











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






人工智能技术深度实践:如何用神经网络给黑白照片着色
2017年12月30日 由 yining 发表
344890
0
现如今,将图片彩色化是通常用Photoshop处理的。一幅作品有时候需要用一个月的时间来着色。可能单单一张脸就需要20层的粉色、绿色和蓝色阴影才能让它看起来恰到好处。为了了解这一过程,你可以看看下面这个视频。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/10/arrsss.mp4"][/video]
视频地址:https://www.youtube.com/watch?v=vubuBrcAwtY
在本文中,我将向你展示如何构建色彩化神经网络。第一部分分解了核心逻辑。我们将构建一个40行的神经网络作为一个名叫“Alpha”的彩色化机器人。下一步是创建一个可通用化的神经网络---Beta版本。我们将会给机器人上色,这是以前从未见过的。下面就开始我们的人工智能应用的深度实践吧!
在本节中,我将概述如何呈现图像以及我们的神经网络的主要逻辑。
黑白图像可以用像素网格表示。每个像素都有一个对应其亮度的值。值的跨度从0到255,从黑色到白色。

彩色图像由三层组成:红色层,绿色层和蓝色层。想象一下,在白色的背景下,把一片绿色的叶子分成三个通道。直观地说,你可能会认为植物只存在于绿色的层中。
但是,正如你在下面的图中所看到的,这片树叶在所有三个通道中都存在。这些层不仅决定了颜色,还决定了亮度。

例如,为了实现白色,你需要对所有颜色进行相同的分布。通过增加等量的红色和蓝色,会使绿色变得更亮。因此,一种彩色图像可以用三个层来编码颜色和对比度: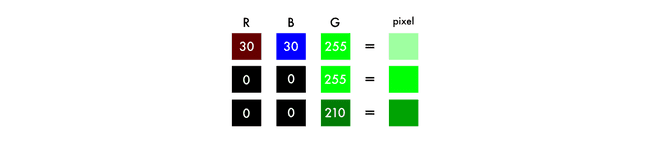 就像黑白图像一样,彩色图像中的每一层都有一个介于0-255之间的值。0值表示在这一层没有颜色。如果所有彩色通道的值为0,那么图像像素是黑色的。
就像黑白图像一样,彩色图像中的每一层都有一个介于0-255之间的值。0值表示在这一层没有颜色。如果所有彩色通道的值为0,那么图像像素是黑色的。
正如你可能知道的,一个神经网络在输入值和输出值之间创建了一个关系。为了使我们的彩色化任务更精确,网络需要找到灰度图像与彩色图像之间相关联的特征。
总而言之,我们正在寻找灰度值网格与三种彩色网格相关的特性。
我们首先要做一个简单的神经网络来给一个女人的脸涂上颜色。通过这种方式,你可以熟悉我们的模型的核心语法(syntax),因为我们为它添加了一些特性。
只需40行代码,我们就可以进行以下转换。中间的图片是用我们的神经网络做的,右边的图片是原始的彩色照片。这个网络是在同一个图像上进行训练和测试的——我们将在beta版本中回到这个问题上。
颜色空间
首先,我们将使用一种算法来改变颜色通道,从RGB到Lab。L代表亮度,而a和b代表色谱,分别为绿红和蓝黄。
如下图所示,一个Lab编码的图像有一层用于灰度,并将三层颜色分成两层。这意味着我们可以在最终的预测中使用原始的灰度图像。而且,我们只有两个渠道可以预测。
我们眼睛中94%的细胞决定了亮度。这使得我们只有6%的受体能够充当颜色的传感器。正如你在上面的图片中所看到的,灰度图像比彩色层要清晰得多。这是在我们最后的预测中保持灰度图像的另一个原因。
从黑白到彩色
我们的最终预测是看上去是这样的。我们有一个用于输入的灰度层,并且我们想要预测两个彩色层,Lab中的ab。为了创建最终的彩色图像,我们将包含我们用于输入的L/灰度图像,因此,需要创建一个Lab图像。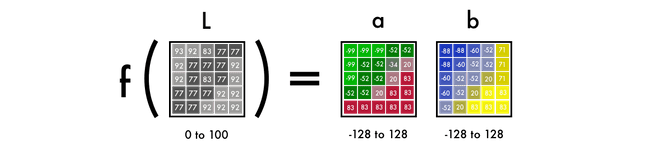
为了将一层变成两层,我们使用卷积滤波器。可以把它们看作是3D眼镜的蓝色/红色滤镜。每个滤波器决定了我们在图片中看到的东西。它们可以突出或移除一些东西来从图片中提取信息。网络可以从一个滤波器中创建一个新图像,或者将多个滤波器组合成一个图像。
对于卷积神经网络,每个滤波器都会自动调整,以帮助实现预期的结果。我们先把数百个滤波器堆叠起来,然后把它们分成两层,a层和b层。
在深入了解它的工作原理之前,让我们来运行代码。
部署FloydHub上的代码
如果你是FloyHub新手,请花费2分钟安装它,并观看下面的5分钟安装教程或者步骤指南。这是最好的(也是最简单的)在云GPUs上训练深度学习模式的方法。
