











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从零开始,教你如何编写一个神经网络分类器
2017年10月26日 由 xiaoshan.xiang 发表
238301
0
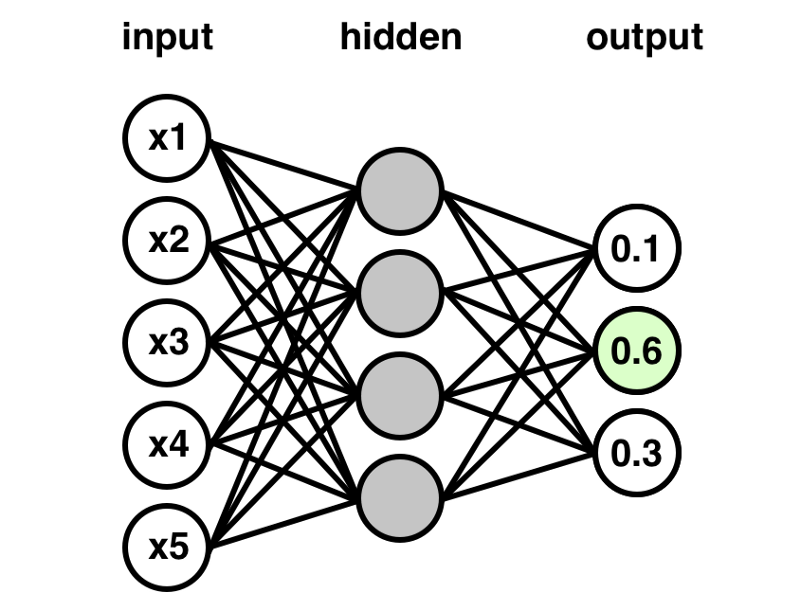
高水平的深度学习库,如TensorFlow,Keras和Pytorch,通过隐藏神经网络的许多乏味的内部工作细节,使深度学习从业者的生活变得更容易。尽管这是深度学习的好方法,但它仍然有一个小缺点:让许多基础理解较差的新来者在其他地方学习。我们的目标是提供从头开始编写的一个隐藏层全连接神经网络分类器(没有深度学习库),以帮助消除神经网络中的黑箱。这个项目的Github repo地址是:
https://github.com/ankonzoid/NN-from-scratch
所提供的神经网络对描述属于小麦的三类内核的几何属性的数据集进行分类(你可以轻松地将其替换为自己的自定义数据集)。假设有一个L2损失函数,并且在隐藏和输出层中的每个节点上使用sigmoid传递函数。权值更新方式使用具有L2范数的梯度下降的差量规则。
本文的其余部分,概述了我们的代码为构建和训练神经网络进行类预测所采取的一般步骤。关于深度学习和强化学习的博客,教程和项目,请查看Medium和Github。
Medium地址:https://medium.com/@ankonzoid
Github地址:https://github.com/ankonzoid
我们逐步建立单层神经网络分类器
1.设置n次交叉验证
对于N次交叉验证,我们随机地排列N个样本指标,然后取连续大小为~ N/ n的块作为折叠。每个折叠作为一个交叉验证实验的测试集,补码(complement )指标作为训练集。
2.创建和训练神经网络模型
我们有2个完全连通的权值层:一个连接输入层节点与隐藏层节点,另一个连接隐藏层节点与输出层节点。如果没有任何偏项,这应该是神经网络中权值数量的总和(n_input *n_hidden + n_hidden* n_output)。我们通过对正态分布进行采样来初始化每个权值。
每个节点(神经元)具有存储到存储器中的3个属性:连接到其输入节点的权重列表,由正向传递的一些输入计算得到的输出值,以及表示其输出的反向传递分类不匹配的增量值层。这3个属性是相互交织的,并通过以下三个过程循环进行更新:
(A)正向传递一个训练示例,以更新当前给定节点权值的节点输出。每个节点输出被计算为其上一层输入(无偏项)的加权和,然后是sigmoid传递函数。
(B)反向传递分类错误,以更新当前给出节点权值的节点增量。因为我们使用从L2损失函数应用梯度下降导出的相同的增量规则方程。
(C)我们通过更新节点输出和增量来执行正向传递以更新当前的权值。
训练周期过程为(A)→(B)→(C),对每个训练样本执行该过程。
3.进行类预测
在训练之后,我们可以简单地使用这个模型来对我们的测试样本进行类预测,方法是将文本示例传递给经过训练的神经网络,获取输出的argmax函数。准确性分数是示例(在训练和测试集的n倍交叉验证中)数量的直观分数,在该示例中神经网络分类正确地除以了样本总数。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消