相关名词,这些名词描述了在问题中男性或女性的比重。
为了完成任务,使用spaCy来进行标记化(tokenization)和词性标注(pos-tagging),下面的函数将执行任务,将其作为海报的描述,性别包含了“男性”或“女性”的字符串,以及gender_dict默认变量(将值设置等于0)来存储我们的计数:
def extract_info(desc, gender, gender_dict):
doc = nlp(desc)
indices = [i for i, x in enumerate(doc) if x.lemma_ == gender]
for index in indices:
s = ''
i = index + 1
gender_dict['total'] += 1
while ((i < len(doc)) and
(doc[i].pos_ in filters)):
s += doc[i].lemma_ + ' '
print('s', s)
i += 1
if s != '':
gender_dict[s.strip()] += 1
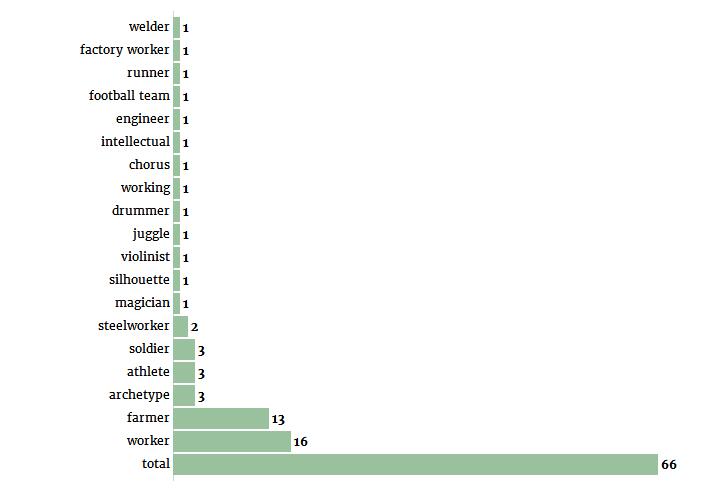
这就给出了关于男性的以下结论:
女性的结论:
我们可以再次注意到女性农业工人代表的相对优势,以及与工业相关职业中男性角色的相对优势。纺织(Textile)和轻工业(light industry)的海报都有女性角色,但没有男性角色暗示了在这个特定的经济部门中,性别划分可能是什么。最后,值得注意的是,“女性”一词在77个描述中被提到,而提到了“男性”的这个词只有66个,很可能是因为当一个海报的中心人物是男性时,性别特征往往在描述中被省略。总之,如果我们把这些小类别分成更大的类别,我们就可以用下面的图来总结从文本描述中挖掘出来的数据:
方法论的意义和局限性
对可视化或文本数据的某些方面的量化,以及统计数据的编制,显然不能代替详细的定性分析。目前的方法并没有考虑到类似范畴的变化:可能有很多不同的女性工人,我们无法解释。或者类似的,在男性和女性工人被描绘的方式上可能存在差异,正如下面的海报所展示的那样:
一名男工人在打扫他的机器,而一名女工人正在擦窗户
然而,使用数据和统计可以使一个人在处理表示问题时能够做出更鲁棒的断言。从大量数据中提取信息不仅可以加强论证,而且还有助于在进行进一步研究之前进行快速的假设测试。简单的数据处理技术和数据可视化,允许一个人快速检测兴趣点,并将那些似乎不支持数据的假设撤出。
另一方面,量化并不一定是客观性的保证:采用的算法都有局限性,可以在最终结果中积累并引入一些显著的偏差。本文中开发的方法更多地是应用在POC级别上,而实际的学术应用程序需要更好的度量标准和进一步的描述,以便更好地解释模型所引入的限制和偏差。另一个限制是更在复杂算法的“黑箱”方面,比如CNNs:虽然可以可视化和理解网络使用的一些特性,但它们很难解释,在某些情况下,可能过于抽象,无法正确的解释。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消