Alpha版本
一旦安装了FloydHub,请使用以下命令:
打开文件夹并启动FloyHub。
在你的浏览器中,FloydHub web仪表盘将会打开,并且你将会被提示创建一个名为“colornet”的全新的FloydHub项目。完成之后,返回到你的终端并运行相同的init命令。
好了,开始运行我们的工作:
一些关于我们工作的简短的说明:
在FloydHub网站上,找到Jobs tab下到Jupyter notebook,点击Jupyter Notebook链接,然后前往到这个文件:floydhub/Alpha version/working_floyd_pink_light_full.ipynb。打开它,并在所有单元格上的点击shift+enter。
逐步增加epoch值,以了解神经网络是如何学习的。
从epoch值设置为1开始,然后增加到10,100,500,1000和3000。epoch值表示神经网络从图像中学习了多少次。一旦你训练了你的神经网络,你会发现图片img_result.png在主文件夹里。
用于运行这个网络的FloydHub命令:
技术的解释
概括地说,输入是一个表示黑白图像的网格。它输出两个带有彩色值的网格。在输入和输出值之间,我们创建滤波器将它们连接在一起,这是一个卷积神经网络。
训练网络时,我们使用彩色图像。我们将RGB彩色转换为Lab彩色空间。黑色层和白色层是我们的输入,两个彩色的层是输出。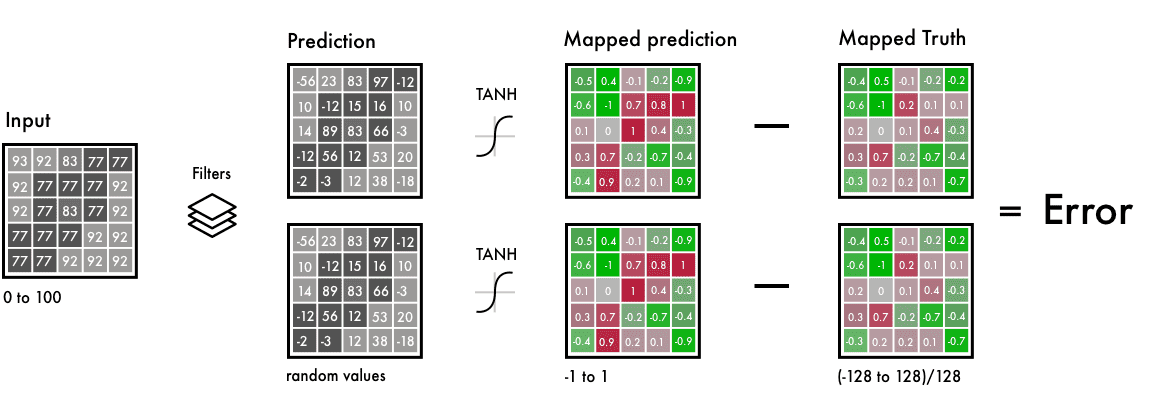
在左边,我们有黑白的输入,滤波器和来自我们的神经网络的预测。
我们在相同的时间间隔内映射预测值和实际值。这样,我们就可以比较这些值了。区间从-1到1。为了映射预测值,我们使用了一个Tanh激活函数。对于任何你设定的Tanh函数的值,它都会返回-1到1之间。
真正的彩色值会到-128到128之间,这是Lab色彩空间的默认区间。除以128,它们也在-1到1的区间内。这使我们能够比较我们预测的误差。
在计算最终的错误之后,网络将更新滤波器以减少总体错误。网络将保持在这个循环(loop)中,直到错误尽可能地降到最低。
现在,让我们阐明一下代码片段中的一些语法(syntax)。
1.0/255表示我们使用的是一个24bit RGB色彩空间。这意味着我们在每个颜色通道上使用0-255个数字。这是标准的颜色规格,结果在1670万种颜色组合中。由于人类只能感知到200-1000万种颜色,所以使用更大的色彩空间是没有意义的。
与RGB相比,Lab的色彩空间有不同的范围。Lab里的色谱范围从-128到128之间。通过将输出层中的所有值除以128,我们将把值强制在-1和1范围之间。我们将它与我们的神经网络相匹配,它也返回到-1和1之间的值。
在从rgb2lab()转换颜色空间后,我们选择灰度层:[ : , : , 0]。这是我们对神经网络的输入。[ : , : , 1: ]选择绿红色层和蓝黄色层。
在训练了神经网络之后,我们做了一个把它转换成图片的最终预测。
在这里,我们使用一个灰度图像作为输入,并通过我们训练的神经网络来运行它。我们把所有的输出值都设置在-1和1之间,然后乘以128。这使我们在Lab色谱中得到了正确的颜色。
最后,我们通过填充0s的三个层创建了一个黑色RGB画布。然后我们从测试图像中复制灰度层。然后我们将两种彩色层添加到RGB画布上。然后将这些像素值转换为一个图像。
下面是使用我们的Beta版本对验证图像进行着色的结果。
我没有使用Imagenet,而是在FloydHub上创建了一个有更高质量图像的公共数据集。这些照片来自Unsplash,是由专业摄影师拍摄的,包括了9.5万张训练图片和500张验证图片。
FloydHub公共数据集:https://www.floydhub.com/emilwallner/datasets/colornet

特征提取器
我们的神经网络发现了将灰度图像与彩色图像相关联的特征。想象一下,你必须给黑白图像上色——但是限制一次只能看到9个像素。你可以扫描从左上角到右下角的每一个图像,并试着预测每个像素的颜色。

例如,上面这9个像素是一位女性的鼻孔边缘。正如你所能想象的那样,要做一个好的着色几乎是不可能的,所以你要把它分解成几个步骤。
首先,你需要寻找简单的模式:一条斜线,所有的黑色像素,等等。你在每个方块中寻找相同的模式,并且移除不匹配的像素。你可以从64个迷你滤镜中生成64张新图片。
如果再次扫描图像,你将看到你已经检测到的相同的小模式。为了获得对图像的更高层次的理解,你可以将图像的大小减少一半。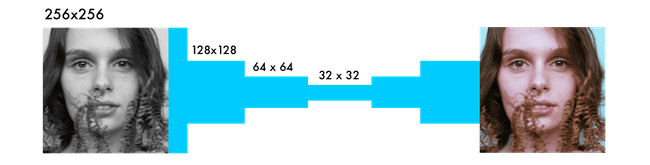
你仍然只有一个3x3的滤波器来扫描每个图像。但是通过将你的新的9个像素与你的较低级别的滤波器相结合,你可以发现更复杂的模式。一个像素的组合可能形成一个半圆,一个小点,或者一条直线。同样,你重复从图像中提取相同的模式。这一次,你将生成128个新过滤的图像。
经过几个步骤,你所生成的经过过滤的图像可能看起来是这样的: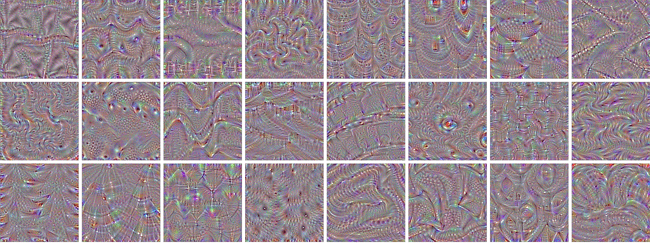
如前所述,你从低级特性开始,例如一个边缘。更靠近输出的层被合并到模式中,然后进入各种细节,最后变成了一个面孔。
如果这很难理解,那就看这个下面视频教程吧。
视频地址:https://www.youtube.com/watch?v=AgkfIQ4IGaM
这个过程就像大多数处理视觉的神经网络一样,被称为卷积神经网络。卷积类似于“结合”这个词,你结合了几个经过过滤的图像来理解图像中的各种情景。
从特征提取到颜色
神经网络以一种不断尝试的方法运作。它首先对每个像素进行随机预测。基于每个像素的误差,它通过网络逆向工作来改进特征提取。
它开始对产生最大错误的情况进行调整。在这种情况下,是否着色并定位不同的对象,然后把所有的对象都变成棕色。棕色是最类似于其他颜色的颜色,因此产生了最小的误差。
因为大多数训练数据都很相似,所以网络很难区分不同的物体。它会调整不同色调的棕色,但不会产生更细微的颜色。
下面是beta版本的代码,后面是对代码的技术解释。
以下是用于运行beta神经网络的FloydHub命令:
技术的解释
与其他可视网络的主要区别是像素位置的重要性。在着色网络中,图像的大小或比率在整个网络中保持不变。在其他网络中,图像被扭曲得接近最后一层。
分类网络中的最大池化层增加了信息密度,但也扭曲了图像。在着色网络中,我们将stride设置为2,使宽度和高度减少一半。这也增加了信息密度,但不会扭曲图像。

两种不同的差别是在采样层上,并且保持了图像的比例。分类网络只关心最后的分类。因此,当它通过网络时,它们会不断降低图像的大小和质量。
着色网络保持图像的比例。这是通过添加如上图所示的白色填充来完成的。否则,每个卷积层就会裁剪图像。它是用*padding='same'*参数完成的。
为了使图像的大小增加一倍,着色网络使用了一个上采样层。
这个for loop首先计算目录中的所有文件名。然后,它遍历图像目录,将图像转换为像素数组,并将它们组合成一个巨大的向量。
在ImageDataGenerator中,我们调整图像生成器的设置。这样,一幅图像就永远不会相同,从而提高了学习的效果。shear_range会将图像向左或向右倾斜。
我们使用Xtrain文件夹中的图像,然后基于上面的设置生成图像。然后我们为X_batch提取黑白层,并为这两种彩色层选择两种颜色。
GPU越强大,你就能得到越多的图像。有了这个设置,你可以使用50-100张图片。
给图像上色既是一个科学问题,也是一个艺术问题。以下是一些建议:
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/10/arrsss.mp4"][/video]
视频地址:https://www.youtube.com/watch?v=vubuBrcAwtY
在本文中,我将向你展示如何构建色彩化神经网络。第一部分分解了核心逻辑。我们将构建一个40行的神经网络作为一个名叫“Alpha”的彩色化机器人。下一步是创建一个可通用化的神经网络---Beta版本。我们将会给机器人上色,这是以前从未见过的。下面就开始我们的人工智能应用的深度实践吧!
核心逻辑
在本节中,我将概述如何呈现图像以及我们的神经网络的主要逻辑。
黑白图像可以用像素网格表示。每个像素都有一个对应其亮度的值。值的跨度从0到255,从黑色到白色。
彩色图像由三层组成:红色层,绿色层和蓝色层。想象一下,在白色的背景下,把一片绿色的叶子分成三个通道。直观地说,你可能会认为植物只存在于绿色的层中。
但是,正如你在下面的图中所看到的,这片树叶在所有三个通道中都存在。这些层不仅决定了颜色,还决定了亮度。
例如,为了实现白色,你需要对所有颜色进行相同的分布。通过增加等量的红色和蓝色,会使绿色变得更亮。因此,一种彩色图像可以用三个层来编码颜色和对比度:
就像黑白图像一样,彩色图像中的每一层都有一个介于0-255之间的值。0值表示在这一层没有颜色。如果所有彩色通道的值为0,那么图像像素是黑色的。正如你可能知道的,一个神经网络在输入值和输出值之间创建了一个关系。为了使我们的彩色化任务更精确,网络需要找到灰度图像与彩色图像之间相关联的特征。
总而言之,我们正在寻找灰度值网格与三种彩色网格相关的特性。
Alpha版本
我们首先要做一个简单的神经网络来给一个女人的脸涂上颜色。通过这种方式,你可以熟悉我们的模型的核心语法(syntax),因为我们为它添加了一些特性。
只需40行代码,我们就可以进行以下转换。中间的图片是用我们的神经网络做的,右边的图片是原始的彩色照片。这个网络是在同一个图像上进行训练和测试的——我们将在beta版本中回到这个问题上。
颜色空间
首先,我们将使用一种算法来改变颜色通道,从RGB到Lab。L代表亮度,而a和b代表色谱,分别为绿红和蓝黄。
如下图所示,一个Lab编码的图像有一层用于灰度,并将三层颜色分成两层。这意味着我们可以在最终的预测中使用原始的灰度图像。而且,我们只有两个渠道可以预测。
我们眼睛中94%的细胞决定了亮度。这使得我们只有6%的受体能够充当颜色的传感器。正如你在上面的图片中所看到的,灰度图像比彩色层要清晰得多。这是在我们最后的预测中保持灰度图像的另一个原因。
从黑白到彩色
我们的最终预测是看上去是这样的。我们有一个用于输入的灰度层,并且我们想要预测两个彩色层,Lab中的ab。为了创建最终的彩色图像,我们将包含我们用于输入的L/灰度图像,因此,需要创建一个Lab图像。
为了将一层变成两层,我们使用卷积滤波器。可以把它们看作是3D眼镜的蓝色/红色滤镜。每个滤波器决定了我们在图片中看到的东西。它们可以突出或移除一些东西来从图片中提取信息。网络可以从一个滤波器中创建一个新图像,或者将多个滤波器组合成一个图像。
对于卷积神经网络,每个滤波器都会自动调整,以帮助实现预期的结果。我们先把数百个滤波器堆叠起来,然后把它们分成两层,a层和b层。
在深入了解它的工作原理之前,让我们来运行代码。
部署FloydHub上的代码
如果你是FloyHub新手,请花费2分钟安装它,并观看下面的5分钟安装教程或者步骤指南。这是最好的(也是最简单的)在云GPUs上训练深度学习模式的方法。
- FloydHub安装地址:https://www.floydhub.com/
- 安装教程:https://www.youtube.com/watch?v=byLQ9kgjTdQ&t=6s
- 步骤指南:https://blog.floydhub.com/my-first-weekend-of-deep-learning/
Alpha版本
一旦安装了FloydHub,请使用以下命令:
git clone https://github.com/emilwallner/Coloring-greyscale-images-in-Keras
打开文件夹并启动FloyHub。
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornet
在你的浏览器中,FloydHub web仪表盘将会打开,并且你将会被提示创建一个名为“colornet”的全新的FloydHub项目。完成之后,返回到你的终端并运行相同的init命令。
floyd init colornet
好了,开始运行我们的工作:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
一些关于我们工作的简短的说明:
- 我们在FloydHub上安装了一个公共数据集(我已经上传)在
data目录--dataemilwallner/datasets/colornet/2:data。你可以在FloydHub通过浏览它来查看和使用该数据集(以及许多其他公共数据集) - 我们能够用Tensorboard--tensorboard
- 我们在Jupyter Notebook模式下运行这个工作-mode jupyter
- 你也可以添加GPU flag--gpu到你的命令中,这将使它的训练速度提高50倍
在FloydHub网站上,找到Jobs tab下到Jupyter notebook,点击Jupyter Notebook链接,然后前往到这个文件:floydhub/Alpha version/working_floyd_pink_light_full.ipynb。打开它,并在所有单元格上的点击shift+enter。
逐步增加epoch值,以了解神经网络是如何学习的。
model.fit(x=X, y=Y, batch_size=1, epochs=1)
从epoch值设置为1开始,然后增加到10,100,500,1000和3000。epoch值表示神经网络从图像中学习了多少次。一旦你训练了你的神经网络,你会发现图片img_result.png在主文件夹里。
# Get images
image = img_to_array(load_img('woman.png'))
image = np.array(image, dtype=float)
# Import map images into the lab colorspace
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
Y = Y / 128
X = X.reshape(1, 400, 400, 1)
Y = Y.reshape(1, 400, 400, 2)
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
# Building the neural network
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# Finish model
model.compile(optimizer='rmsprop',loss='mse')
#Train the neural network
model.fit(x=X, y=Y, batch_size=1, epochs=3000)
print(model.evaluate(X, Y, batch_size=1))
# Output colorizations
output = model.predict(X)
output = output * 128
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
imsave("img_result.png", lab2rgb(cur))
imsave("img_gray_scale.png", rgb2gray(lab2rgb(cur)))
用于运行这个网络的FloydHub命令:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技术的解释
概括地说,输入是一个表示黑白图像的网格。它输出两个带有彩色值的网格。在输入和输出值之间,我们创建滤波器将它们连接在一起,这是一个卷积神经网络。
训练网络时,我们使用彩色图像。我们将RGB彩色转换为Lab彩色空间。黑色层和白色层是我们的输入,两个彩色的层是输出。
在左边,我们有黑白的输入,滤波器和来自我们的神经网络的预测。
我们在相同的时间间隔内映射预测值和实际值。这样,我们就可以比较这些值了。区间从-1到1。为了映射预测值,我们使用了一个Tanh激活函数。对于任何你设定的Tanh函数的值,它都会返回-1到1之间。
真正的彩色值会到-128到128之间,这是Lab色彩空间的默认区间。除以128,它们也在-1到1的区间内。这使我们能够比较我们预测的误差。
在计算最终的错误之后,网络将更新滤波器以减少总体错误。网络将保持在这个循环(loop)中,直到错误尽可能地降到最低。
现在,让我们阐明一下代码片段中的一些语法(syntax)。
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
1.0/255表示我们使用的是一个24bit RGB色彩空间。这意味着我们在每个颜色通道上使用0-255个数字。这是标准的颜色规格,结果在1670万种颜色组合中。由于人类只能感知到200-1000万种颜色,所以使用更大的色彩空间是没有意义的。
Y = Y / 128
与RGB相比,Lab的色彩空间有不同的范围。Lab里的色谱范围从-128到128之间。通过将输出层中的所有值除以128,我们将把值强制在-1和1范围之间。我们将它与我们的神经网络相匹配,它也返回到-1和1之间的值。
在从rgb2lab()转换颜色空间后,我们选择灰度层:[ : , : , 0]。这是我们对神经网络的输入。[ : , : , 1: ]选择绿红色层和蓝黄色层。
在训练了神经网络之后,我们做了一个把它转换成图片的最终预测。
output = model.predict(X)
output = output * 128
在这里,我们使用一个灰度图像作为输入,并通过我们训练的神经网络来运行它。我们把所有的输出值都设置在-1和1之间,然后乘以128。这使我们在Lab色谱中得到了正确的颜色。
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
最后,我们通过填充0s的三个层创建了一个黑色RGB画布。然后我们从测试图像中复制灰度层。然后我们将两种彩色层添加到RGB画布上。然后将这些像素值转换为一个图像。
Beta版本
下面是使用我们的Beta版本对验证图像进行着色的结果。
我没有使用Imagenet,而是在FloydHub上创建了一个有更高质量图像的公共数据集。这些照片来自Unsplash,是由专业摄影师拍摄的,包括了9.5万张训练图片和500张验证图片。
FloydHub公共数据集:https://www.floydhub.com/emilwallner/datasets/colornet
特征提取器
我们的神经网络发现了将灰度图像与彩色图像相关联的特征。想象一下,你必须给黑白图像上色——但是限制一次只能看到9个像素。你可以扫描从左上角到右下角的每一个图像,并试着预测每个像素的颜色。
例如,上面这9个像素是一位女性的鼻孔边缘。正如你所能想象的那样,要做一个好的着色几乎是不可能的,所以你要把它分解成几个步骤。
首先,你需要寻找简单的模式:一条斜线,所有的黑色像素,等等。你在每个方块中寻找相同的模式,并且移除不匹配的像素。你可以从64个迷你滤镜中生成64张新图片。
如果再次扫描图像,你将看到你已经检测到的相同的小模式。为了获得对图像的更高层次的理解,你可以将图像的大小减少一半。
你仍然只有一个3x3的滤波器来扫描每个图像。但是通过将你的新的9个像素与你的较低级别的滤波器相结合,你可以发现更复杂的模式。一个像素的组合可能形成一个半圆,一个小点,或者一条直线。同样,你重复从图像中提取相同的模式。这一次,你将生成128个新过滤的图像。
经过几个步骤,你所生成的经过过滤的图像可能看起来是这样的:
如前所述,你从低级特性开始,例如一个边缘。更靠近输出的层被合并到模式中,然后进入各种细节,最后变成了一个面孔。
如果这很难理解,那就看这个下面视频教程吧。
视频地址:https://www.youtube.com/watch?v=AgkfIQ4IGaM
这个过程就像大多数处理视觉的神经网络一样,被称为卷积神经网络。卷积类似于“结合”这个词,你结合了几个经过过滤的图像来理解图像中的各种情景。
从特征提取到颜色
神经网络以一种不断尝试的方法运作。它首先对每个像素进行随机预测。基于每个像素的误差,它通过网络逆向工作来改进特征提取。
它开始对产生最大错误的情况进行调整。在这种情况下,是否着色并定位不同的对象,然后把所有的对象都变成棕色。棕色是最类似于其他颜色的颜色,因此产生了最小的误差。
因为大多数训练数据都很相似,所以网络很难区分不同的物体。它会调整不同色调的棕色,但不会产生更细微的颜色。
下面是beta版本的代码,后面是对代码的技术解释。
# Get images
X = []
for filename in os.listdir('../Train/'):
X.append(img_to_array(load_img('../Train/'+filename)))
X = np.array(X, dtype=float)
# Set up training and test data
split = int(0.95*len(X))
Xtrain = X[:split]
Xtrain = 1.0/255*Xtrain
#Design the neural network
model = Sequential()
model.add(InputLayer(input_shape=(256, 256, 1)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
model.add(UpSampling2D((2, 2)))
# Finish model
model.compile(optimizer='rmsprop', loss='mse')
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Generate training data
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
# Train model
TensorBoard(log_dir='/output')
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=10000, epochs=1)
# Test images
Xtest = rgb2lab(1.0/255*X[split:])[:,:,:,0]
Xtest = Xtest.reshape(Xtest.shape+(1,))
Ytest = rgb2lab(1.0/255*X[split:])[:,:,:,1:]
Ytest = Ytest / 128
print model.evaluate(Xtest, Ytest, batch_size=batch_size)
# Load black and white images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = rgb2lab(1.0/255*color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict(color_me)
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))
以下是用于运行beta神经网络的FloydHub命令:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技术的解释
与其他可视网络的主要区别是像素位置的重要性。在着色网络中,图像的大小或比率在整个网络中保持不变。在其他网络中,图像被扭曲得接近最后一层。
分类网络中的最大池化层增加了信息密度,但也扭曲了图像。在着色网络中,我们将stride设置为2,使宽度和高度减少一半。这也增加了信息密度,但不会扭曲图像。
两种不同的差别是在采样层上,并且保持了图像的比例。分类网络只关心最后的分类。因此,当它通过网络时,它们会不断降低图像的大小和质量。
着色网络保持图像的比例。这是通过添加如上图所示的白色填充来完成的。否则,每个卷积层就会裁剪图像。它是用*padding='same'*参数完成的。
为了使图像的大小增加一倍,着色网络使用了一个上采样层。
for filename in os.listdir('/Color_300/Train/'):
X.append(img_to_array(load_img('/Color_300/Test'+filename)))这个for loop首先计算目录中的所有文件名。然后,它遍历图像目录,将图像转换为像素数组,并将它们组合成一个巨大的向量。
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
在ImageDataGenerator中,我们调整图像生成器的设置。这样,一幅图像就永远不会相同,从而提高了学习的效果。shear_range会将图像向左或向右倾斜。
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
我们使用Xtrain文件夹中的图像,然后基于上面的设置生成图像。然后我们为X_batch提取黑白层,并为这两种彩色层选择两种颜色。
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)
GPU越强大,你就能得到越多的图像。有了这个设置,你可以使用50-100张图片。
steps_per_epoch是通过将训练图像的数量与你的批大小分开来计算的。例如,100个批大小为50的图像,相当于每个epoch就有两个step。epoch的数量决定了你想要训练所有的图像多少次。10000张21个epoch的图片将在一个Tesla K80 GPU上花费11个小时来训练。给图像上色既是一个科学问题,也是一个艺术问题。以下是一些建议:
- 用另一个预先训练过的模型来实现它。
- 用一个不同的数据集。
- 使网络能够以更多的图片来实现准确的增长。
- 在RGB色彩空间中建立一个放大器。创建一个与着色网络相似的模型,它将一个饱和的彩色图像作为输入,并将正确的彩色图像作为输出。
- 实现一个加权分类。
- 把它应用到视频中。不要过于担心色彩的变化,但要使图像之间的转换保持一致。你也可以通过对较小的图片做一些类似的事情。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消